scala怎样创建redis集群连接池
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scala怎样创建redis集群连接池相关的知识,希望对你有一定的参考价值。
参考技术A 此外,我还讨论过较为常见的基于服务器的数据存储,比如MongoDB和CouchDB。每个数据存储都有其优势和劣势,特别是当应用于特定领域时。本期的Java开发2.0关注的是Redis,一种轻量级键值对数据存储。多数NoSQL实现本质上都是键值对,但是Redis支持非常丰富的值集,其中包括字符串、列表、集以及散列。因此,Redis通常被称为数据结构服务器。Redis也以异常快速而闻名,这使得它成为某一特定类型使用案例的最优选择。当我们想要了解一种新事物时,将其同熟知的事物进行比较可能会有所帮助,因此,我们将通过对比其与memcached的相似性以开启Redis探索之旅。接着我们将介绍Redis的主要功能,这些功能可以使其在某些应用场景可以胜过memcached。最后我将向您展示如何将Redis作为一个传统数据存储用于模型对象。Redis和memcachedMemcached是一个众所周知的内存对象缓存系统,通过将目标键和值导入内存缓存运行。因此,Memcached能回避读取磁盘时发生的I/O成本问题。在Web应用程序和数据库之间粘贴memcached时会产生更好的读取性能。因此,对于那些需要快速数据查询的应用程序,Memcached是一个不错的选择。其中的一个例子为股票查询服务,需要另外访问数据库获取相对静态数据,如股票名称或价格信息。MemcacheDB将Redis与memcached相比较并不公平,它与MemcacheDB相比要好的多,MemcacheDB是一个分布式键值对存储系统,专为数据持久化而设计。MemcacheDB与Redis较为相似,其新增优势可以使其轻松地与memcached实现的客户端进行通信。但是memcached也有其局限性,其中一个事实就是它所有的值均是简单的字符串。Redis作为memcached的替代者,支持更加丰富的功能集。一些基准(benchmarks)也表明Redis的速度要比memcached快很多。Redis提供的丰富数据类型使其可以在内存中存储更为复杂的数据,这是使用memcached无法实现的。同memcached不一样,Redis可以持久化其数据。Redis解决了一个重大的缓存问题,而其丰富的功能集又为其找到了其他用途。由于Redis能够在磁盘上存储数据以及跨节点复制数据,因而可以作为数据仓库用于传统数据模式(也就是说,您可以使用Redis,就像使用RDBMS一样)。Redis还经常被用作队列系统。在本用例中,Redis是备份和工作队列持久化存储(利用Redis的列表类型)的基础。GitHub是以此种方法使用Redis的大规模基础架构示例准备好Redis,立即开始!要开始使用Redis,您需要访问它,可以通过本地安装或者托管供应商来实现访问。如果您使用的MAC,安装过程可能就不那么简单。如果您使用的是Windows??,您需要先安装Cygwin。如果您正在寻找一个托管供应商,Redis4You拥有一个免费计划。不管您以何种方式访问,您都能够根据本文下列示例进行操作,但是我需要指出的是,使用一个托管供应商进行缓存可能并不是很好的缓存解决方案,因为网络延迟可能会抵消任何性能优势。您需要通过命令与Redis进行交互,这就是说,这里没有SQL类查询语言。使用Redis工作非常类似于使用传统map数据结构,即所有的一切都拥有一个键和一个值,每个值都有多种与之关联的数据类型。每个数据类型都有其自己的命令集。例如,如果您计划使用简单数据类型,比如某种缓存模式,您可以使用命令set和get。您可以通过命令行shell与一个Reids实例进行交互。还有多个客户端实现,可以以编程方式与Redis进行交互。清单1展示了一个使用基础命令的简单命令行shell交互:清单1.使用基础的Redis命令redis127.0.0.1:6379>setpageregistrationOKredis127.0.0.1:6379>keys*1)"foo"2)"page"redis127.0.0.1:6379>getpage"registration"在这里,我通过set命令将键"page"与值"registration"相关联。接着,我发出keys命令(后缀*表示我想看到所有可用的实例键。keys命令显示有一个page值和一个foo,我可以通过get命令检索到与一个键关联的值。请记住,使用get检索到的值只能是一个字符串。如果一个键的值是一个列表,那么您必须使用一个特定列表的命令来检索列表元素。(注意,有可以查询值类型的命令)。Java与Jedis集成对于那些想要将Redis集成到Java应用程序的编程人员,Redis团队建议使用一个名为Jedis的项目,Jedis是一个轻量级库,可以将本地Redis命令映射到Java方法。例如Jedis可以获取并设置简单值,如清单2所示:清单2.Java代码中的基础Redis命令JedisPoolpool=newJedisPool(newJedisPoolConfig(),"localhost");Jedisjedis=pool.getResource();jedis.set("foo","bar");Stringfoobar=jedis.get("foo");assertfoobar.equals("bar");pool.returnResource(jedis);pool.destroy();在清单2中,我配置了一个连接池并捕获连接,(与您在典型JDBC场景中的操作非常相似)然后我在清单的底部设置了返回操作。在连接池逻辑之间,我设置了值"bar"和键"foo",这是我通过get命令检索到的。