把日志从log4j转换成logback的经历
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了把日志从log4j转换成logback的经历相关的知识,希望对你有一定的参考价值。
参考技术A
既然log4j1.x出问题了,之前用logback的时候又觉得挺爽了,那么就抓紧换吧,老规矩,方案先行。经过一番调查研究,制定如下战略:
对上面的几个jar解释下:
这个可以通过idea的maven插件的Show Dependencies功能查看有那些包依赖了log4j,然后一一配置exclusion。maven本身没有全局排除的功能,这个确实比较郁闷。另外发现有神人说可以通过在私服上发布一个空的相同groupId+artifactId的jar来替换掉这些依赖,个人感觉还是有点难以接受,感兴趣的同学可以去试试。
步骤同上一步;
具体配置的内容就不贴了,有兴趣的看 官方文档 。这里面关于logger的配置特别说明一下,在网上看到很多示例配置都是错的。
logger的additivity如果设置成false的话(默认是true),那么一定要给logger加上appender,否则符合该规则的日志都不会输出。
使用该插件后,在编译的时候就会检查是否有log4j和common-logging的包被依赖了,如果有则编译会不通过(虽然不能做全局的排除,但是好歹做个全局检查吧 -_-!!!)。
但这里也有个不爽的地方,父子项目是不能继承的,每个项目都需要设置;
分布式中采用Logback的MDC机制与AOP切面结合串联日志

在实际开发中,打印日志是十分重要的。在生产环境中,如果日志打得好可以快速地排查问题,而在分布式的场景下,一个请求会跨越多个节点,既一个业务可能需要多个节点协调配合处理。那么日志将会分散,而为了更好的查看日志,我们需要将它们串联起来,这样便会使排查问题变得更佳轻松。

举例一个简单分布式场景下使用串联日志的例子。场景如下:一笔支付请求从产品系统发起,期间经历了核心系统和网关系统最后调用银行系统实现资金划转,并逐步响应结果直到回到产品系统。这里暂且把整个支付流程看作是同步的,当这笔交易在生产环境中因其中某一环境出现异常时,我们需查看日志进行排查,而这笔交易因为流经多个系统,所以日志是分散的。这时候如果有一个唯一标识且能把所有日志串联起来那么将会方便和提高问题排查的效率。

串联的核心要点是把ID做为一个请求必传参数。常见如采用手动打印日志,既在各个接口服务内多处加上logger打印,打印内容里加上串联ID,如:

但是,还有另一种更简便的打印方式,既是MDC ( Mapped Diagnostic Contexts ) + AOP切面结合。MDC它是一个线程安全的存放诊断日志的容器。在处理请求前将请求的唯一标示放到MDC容器中,这个唯一标示会随着日志一起输出,以此来区分该条日志是属于那个请求的。并在请求处理完成之后清除MDC容器。

使用Logback的MDC机制,需要在logback.xml日志模板中进行一些设置,在logback.xml中,通过使用 %X{ }来占位,替换到对应的MDC中key的值。MDC容器的key可以多次赋值,每一次赋值会覆盖上一次的值。
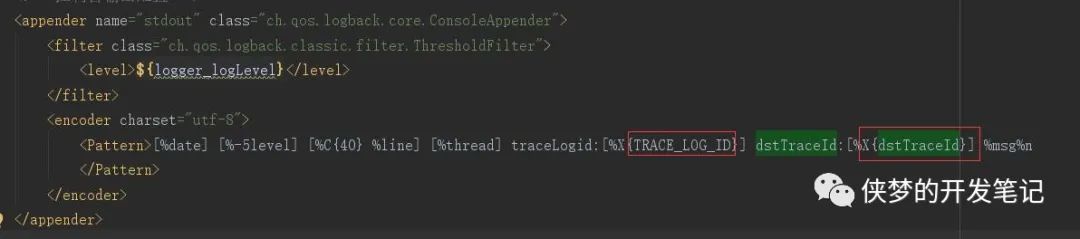
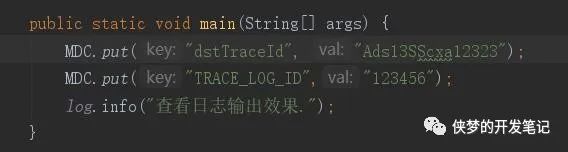
往MDC容器中put入键值对,在日志打印时,日志会按照我们预先在logback.xml中的格式输出,而其中占位符会替换上MDC中对应key的value值。打印结果如下:

