HiveQL SELECT语句查询
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HiveQL SELECT语句查询相关的知识,希望对你有一定的参考价值。
参考技术A HIVE总是按照从左到右的顺序执行的。嵌套SELECT 语句会按照要求执行“下推”过程,在数据进行连接操作之前会先进行分区过滤。
SELECT 和WHERE 语句中不能引用到右边表中的字段。
select是SQL中的射影算子。From子句标识了从哪个表、视图、嵌套查询中选择记录。
SELECT:指定了要保存的列以及输出函数需要调用的一个或多个列。
比如例子一表stocks中选择symbol列和所有列名以price为前缀的列:
SELECT symbol,'price.*' FROM stocks;
用户不但可以选择表中的列,还可以使用函数调用和算术表达式操作列值。
employees表查询:
SELECT upper(name),salary,deductions["Federal Taxes"],round(salary * (1- deductions["Federal Taxes"])) FROM employees;
可以通过设置属性hive.map.aggr值为true来提高聚合的性能。
SET hive.map.aggr=ture;
查询employees表有多少员工,以及他们的平均薪水: SELECT count(*),avg(salary) FROM employees;
SELECT count(DISTINCT symbol) FROM stocks;
SELECT count(DISTINCT ymd),count(DISTINCT volume) FROM stocks;
与聚合函数相反就是表生成函数,其可以将单列扩展成多列或者多行。
典型的查询会返回多行数据,limit子句用于限制返回的函数。
列别名:返回一个由新列组成的新的关系。
SELECT name,salary,
CASE
WHEN salary <50000.0 THEN 'low'
WHEN salary >= 50000.0 AND salary < 70000.0 THEN 'middle'
WHEN salary >= 70000.0 AND salary < 100000.0 THEN 'high'
ELSE 'very high'
END AS bracket FROM employees;
SELECT *
FROM employees
WHERE coutry ='US' AND state='CA' LIMIT 100;`
SELECT *
FROM employees
WHERE address.street LIKE '%Ave.';
SELECT a.ymd,a. ,b.price_close
FROM stocks a JOIN stocks b
ON a.ymd=b.ymd
WHERE a.symbol='AAPL' AND b.symbol='IBM';
SELECT s.ymd,s.symbol,s.price_close,d.dividend
FROM stocks s LEFT OUTER JOIN dividends d ON s.ymd=d.ymd AND s.symbol=d.symbol
WHERE s.symbol = 'AAPL'
SELECT s.ymd,s.symbol,s.price_close,d.dividend
FROM stocks s RIGHT OUTER JOIN dividends d ON s.ymd=d.ymd AND s.symbol=d.symbol
WHERE s.symbol = 'AAPL'
SELECT s.ymd,s.symbol,s.price_close,d.dividend
FROM stocks s FULL OUTER JOIN dividends d ON s.ymd=d.ymd AND s.symbol=d.symbol