与memcached类似,Redis允许您将过期(expiration)时间关联到一个值。因此我设置了这样一个值(比如,股票临时交易价格),最终将从Redis缓存中清除掉。如果我想在Jedis中设置一个过期时间,需要在发出set调用之后将其和一个过期时间关联。如清单3所示:清单3.Redis值可以设置为终止jedis.set("gone","daddy,gone");jedis.expire("gone",10);Stringthere=jedis.get("gone");assertthere.equals("daddy,gone");Thread.sleep(4500);StringnotThere=jedis.get("gone");assertnotThere==null;在清单3中,我使用了一个expire调用将"gone"的值设置为在10秒钟内终止。调用Thread.sleep之后,"gone"的get调用会返回null。Redis中的数据类型使用Redis数据类型,比如列表和散列需要专用命令用法。例如,我可以通过为键附加值来创建列表。python redis操作(五个基本类型集群管道池远程连接)
一、redis基本介绍
1、介绍
Redis:REmote DIctionary Server(远程字典服务器),是完全开源免费的,用C语言编写的,遵守BSD协议,是一个高性能的(Key/Value)分布式内存数据库,基于内存运行,并支持持久化的NoSQL数据库,是当前最热门的NoSQL数据库之一,也被人们称为数据结构服务器。
Redis与其他key-value缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的 key-value 类型的数据,同时还提供list、set、zset、hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
2、使用原因及场景
(1)redis使用原因
- 解决应用服务器的cpu和内存压力
- 减少io的读操作,减轻io的压力
- 关系型数据库的扩展性不强,难以改变表结构
(2)适用场景
- 数据高并发的读写
- 海量数据的读写
- 对扩展性要求高的数据
(3)使用场景
- 配合关系型数据库做高速缓存 ,缓存高频次访问的数据,降低数据库io, 分布式架构,做session共享
- 可以持久化特定数据。利用zset类型可以存储排行榜 利用list的自然时间排序存储最新n个数据
二、python 远程连接redis(阿里云ECS)
本文接下来的实验都是远程连接阿里云ECS里安装的redis,下面介绍一下,云服务器中redis如何设置才能远程访问。
开启redis的命令这里不再细说,各位可以自行查找命令,设置连接密码等,这里建议开启6379端口,一定设置redis连接密码,防止被病毒攻击。
(1)首先,需要修改redis配置文件,进入redis.conf,将绑定的ip改为0.0.0.0,port为6379,然后重启redis server。

(2)然后,进入云服务器管理控制台,找到安全组,点击进入。

(3) 进入安全组之后,可以手动添加端口,假设redis服务开启的6379端口,添加如下。

之后就可以进行远程连接了,可以按照如下测试代码进行测试。
# 测试远程连接是否成功
# redis 提供两个类 Redis 和 StrictRedis, StrictRedis 用于实现大部分官方的命令,Redis 是 StrictRedis 的子类
def test_install():
# 连接redis数据库,其中db表示数据库0,decode_response表示将取出结果改成字符串类型
r = redis.StrictRedis(host='1.1.1.1', port=6379, db=0, decode_responses=True, password='111111')
# 向redis数据库添加k-v
r.set('key1', 'value1')
# 从redis中取出值
print(r.get('key1'))
# 清空redis数据库0
r.flushdb()测试结果如下,成功连接。

三、python 连接池和管道
1、连接池
redis是基于内存的数据库,效率非常高,所以每次进行连接比真正使用消耗的资源和时间还多。所以为了节省资源,减少多次连接损耗,连接池的作用相当于缓存了多个客户端与redis服务端的连接,当有新的客户端来进行连接时,此时,只需要去连接池获取一个连接即可,实际上连接池就是把一个连接共享给多个客户端。所以redis-py 使用 connection pool 来管理对一个 redis server 的所有连接,避免每次建立、释放连接的开销。
def link_poll():
# 建立连接池
conn_pool = redis.ConnectionPool(host='1.1.1.1', port=6379, db=1, decode_responses=True, password='111111')
# 客户端0连接数据库
r0 = redis.StrictRedis(connection_pool=conn_pool)
r0.set('key1', 'value1')
print(r0.get('key1'))
# 客户端2连接数据库
r1 = redis.StrictRedis(connection_pool=conn_pool)
r1.set('key2', 'value2')
print(r1.get('key2'))
r0.flushdb()
r1.flushdb()2、管道
