hadoop的核心组件:hdfs(分布式文件系统)、mapreduce(分布式计算框架)、Hive(基于hadoop的数据仓库)、HBase(分布式列存数据库)、Zookeeper(分布式协作服务)、Sqoop(数据同步工具)和Flume(日志手机工具)
hdfs(分布式文件系统):
由client、NameNode、DataNode组成
- client负责切分文件,并与NameNode交互,获取文件位置;与DataNode交互,读取和写入数据
- NameNode是Master节点,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求
- DataNode是Slave节点,存储实际数据,汇报存储信息给NameNode
- DataNode与NameNode保持心跳,提交block列表
在hadoop1.x的时候还有Secondary NameNode,负责辅助NameNode,分担其工作量;定期合并fsimage和fsedits,推送给NameNode;紧急情况下,可辅助恢复NameNode
存储模型
(1)文件线性切割成Block offset
(2)Block分散存储在集群节点中,Block是HDFS的基本存储单元,默认大小是64M
(3)单一文件Block大小一致,文件与文件可以不一致
(4)Block可设置副本数(小于节点数),分散在不同节点
(5)文件上传可以设置Block大小和副本数
(6)已上传的文件Block副本数可以调整,大小不变
(7)只支持一次写入多次读取,同一时刻只有一个写入者
(8)可以append追加数据
架构模型
(1)NameNode节点保存文件元数据
(2)DataNode节点保存文件Block数据
(3)DataNode与NameNode保持心跳,提交Block列表
(4)HdfsClient与NameNode交互元数据信息
(5)HdfsClient与DataNode交互文件Block数据
hdfs结构
一、NameNode(不会与磁盘发生交换)
(1)基于内存存储
- 只存在内存中
- 持久化
- 启动后, 元数据(metadate)信息加载到内存
- metadata的磁盘文件名为”fsimage”
- Block的位置信息不会保存到fsimage
- (journalNode的作用是存放EditLog的)edits记录对metadata的操作日志
(2)功能
- 接收客户端读写
- 收集DataNode汇报的block列表信息
(3) metadata
- 文件ownership, permissions(文件所有权、权限)
- 文件大小, 时间
- (block列表,block偏移量)--->会持久化, 位置信息--->不会持久化(启动时候由DataNode汇报过来)
- block每个副本位置(dataNode上报)
二、DataNode
(1)本地文件形式存储block
(2)存储Block的元数据信息文件
(3)启动DN时会向NN汇报block信息
(4)通过向NameNode发送心跳(3秒一次),如果NameNode 10分钟没有收到,则认为已经lost,并copy其上的block到其它DN
三、SecondaryNameNode/Qurom Journal Manager
合并时机
fs.checkpoint.period 3600s
fs.checkpoint.size 64MB
四、ZooKeeper Failover Controller(HDFS 2.0 HA)
(1)监控NameNode健康状态
(2)向Zookeeper注册NameNode
(3)NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC 锁的NameNode变为active
5、Block副本放置位置
(1)第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点
(2)第二个副本:放置在于第一个副本不同的机架的节点上
(3)第三个副本:与第二个副本相同机架的节点
