大数据学习之十——MapReduce代码实例:数据去重和数据排序
Posted M_study
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据学习之十——MapReduce代码实例:数据去重和数据排序相关的知识,希望对你有一定的参考价值。
***数据去重***
目标:原始数据中出现次数超过一次的数据在输出文件中只出现一次。
算法思想:根据reduce的过程特性,会自动根据key来计算输入的value集合,把数据作为key输出给reduce,无论这个数据出现多少次,reduce最终结果中key只能输出一次。
1.实例中每个数据代表输入文件中的一行内容,map阶段采用Hadoop默认的作业输入方式。将value设置为key,并直接输出。 map输出数据的key为数据,将value设置成空值
2.在MapReduce流程中,map的输出<key,value>经过shuffle过程聚集成<key,value-list>后会交给reduce
3.reduce阶段不管每个key有多少个value,它直接将输入的key复制为输出的key,并输出(输出中的value被设置成空)。

代码实现:
public class testquchong {
static String INPUT_PATH="hdfs://master:9000/quchong"; //将文件file1和file2放在该目录下
static String OUTPUT_PATH="hdfs://master:9000/quchong/qc";
static class MyMapper extends Mapper<Object,Text,Text,Text>{ //将输入输出作为string类型,对应Text类型
private static Text line=new Text(); //每一行作为一个数据
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException{
line=value;
context.write(line,new Text(",")); //key是唯一的,作为数据,即实现去重
}
}
static class MyReduce extends Reducer<Text,Text,Text,Text>{
protected void reduce(Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{
context.write(key,new Text(" ")); //map传给reduce的数据已经做完数据去重,输出即可
}
}
public static void main(String[] args) throws Exception{
Path outputpath=new Path(OUTPUT_PATH);
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job,outputpath);
job.waitForCompletion(true);
}
}
***数据排序***
目标:实现多个文件中的数据进行从小到大的排序并输出
算法思想:MapReduce过程中就有排序,它的默认排序规则按照key值进行排序的,如果key为封装int的IntWritable类型,那么MapReduce按照数字大小对key排序,如果key为封装为String的Text类型,那么MapReduce按照字典顺序对字符串排序。
使用封装int的IntWritable型数据结构。也就是在map中将读入的数据转化成IntWritable型,然后作为key值输出(value任意)。reduce拿到<key,value-list>之后,将输入的key作为value输出,并根据value-list中元素的个数决定输出的次数。输出的key(即代码中的linenum)是一个全局变量,它统计当前key的位次。
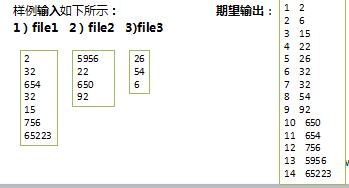
代码实现:
public class paixu {
static String INPUT_PATH="hdfs://master:9000/test";
static String OUTPUT_PATH="hdfs://master:9000/output/sort";
static class MyMapper extends Mapper<Object,Object,IntWritable,NullWritable>{ //选择为Int类型,value值任意
IntWritable output_key=new IntWritable();
NullWritable output_value=NullWritable.get();
protected void map(Object key, Object value, Context context) throws IOException, InterruptedException{
int val=Integer.parseUnsignedInt(value.toString().trim()); //进行数据类型转换
output_key.set(val);
context.write(output_key,output_value); //key值确定
}
}
static class MyReduce extends Reducer<IntWritable,NullWritable,IntWritable,IntWritable>{ //输入是map的输出,输出行号和数据为int
IntWritable output_key=new IntWritable();
int num=1;
protected void reduce(IntWritable key,Iterable<NullWritable> values,Context context) throws IOException,InterruptedException{
output_key.set(num++); //循环赋值作为行号
context.write(output_key,key); //key为map传入的数据
}
}
public static void main(String[] args) throws Exception{
Path outputpath=new Path(OUTPUT_PATH);
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job,outputpath);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setMapOutputKeyClass(IntWritable.class); //因为map和reduce的输出类型不一样
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
}
}
以上是关于大数据学习之十——MapReduce代码实例:数据去重和数据排序的主要内容,如果未能解决你的问题,请参考以下文章