PostgreSQL使用函数的多表关联视图在排序时的性能问题
Posted 闻歌感旧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PostgreSQL使用函数的多表关联视图在排序时的性能问题相关的知识,希望对你有一定的参考价值。
一、问题描述
近日PostgreSQL的某个表的记录数由万级增加到一百万级(设计能力是一亿)时,建立在该表之上的某个多表关联VIEW的查询性能急剧变慢(大约从10ms级跃升到100s级)。经分析查询计划,发现瓶颈在于排序用时很长;而排序用时的诱因是什么?在排除掉一个个其它因素后,发现是VIEW定义中使用了函数(非内部函数,特此说明)。在将自定义函数更改为等效的子查询或连接查询时,性能得到很好的改善。
因为实际的表、VIEW、函数都过于复杂,为描述及重现问题的关键,以下将表、VIEW、函数等都进行简化,。
二、测试对象
创建三个测试用表:
create table t1 ( id int not null primary key, name varchar(20) ); create table t2 ( id int not null primary key, name varchar(20) ); create table t3 ( id int not null primary key, name varchar(20) );
再创建函数、包含它的VIEW、作为对比的等效VIEW:
create or replace function f1(p_id in int) returns int as $$ declare v_name varchar(40); begin select name3 into v_name from t3 where id=p_id; if v_name is null then return 0; else return length(v_name); end if; end; $$ language plpgsql; create view v1 as select t1.id id, t1.name name1, t2.name name2, f1(t1.id) length from t1 left join t2 on t2.id=t1.id;
create view v2 as
select t1.id id, t1.name1 name1, t2.name2 name2,
coalesce(length(t3.name3), 0) length
from t1 left join t2 on t2.id=t1.id left join t3 on t3.id=t1.id;
最后向表t1插入8000条记录,id为1..8000,name的值则无所谓;再分别拷贝部分数据到表t2、t3:
insert into t2 select * from t1 where t1.id%2=0; insert into t3 select * from t1 where t1.id%3=0;
三、检查执行计划
完成所有准备工作后,检查在两个VIEW上排序查询的执行计划:
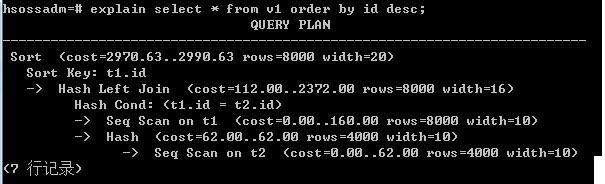
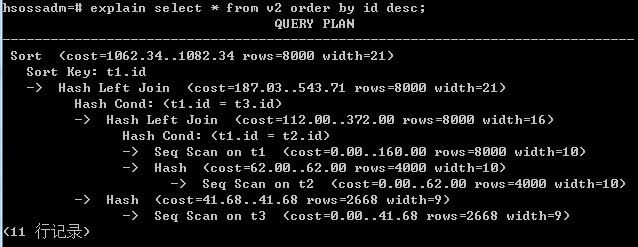
显然,排序用时是大头,而v1在排序上的用时差不多是v2的3倍。
再进一步测试,如果加上limit ... offset(常跟order by一起用于分页),两个VIEW的差距更加明显:
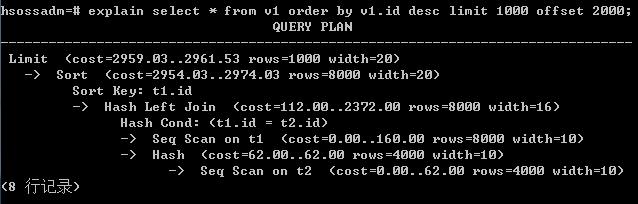
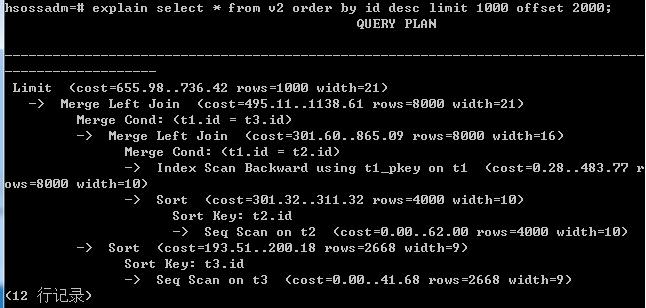
如果去掉排序操作,v1的查询用时也会多于v2,但相比之前少差不多一个数量级。限于篇幅,这里不贴图了。
本次测试的记录数还不到万级,已经可以看出两种VIEW的差距,有兴趣的同行可以自行验证表记录数在十万级及更多以上的情况。
四、结论
根据本次简单测试,并结合实践中的情况(抱歉不能给出详情),得出以下结论:
- PostgreSQL中,如果多表关联VIEW中包使用了函数,尽量修改为子查询或连接查询;
- 对于排序操作,含函数的VIEW的性能远低于等效的子查询或连接查询的VIEW,如再含有分页操作,两者的性能差距更大;
- 实践中,当主表记录数达到一定数量(临界值未知),含函数的VIEW的排序甚至无法利用索引而走全表扫描,从而引发用时剧增;
- 以前的实践中,Oracle中两种VIEW的差别并不是十分明显。
以上是关于PostgreSQL使用函数的多表关联视图在排序时的性能问题的主要内容,如果未能解决你的问题,请参考以下文章