(4)更多副本:随机节点
6、安全模式
(1)NameNode启动, fsimage载入内存, 执行edits
(2)成功建立元数据映射后, 创建新的fsimage文件(无需SNN)和空的edits
(3)检查副本数, 数量正常后,过若干时间, 解除安全模式
7、优缺点
优点:
高容错性(多副本, 自动恢复)
适合批处理(计算移动, 数据位置暴露给计算框架(block))
适合大数据处理(GB TB PB级数据)
可构建在廉价机器上
高吞吐
缺点:
高延迟
小文件存取(占用namenode内存, 寻道时间超过读取时间)
并发写入、文件随机修改(一个文件一个写入者, 只能append)
hdfs写流程
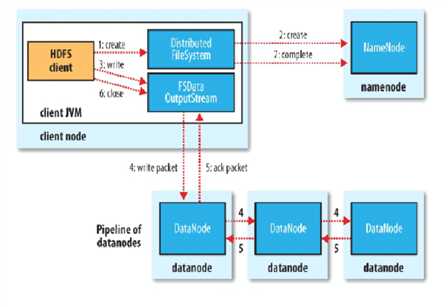
client切分文件与NanmeNode交互,获取DataNode列表,验证DataNode后连接DataNode,各节点之间两两交互,确定可用后,client以更小单位流式传输数据;
Block传输数据结束后,DataNode向NameNode汇报Block信息,DataNode向Client汇报完成,Client向NameNode汇报完成,获取去下一个Block存放的DataNode列表,
循环以上步骤,最终client汇报完成,NameNode会在写流程更新文件状态。
hdfs读流程
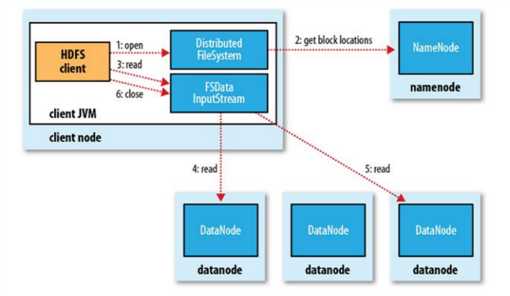
client与NameNode交互,获取Block存放的DataNode列表(Block副本的位置信息),线性和DataNode交互,获取Block,最终合并为一个文件,其中,在Block副本列表中按距离择优选取DataNode节点获取Block块。
mapreduce(分布式计算框架)
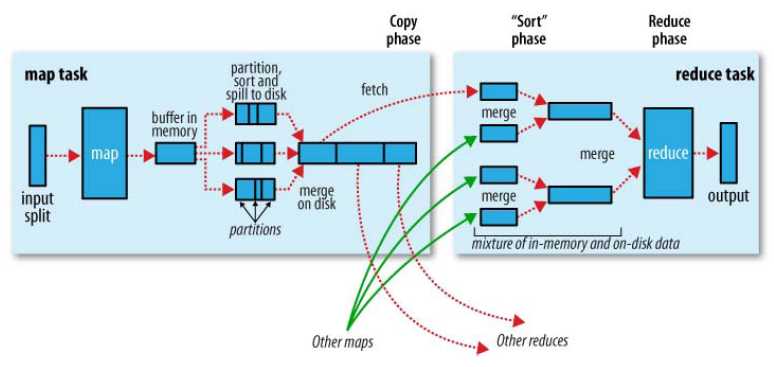
MR运行原理:
1、客户端提交作业之前,检查输入输出路径,首先创建切片列表
反射出作业中设置的input对象,默认是TextInputFormat类
通过input类得到切片列表(getSpilits()方法)
最小值 minSize 默认为1,如果设置就取设置的值
最大值 maxSize 默认为long的最大值
根据输入路径取出文件,获取每个文件的所有block列表,接着创建splits列表(包含文件名,偏移量,长度和位置信息)
切片大小根据最大最小值取,默认为block的大小
一个split对应一个map
提交作业到集群(submitJob()方法)
2、mapInput:
input.initialize 输入初始化
拿到taskContext(上下文)
创建mapper(默认为Mapper类,一般取用户设置的)
获取InputFomat类(输入格式化的类)
获取split
根据以上信息创建input(NewTrackingRecordReader)
input初始化
获取split的开始和结束位置和文件,开启对文件的IO流,将起始偏移量个IO设置一下
如果不是第一个切片(split),每次读取放弃第一行(跳过第一行数据),只有第一个切片才会读取第一行数据
mapper.run
3、output:
MapOutputBuffer初始化
环形缓冲区的阈值0.8、大小(100M) 默认值
sorter :QuickSort算法
反射获取比较器 OutputKeyComparator
排序,溢写,一些一次触发一次combiner
溢写达到3次的时候还会触发一次combiner
通过反射获取Partitioner类,默认为HashPartitoner
write(k,v)
collector.collect(key,value,partition)
output.close()
merger
如果numSplits<minSpillsForCombiner 判断溢写的次数是不是小于设置的合并的溢写次数(默认是3),成立的话combiner
4、reduce:
shuffle:copy
sort:SecondarySort