WHERE s.symbol = 'AAPL'
SELECT s.ymd,s.symbol,s.price_close
FROM stocks s
WHERE s.ymd,s.symbol IN (SELECT d.ymd,d.symbol FROM dividends d);
SELECT s.ymd,s.symbol,s.price_close
FROM stocks s LEFT SEMI JOIN dividends d
ON s.ymd=d.ymd AND s.symbol = d.symbol;
HiveQL数据查询基础
HiveQL数据查询基础
HiveQL数据查询语法
select语句
在所有数据库系统中,select语句是应用最广的,也是相对复杂的语句,它用于选取字段。同样,Hive中的select语句也是比较复杂的查询语句。
select */field1,field2... from tableName,
where语句
select语句用于选取字段,where语句则用于过滤条件,两者结合使用可以查找到符合过滤条件的记录。
group by语句
group by语句通常会和聚合函数一起使用,其语意为按照一个或者多个列对结果进行分组,然后使用聚合函数对每个组执行聚合运算。
having分组筛选
having子句允许用户通过一个简单的语法,来完成原本需要通过子查询才能对group by语句产生的分组结果进行条件过滤的任务。
order by语句和sort by语句
hive中order by语句和SQL中的定义是一样的,其会对查询结果集执行一次全局排序,也就是说会有 一个所有数据都通过reducer进行处理的过程。对于大数据集,这个过程可能会消耗太多时间。
Hive增加了一个可供选择的方式,那就是sort by语句,该语句只会在每个reducer中队数据排序,也就是说会执行一个局部排序,因此可以保证每个reducer的输出数据都是有序的(但并非全局有序),如此就可以提高后面进行全局排序的效率。
因此若在数据量级非常大的情况下排序,可以选择sort by语句,平时可以选择order by语句完成排序任务。
对于以上这两种排序语法,语法区别仅仅是:一个关键字是order,另一个关键字是sort。用户可以指定任意期望进行排序的字段,并可以在字段后面加上asc关键字(默认)按升序排序,或加desc关键字按降序排序。
HiveQL连接查询语句
HiveQL连接查询语句,顾名思义就是多表之间的连接查询语句。在传统的关系型数据库系统中,连接查询语句是非常常用的一种数据查询分析方法。Hive大数据平台数据仓库工具中也提供了丰富的连接查询语句,可以说是将传统的关系型数据库系统中用与连接查询的语句直接移植到了大数据平台Hive中,懂SQL语句的工程师可以直接操作Hive,不用再学习新的语言或者其他大数据平台的操作脚本语言,但HiveQL连接查询语句的底层计算引擎不再是单机运算,而变成了大数据平台分布式并行批处理框架MapReduce。
join连接语句
我们把Hive提供的这一套类SQL的连接查询语句称为HiveQL连接查询语句,其中包含了丰富的连接查询方式,如内连接、自然连接、外连接和自连接等。
创建数据库scott
create database if not exists scott;
use scott;
数据库scott中创建员工表emp
create external table scott.emp(empno varchar(50),ename varchar(30),job varchar(50),mgr varchar(30),sal double,deptno varchar(50))row format delimited fields terminated by ',' stored as textfile location '/scott/emp';

emp.csv
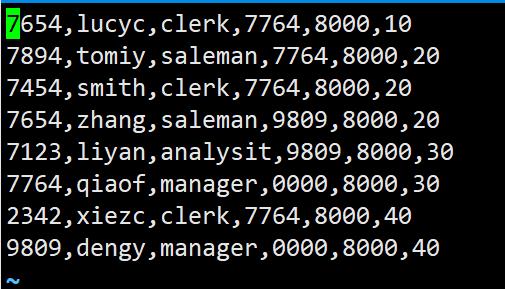
