问题追查记海外aws上redis-cluster单实例抖动问题追查
Posted 小树桩的朋友
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了问题追查记海外aws上redis-cluster单实例抖动问题追查相关的知识,希望对你有一定的参考价值。
【背景】
公司在海外的业务没有自建机房,而是使用了aws的服务,型号是r4.4xlarge。
但是,部署在aws上的redis集群,经常遇到某个实例耗时抖动比其他实例厉害,但是cpu、mem、网络等指标都较低的情况。
于是开启了一场漫长的问题定位之路。
【现象】
- 集群中某些redis实例有较明显的抖动现象
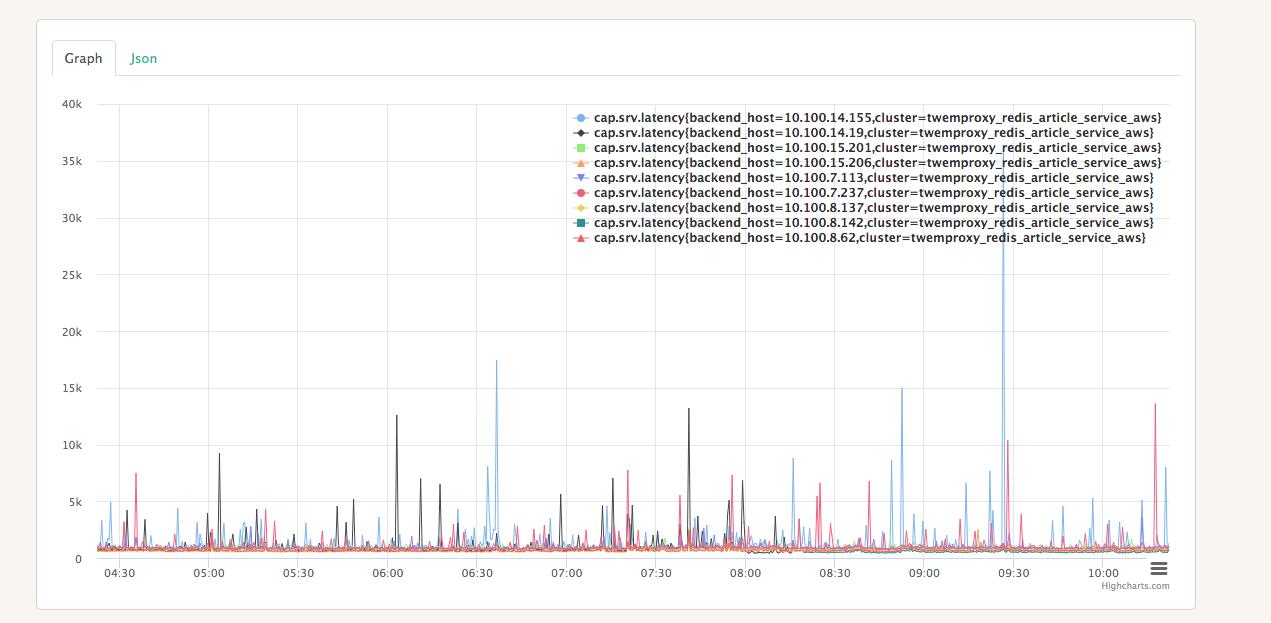
如上图所示,实例10.100.14.19、10.100.15.206、10.100.7.237有明显抖动。
- 所有机器的cpu资源、内存资源都还有很大余量,网络丢包也没有
【追查】
- 使用LATENCY工具对抖动的redis实例监控 => 无明确结论,第3条->可能有一个“扰人”的邻居
10.100.14.19:6870> LATENCY DOCTOR
Dave, I have observed latency spikes in this Redis instance. You don\'t mind talking about it, do you Dave?
1. fast-command: 2 latency spikes (average 1ms, mean deviation 0ms, period 184.50 sec). Worst all time event 1ms.
2. command: 10 latency spikes (average 8ms, mean deviation 10ms, period 77.70 sec). Worst all time event 39ms.
I have a few advices for you:
- Check your Slow Log to understand what are the commands you are running which are too slow to execute. Please check http://redis.io/commands/slowlog for more information.
- The system is slow to execute Redis code paths not containing system calls. This usually means the system does not provide Redis CPU time to run for long periods. You should try to:
1) Lower the system load.
2) Use a computer / VM just for Redis if you are running other softawre in the same system.
3) Check if you have a "noisy neighbour" problem.
