深入了解oracle存储过程的优缺点
Posted 郭大侠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入了解oracle存储过程的优缺点相关的知识,希望对你有一定的参考价值。
定义:
存储过程(Stored Procedure )是一组为了完成特定功能的SQL 语句集,经编译后存储在数据库中。用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象,任何一个设计良好的数据库应用程序都应该用到存储过程。 存储过程是由流控制和SQL 语句书写的过程,这个过程经编译和优化后存储在数据库服务器中,应用程序使用时只要调用即可。在Oracle 中,若干个有联系的过程可以组合在一起构成程序包。
优 点:
1.存储过程可以使得程序执行效率更高、安全性更好,因为过程建立之后 已经编译并且储存到数据库,直接写sql就需要先分析再执行因此过程效率更高,直接写sql语句会带来安全性问题,如:sql注入 。存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
2.建立过程不会很耗系统资源,因为过程只是在调用才执行。
3.存储过程可以用于降低网络流量,存储过程代码直接存储于数据库中,所以不会产生大量T-sql语句的代码流量。
4.使用存储过程使您能够增强对执行计划的重复使用,由此可以通过使用远程过程调用 (RPC) 处理服务器上的存储过程而提高性能。RPC 封装参数和调用服务器端过程的方式使引擎能够轻松地找到匹配的执行计划,并只需插入更新的参数值。
5.可维护性高,更新存储过程通常比更改、测试以及重新部署程序集需要较少的时间和精力。
6.代码精简一致,一个存储过程可以用于应用程序代码的不同位置。
7.增强安全性:
a、通过向用户授予对存储过程(而不是基于表)的访问权限,它们可以提供对特定数据的访问;
b、提高代码安全,防止 SQL注入(但未彻底解决,例如,将数据操作语言--DML,附加到输入参数);
c、SqlParameter 类指定存储过程参数的数据类型,作为深层次防御性策略的一部分,可以验证用户提供的值类型(但也不是万无一失,还是应该传递至数据库前得到附加验证)。
- 可以封装数据逻辑和业务规则,以便用户可以仅通过开发人员和数据库管理员打算使用的方式访问数据和对象。
- 验证所有用户输入的参数化存储过程可用于阻止 SQL 注入攻击。 如果使用动态 SQL,请确保将命令参数化,并绝对不能将参数值直接包括在查询字符串中。
- 可禁止即席查询和数据修改。 这样将阻止用户恶意或无意中损坏数据或执行查询,以避免降低服务器或网络的性能。
- 可以在过程代码中处理错误,而无需将错误直接传递给客户端应用程序。 这样可防止返回错误消息,以避免其可能有助于探测攻击。 在服务器上记录错误并对其进行处理。
- 存储过程只能编写一次,可由很多应用程序访问。
- 客户端应用程序不需要知道有关基础数据结构的任何信息。 只要更改不影响参数列表或返回的数据类型,就可以更改存储过程代码,而无需在客户端应用程序中进行更改。
- 存储过程可通过将多个操作组合到一个过程调用中来减少网络通讯。
- 安全性好—可以访问执行存储过程而不必拥有直接操作基础表的权限
- 减少网络通信流—存储过程可以包含多条SQL语句,但只要用一条语句来执行该存储过程,从而减少了客户端应用程序对服务器的调用次数和长度
- 快速执行—存储过程在第一次执行时进行语法检查和编译,编译好的版本存储在高速缓存中,用于再次调用
- 保证一致性—如果用户只通过存储过程修改数据,则可以消除偶然修改带来的问题减少操作人员和编程人员的错误—由于传递信息少,因此执行复杂任务更容易,不易出现SQL错误
缺点:
借用SQL SERVER的存储过程示意图来表达一下,理解一下概念就好,具体到Oracle请另行查询
存储过程的运行示意图如下:

首先运行CREATE PROC过程。这回解析查询以确保会实际运行这些代码。它与直接运行脚本的区别在于CREATE PROC命令可以利用所谓的延迟名称解析。延迟名称解析可以忽略一些对象还不存在的事实。
在创建了存储过程后,它将等待第一次执行。在那时,存储过程被优化,而查询计划被编译并且缓存到系统上。后续几次运行该存储过程时,除非通过使用WITH RECOMPILE选项指定,否则都会使用缓存的查询计划而不是创建一个新的查询计划。这意味着每次使用该存储过程时,存储过程都会跳过很多优化和编译工作。节省的确切时间取决于批处理的复杂性,批处理中表的大小,以及每个表上索引的数量。通常,节省的时间不是很多。但对于大多数场景来说可能是1秒或更少-但通过百分比可以计算出此区别(1秒比2秒快了100%)。当需要进行多次调用时或针对循环的情况,这一区别会变得更明显。
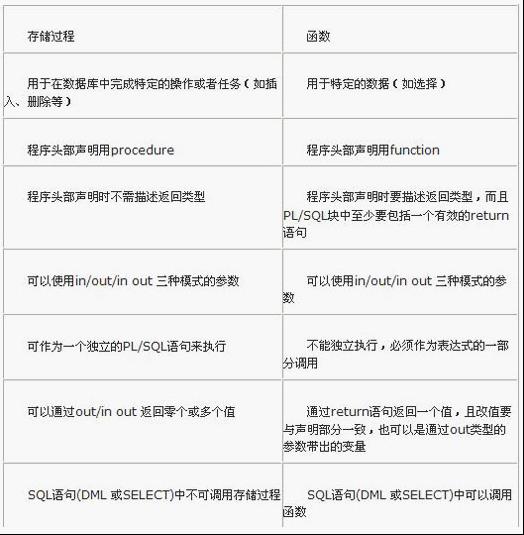
存储过程与函数的对比
以上是关于深入了解oracle存储过程的优缺点的主要内容,如果未能解决你的问题,请参考以下文章