dfs -put /home/hadoop/emp.csv /scott/emp;
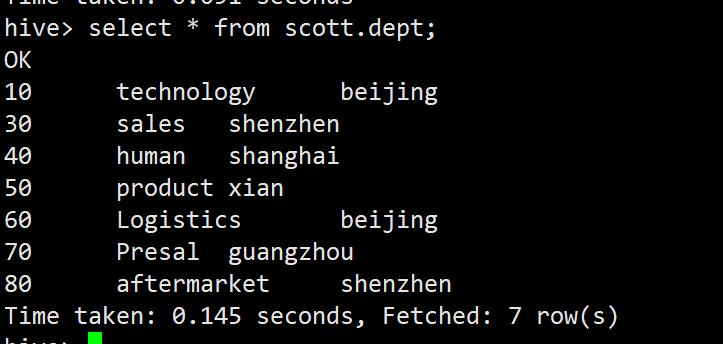
create external table scott.dept(deptno varchar(50),dname varchar(30),loc varchar(30)) row format delimited fields terminated by ',' stored as textfile location '/scott/dept';
dfs -put /home/hadoop/dept.csv /scott/dept;

内连接
也可以简写为join,只有进行连接的两个表中都存在与连接标准想匹配的数据才会被保留下来,内连接分为等值连接和不等值连接。
等值连接是指,在使用等号操作符的连接。
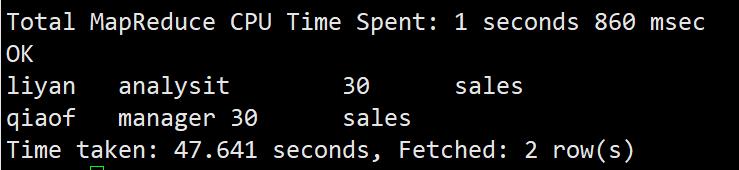
员工的姓名、职位存储在员工表emp中,部门的编号和部门名称存储在部门表dept中,所以我们需要对员工表emp和部门表dept做等值连接查询。因为在员工表中有一个字段是deptno,和dept部门表中的部门编号deptno是相等的,如此就筛选出我们想要的字段内容。
select emp.ename, emp.job, dept.deptno, dept.dname from emp inner join dept on emp.deptno=dept.deptno where dept.deptno=30;
不等值连接是指,使用>、>=、<=、<等
自然连接
自然连接是在广义笛卡尔积中选出同名属性上符合相等条件的元组,再进行投影,去掉重复的同名属性,组成新的关系。即自然连接是再两张表中寻找那些数据类型和列名都相同的字段,然后自动将它们连接起来,并返回所有符合条件的结果,它是通过对参与表关系中所有同名的属性对取等来完成的,故无需自己添加连接条件。自然连接与外连接的区别在于,对于无法匹配的记录,外连接会虚拟一条与之匹配的记录来保全连接表中的所有记录,但自然连接不会。
例如,我们想查询部门编号10和30的所有员工的姓名、职位和部门名称,这时就可以采用自然连接来对表emp和表dept进行连接查询,
select ename,job,dname from emp natural join dept where dept.deptno in ('10','30');
外连接
外连接分为左外连接查询、右外连接查询和全外连接。其中左外连接和右外连接再实际开发中会频繁使用
左外连接即以连接中的左表为主,返回左表的所有信息和右表中符合连接条件的信息,对于右表中不符合连接条件的侧补空值。
select e.empno,e.ename,e.job,d.deptno,d.dname,d.loc from emp e left outer join dept d on e.deptno=d.deptno;
右外连接即以连接中的右表为主,返回右表的所有信息和左表中符合连接条件的信息,对于左表中不符合连接条件的则补空值。
select e.empno,e.ename,e.job,d.deptno,d.dname,d.loc from emp e right outer join dept d on e.deptno=d.deptno;

全外连接
select e.*,d.* from emp e full outer join dept d on e.deptno=d.deptno;

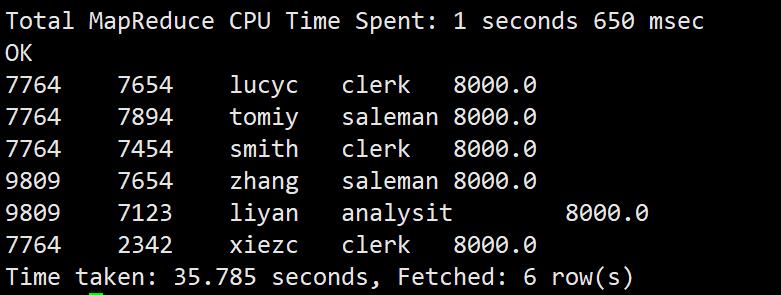
自连接
连接的表是同一张表,使用自连接可以将自身表的一个镜像当成另一个表来对待,所以自连接适用于表自己和自己的连接查询
select e1.empno,e2.empno,e2.ename,e2.job,e2.sal from emp e1,emp e2 where e1.empno=e2.mgr;
以上是关于HiveQL SELECT语句查询的主要内容,如果未能解决你的问题,请参考以下文章