4) Check with \'redis-cli --intrinsic-latency 100\' what is the intrinsic latency in your system.
5) Check if the problem is allocator-related by recompiling Redis with MALLOC=libc, if you are using Jemalloc. However this may create fragmentation problems.
- Deleting, expiring or evicting (because of maxmemory policy) large objects is a blocking operation. If you have very large objects that are often deleted, expired, or evicted, try to fragment those objects into multiple smaller objects.
- 使用watchdog将超过20ms的命令打印日志 =>
155384:signal-handler (1515198055)
--- WATCHDOG TIMER EXPIRED ---
EIP:
/lib/x86_64-linux-gnu/libc.so.6(rename+0x7)[0x7fe53f018727]
Backtrace:
/opt/tiger/cache_manager/bin/redis-server-3.2 10.100.14.19:6870 [cluster](logStackTrace+0x34)[0x462d24]
/opt/tiger/cache_manager/bin/redis-server-3.2 10.100.14.19:6870 [cluster](watchdogSignalHandler+0x1b)[0x462dcb]
/lib/x86_64-linux-gnu/libpthread.so.0(+0xf890)[0x7fe53f36b890]
/lib/x86_64-linux-gnu/libc.so.6(rename+0x7)[0x7fe53f018727]
/opt/tiger/cache_manager/bin/redis-server-3.2 10.100.14.19:6870 [cluster](readSyncBulkPayload+0x1ed)[0x441bbd]
/opt/tiger/cache_manager/bin/redis-server-3.2 10.100.14.19:6870 [cluster](aeProcessEvents+0x228)[0x426128]
/opt/tiger/cache_manager/bin/redis-server-3.2 10.100.14.19:6870 [cluster](aeMain+0x2b)[0x4263bb]
/opt/tiger/cache_manager/bin/redis-server-3.2 10.100.14.19:6870 [cluster](main+0x405)[0x423125]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0xf5)[0x7fe53efd2b45]
/opt/tiger/cache_manager/bin/redis-server-3.2 10.100.14.19:6870 [cluster][0x423395]
155384:signal-handler (1515198055) --------
- 发现同一机器上有其他服务消耗cpu较多,迁移 => 有效果,但是一段时间后又有抖动
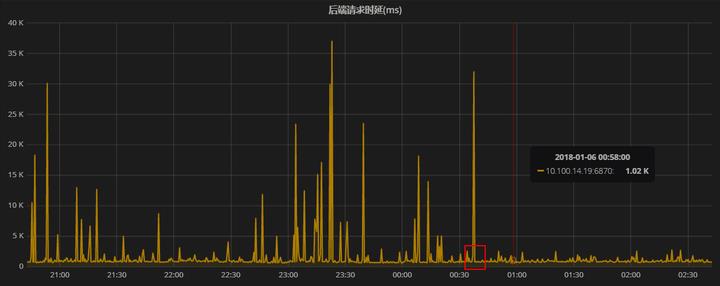
- 发现同一机器上有其他服务不定时的把cpu跑满 => node_keeper.py的bug
- 将整个集群的所有实例移到新的机器独立部署 => 抖动没有再发生
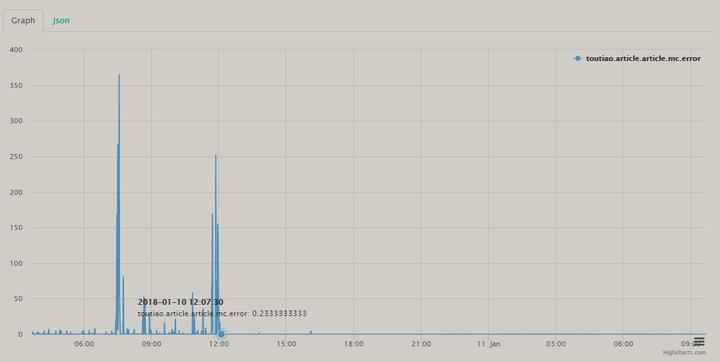
【初步结论】
同一机器上的其他服务影响了redis实例
- 其他服务平时cpu消耗很低,通过监控看不出来抖动
- 其他服务抖动的时候可能把cpu打满,如果cpu打满,redis所在的核繁忙,因为redis是单线程必然受到影响 => 产生抖动
redis是单线程+异步服务,很容易受到同机器其他服务的影响,且影响较大。
以上是关于问题追查记海外aws上redis-cluster单实例抖动问题追查的主要内容,如果未能解决你的问题,请参考以下文章