reduce
1、mapreduce shuffle
(1)maptask的输入是hdfs上的block块,maptask只读取split,block与split的对应关系默认是一对一
(2)进过map端的运行后,输出的格式为key/value,Mapreduce提供接口partition,他的作用是根据maptask输出的key hash后与reduce数量取模,
来决定当前的输出对应到哪个reduce处理,也可以自定义partition
(3)map运行后的数据序列化到缓冲区,默认这个缓冲区大小为100M,作用是收集这个map的结果,当数据达到溢写比例(默认是spill.percent=0.8)后,所定这80M的内存,
对这80M内存中的key做排序(sort),maptask的输出结果还可以往剩下的20M内存中写,互不影响。之后执行溢写的线程会往磁盘中写数据。每次溢写都会产生一个溢写小文件,
map执行完后,会合并这些溢写小文件,这个过程叫Merge。
(4)如果客户端设置了Combiner,那么会优化MapReduce的中间结果,合并map端的数据(相当于reduce端的预处理),Combiner不能改变最终的计算结果。
(5)reduce在执行之前就是从各个maptask执行完后的溢写文件中拿到所对应的数据,然后做合并(Merge),最终形成的文件作为reduce的输入文件,这个过程是归并排序。
最后就是reduce计算,把结果放到hdfs上面。
hdfs参数调优
| io.file.buffer.size:4096 (core-default.xml) | SequenceFiles在读写中可以使用缓存大小,可减少I/O次数;在大型Hadoop cluster,建议可设定为65536-131072 |
| dfs.blockes:134217728( hdfs-default.xml ) | hdfs中一个文件的Block块的大小,CDH5中默认为128M;设置太大影响map同时计算的数量,设置较少会浪费map个数资源 |
| mapred.reduce.tasks(mapreduce.job.reduces):1 | 默认启动的reduce数 |
| mapreduce.task.io.sort.factor:10 | reduce task中合并文件时,一次合并的文件数据 |
| mapred.child.java.opts:-Xmx200m | jvm启动子线程可以使用的最大内存 |
| mapred.reduce.parallel.copies:5 | Reduce copy数据的线程数量,默认值是5 |
| mapreduce.tasktracker.http.threads:40 | map和reduce是通过http进行传输的,这个设置传输的并行线程数 |
| mapreduce.map.output.compress:flase | map输出是否进行压缩,如果压缩就会多耗cpu,但是减少传输时间,如果不压缩,就需要较多的传输带宽。配合 mapreduce.map.output.compress.codec使用,默认是 org.apache.hadoop.io.compress.DefaultCodec,可以根据需要设定数据压缩方式。 |
| mapreduce.tasktracker.tasks.reduce.maximum:2 | 一个tasktracker并发执行的reduce数,建议为cpu核数 |
| mapreduce.map.sort.spill.percent:0.8 | 溢写比例 |
| min.num.spill.for.combine:3 | spill的文件达到设置的参数进行combiner |
避免推测执行
| mapred.map.tasks.speculative.execution=true |
| mapred.reduce.tasks.speculative.execution=true |
自定义partition
适当添加combiner
自定义reduce端的grouping Comparator