如编写一个切面,被调用的服务在执行操作前,切面会将关键信息输出日志并同时将串联ID put到容器中,使其能在接下来同一线程内输出的日志中都包含该串联ID信息,在将日志串联起来的同时也方便了日志的打印。
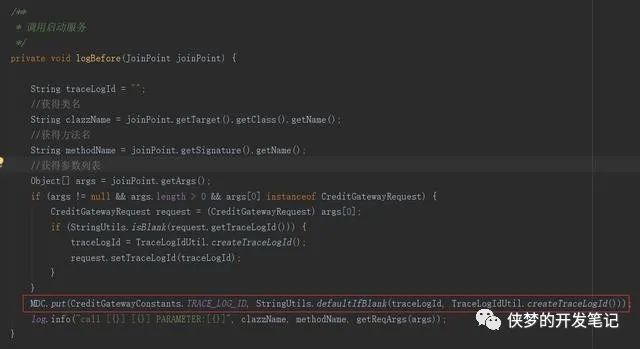
除了自定义切面外,Logback也提供了一个过滤器MDCInsertingServletFilter,感兴趣的朋友可以去详细了解下。
这里要特别要注意一点的是在主线程上,新起一个子线程,并由 java.util.concurrent.Executors来执行它时,在早期的版本中子线程可以直接自动继承父线程的MDC容器中的内容,因为MDC在早期版本中使用的是InheritableThreadLocal来作为底层实现。但是由于性能问题被取消了,最后还是使用的是ThreadLocal来作为底层实现。这样子线程就不能直接继承父线程的MDC容器。
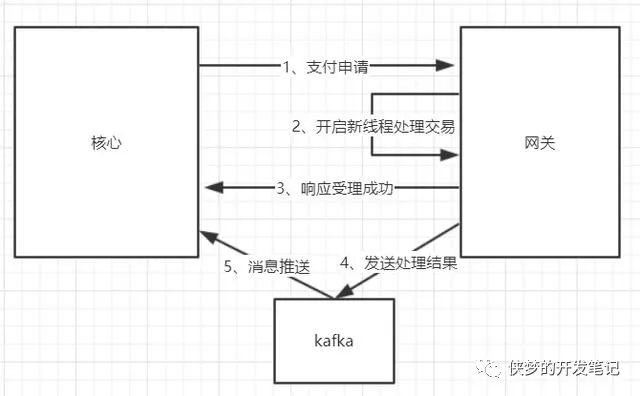
例如:支付操作为异步时,网关接收了核心的支付请求后会新开一个线程去处理支付请求,并响应回核心受理成功(注意:这里受理代表接收到支付的请求,而不代表处理成功)。那这样做就会导致新的子线程MDC并没有继承父线程中的东西,导致响应结果时缺失串联ID信息,不能与支付请求关联起来。
根据以上问题,Logback官方建议父线程新建子线程之前调用MDC.getCopyOfContextMap()方法将MDC内容取出来传给子线程,子线程在执行操作前先调用MDC.setContextMap()方法将父线程的MDC内容设置到子线程。
以上就是分布式场景下一种较为不错的日志打印方式,通过结合AOP切面与Logback的MDC机制将多个系统间有关联的日志串联起来,有助于问题的排查及信息的查看。如果有其他不错的日志打印方式也欢迎提出,共同讨论学习。
以上是关于把日志从log4j转换成logback的经历的主要内容,如果未能解决你的问题,请参考以下文章
log4j+slf4j管理日志项目迁移logback+slf4j
logback替换成log4j
logback解析——Appender
将spark默认日志log4j替换为logback
从 log4j 迁移到 logback
Logback - 如何编写自定义异常转换器以将堆栈跟踪折叠成一行