- mapred.reduce.tasks:手动设置reduce个数
- mapreduce.map.output.compress:map输出结果是否压缩
- mapreduce.map.output.compress.codec
- mapreduce.output.fileoutputformat.compress:job输出结果是否压缩
- mapreduce.output.fileoutputformat.compress.type
- mapreduce.output.fileoutputformat.compress.codec
9、调优文件以及参数
一、调优的目的
充分的利用机器的性能,更快的完成mr程序的计算任务。甚至是在有限的机器条件下,能够支持运行足够多的mr程序。
二、调优的总体概述
从mr程序的内部运行机制,我们可以了解到一个mr程序由mapper和reducer两个阶段组成,其中mapper阶段包括数据的读取、map处理以及写出操作(排序和合并/sort&merge),而reducer阶段包含mapper输出数据的获取、数据合并(sort&merge)、reduce处理以及写出操作。那么在这七个子阶段中,能够进行较大力度的进行调优的就是map输出、reducer数据合并以及reducer个数这三个方面的调优操作。也就是说虽然性能调优包括cpu、内存、磁盘io以及网络这四个大方面,但是从mr程序的执行流程中,我们可以知道主要有调优的是内存、磁盘io以及网络。在mr程序中调优,主要考虑的就是减少网络传输和减少磁盘IO操作,故本次课程的mr调优主要包括服务器调优、代码调优、mapper调优、reducer调优以及runner调优这五个方面。
三、服务器调优
服务器调优主要包括服务器参数调优和jvm调优。在本次项目中,由于我们使用hbase作为我们分析数据的原始数据存储表,所以对于hbase我们也需要进行一些调优操作。除了参数调优之外,和其他一般的java程序一样,还需要进行一些jvm调优。
hdfs调优
1. dfs.datanode.failed.volumes.tolerated: 允许发生磁盘错误的磁盘数量,默认为0,表示不允许datanode发生磁盘异常。当挂载多个磁盘的时候,可以修改该值。
2. dfs.replication: 复制因子,默认3
3. dfs.namenode.handler.count: namenode节点并发线程量,默认10
4. dfs.datanode.handler.count:datanode之间的并发线程量,默认10。
5. dfs.datanode.max.transfer.threads:datanode提供的数据流操作的并发线程量,默认4096。
一般将其设置为linux系统的文件句柄数的85%~90%之间,查看文件句柄数语句ulimit -a,修改vim /etc/security/limits.conf, 不能设置太大文件末尾,添加
* soft nofile 65535
* hard nofile 65535
注意:句柄数不能够太大,可以设置为1000000以下的所有数值,一般不设置为-1。
异常处理:当设置句柄数较大的时候,重新登录可能出现unable load session的提示信息,这个时候采用单用户模式进行修改操作即可。
单用户模式:
启动的时候按‘a‘键,进入选择界面,然后按‘e‘键进入kernel修改界面,然后选择第二行‘kernel...‘,按‘e‘键进行修改,在最后添加空格+single即可,按回车键回到修改界面,最后按‘b‘键进行单用户模式启动,当启动成功后,还原文件后保存,最后退出(exit)重启系统即可。
6. io.file.buffer.size: 读取/写出数据的buffer大小,默认4096,一般不用设置,推荐设置为4096的整数倍(物理页面的整数倍大小)。
mapreduce调优
1. mapreduce.task.io.sort.factor: mr程序进行合并排序的时候,打开的文件数量,默认为10个.
2. mapreduce.task.io.sort.mb: mr程序进行合并排序操作的时候或者mapper写数据的时候,内存大小,默认100M
3. mapreduce.map.sort.spill.percent: mr程序进行flush操作的阀值,默认0.80。
4. mapreduce.reduce.shuffle.parallelcopies:mr程序reducer copy数据的线程数,默认5。
5. mapreduce.reduce.shuffle.input.buffer.percent: reduce复制map数据的时候指定的内存堆大小百分比,默认为0.70,适当的增加该值可以减少map数据的磁盘溢出,能够提高系统性能。
6. mapreduce.reduce.shuffle.merge.percent:reduce进行shuffle的时候,用于启动合并输出和磁盘溢写的过程的阀值,默认为0.66。如果允许,适当增大其比例能够减少磁盘溢写次数,提高系统性能。同mapreduce.reduce.shuffle.input.buffer.percent一起使用。
7. mapreduce.task.timeout:mr程序的task执行情况汇报过期时间,默认600000(10分钟),设置为0表示不进行该值的判断。
四、代码调优
代码调优,主要是mapper和reducer中,针对多次创建的对象,进行代码提出操作。这个和一般的java程序的代码调优一样。
五、mapper调优
mapper调优主要就是就一个目标:减少输出量。我们可以通过增加combine阶段以及对输出进行压缩设置进行mapper调优。
combine介绍:
实现自定义combine要求继承reducer类,特点:
以map的输出key/value键值对作为输入输出键值对,作用是减少网络输出,在map节点上就合并一部分数据。
比较适合,map的输出是数值型的,方便进行统计。
压缩设置:
在提交job的时候分别设置启动压缩和指定压缩方式。
六、reducer调优
reducer调优主要是通过参数调优和设置reducer的个数来完成。
reducer个数调优:
要求:一个reducer和多个reducer的执行结果一致,不能因为多个reducer导致执行结果异常。
规则:一般要求在hadoop集群中的执行mr程序,map执行完成100%后,尽量早的看到reducer执行到33%,可以通过命令hadoop job -status job_id或者web页面来查看。
原因: map的执行process数是通过inputformat返回recordread来定义的;而reducer是有三部分构成的,分别为读取mapper输出数据、合并所有输出数据以及reduce处理,其中第一步要依赖map的执行,所以在数据量比较大的情况下,一个reducer无法满足性能要求的情况下,我们可以通过调高reducer的个数来解决该问题。
优点:充分利用集群的优势。
缺点:有些mr程序没法利用多reducer的优点,比如获取top n的mr程序。
七、runner调优
runner调优其实就是在提交job的时候设置job参数,一般都可以通过代码和xml文件两种方式进行设置。
1~8详见ActiveUserRunner(before和configure方法),9详解TransformerBaseRunner(initScans方法)
1. mapred.child.java.opts: 修改childyard进程执行的jvm参数,针对map和reducer均有效,默认:-Xmx200m
2. mapreduce.map.java.opts: 需改map阶段的childyard进程执行jvm参数,默认为空,当为空的时候,使用mapred.child.java.opts。
3. mapreduce.reduce.java.opts:修改reducer阶段的childyard进程执行jvm参数,默认为空,当为空的时候,使用mapred.child.java.opts。
4. mapreduce.job.reduces: 修改reducer的个数,默认为1。可以通过job.setNumReduceTasks方法来进行更改。
5. mapreduce.map.speculative:是否启动map阶段的推测执行,默认为true。其实一般情况设置为false比较好。可通过方法job.setMapSpeculativeExecution来设置。
6. mapreduce.reduce.speculative:是否需要启动reduce阶段的推测执行,默认为true,其实一般情况设置为fase比较好。可通过方法job.setReduceSpeculativeExecution来设置。
7. mapreduce.map.output.compress:设置是否启动map输出的压缩机制,默认为false。在需要减少网络传输的时候,可以设置为true。
8. mapreduce.map.output.compress.codec:设置map输出压缩机制,默认为org.apache.hadoop.io.compress.DefaultCodec,推荐使用SnappyCodec(在之前版本中需要进行安装操作,现在版本不太清楚,安装参数:http://www.cnblogs.com/chengxin1982/p/3862309.html)
9. hbase参数设置
由于hbase默认是一条一条数据拿取的,在mapper节点上执行的时候是每处理一条数据后就从hbase中获取下一条数据,通过设置cache值可以一次获取多条数据,减少网络数据传输。
源码:
1、设置map端的数量:mapreduce.input.fileinputformat.split.minsize
位置FileInputFormat.getSplits()方法
(1)输入文件size巨大,但不是小文件
减小map的数量:增大mapred.min.split.size的值
(2)输入文件数量巨大,且都是小文件
使用FileInputFormat衍生的CombineFileInputFormat将多个input path合并成一个InputSplit送给mapper处理,从而减少mapper的数量
2、增加Map-Reduce job 启动时创建的Mapper数量
可以通过减小每个mapper的输入做到,即减小blockSize或者减小mapred.min.split.size的值,设置blockSize一般不可行