如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。管道(pipeline)是redis在提供单个请求中缓冲多条服务器命令的基类的子类。它通过减少服务器-客户端之间反复的TCP数据库包,从而大大提高了执行批量命令的功能。
def cmd_pipeline():
conn_pool = redis.ConnectionPool(host='1.1.1.1', port=6379, db=0, decode_responses=True, password='111111')
r0 = redis.StrictRedis(connection_pool=conn_pool)
# pipe = r.pipeline(transaction=False)
# 默认的情况下,管道里执行的命令可以保证执行的原子性,执行pipe = r.pipeline(transaction=False)可以禁用这一特性。
# pipe = r.pipeline(transaction=True)
pipe = r0.pipeline() # 创建一个管道
pipe.set('name', 'jack')
pipe.set('role', 'sb')
pipe.sadd('faz', 'baz')
pipe.incr('num') # 如果num不存在则vaule为1,如果存在,则value自增1
pipe.execute()
print(r0.get("name"))
print(r0.get("role"))
print(r0.get("num"))四、python redis 五大基本类型操作
1、string
# redis 基本命令 string
def cmd_string():
conn_pool = redis.ConnectionPool(host='1.1.1.1', port=6379, db=0, decode_responses=True, passwoed='111111')
r0 = redis.StrictRedis(connection_pool=conn_pool)
# ex:过期时间(秒),px:过期时间(毫秒) 设置过期时间后,键值在时间结束后就清除
r0.set('key1', 'value1', ex=3)
r0.set('key2', 'value2', px=4)
# nx:nx为True,则只有key不存在时,操作才会执行
# xx:xx为True,则只有key存在时,操作才会执行
r0.set('key1', 'value1', nx=True)
r0.set('key2', 'value2', xx=True)
# 对应的 setnx(key, value) 只有key不存在时,操作才会执行
# 对应的 setex(key, time, value) time - 过期时间(秒)
# 对应的 psetex(key, time_ms, value) time_ms - 过期时间(毫秒)
r0.setnx('key3', 'value3')
r0.setex('key4', 3, 'value4')
time.sleep(3)
print(r0.get('key4'))
# mset 批量设置值;mget 批量获取值
keydict =
keydict['key5'] = 'value5'
keydict['key6'] = 'value6'
r0.mset(keydict)
print(r0.mget('key5', 'key6'))
# setrange(key, start, end) 修改字符串内容,从指定字符串索引开始向后替换
# getrange(key, start, end) 获取子序列(根据字节获取,非字符)
r0.setrange('key6', 2, '222')
print(r0.get('key6'))
print(r0.getrange('key5', 1, 3))
# strlen(key) 返回key对应值的字节长度(一个汉字3个字节)
print(r0.strlen('key5'))
# incr(self, key, amount=1) 自增 key 对应的值,当 key 不存在时,则创建 key=amount,否则,则自增
r0.set('key7', 1)
r0.incr('key7', amount=1)
print(r0.get('key7'))
# decr(self, key, amount=1) 自减 key 对应的值,当 key 不存在时,则创建 key=amount,否则,则自减。
r0.decr('key7', amount=1)
print(r0.get('key7'))
# append(key, value) 在redis key对应的值后面追加内容
r0.append('key6', '5454')
print(r0.get('key6'))
# 删除键
r0.delete('key6')
print(r0.get('key6'))
r0.flushdb()2、hash
# redis 基本命令 hash
def cmd_hash():
conn_pool = redis.ConnectionPool(host='1.1.1.1', port=6379, db=0, decode_responses=True)
r0 = redis.StrictRedis(connection_pool=conn_pool)
# hset(name, key, value) name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
r0.hset("hash1", "k1", "v1")
r0.hset("hash1", "k2", "v2")
print(r0.hkeys("hash1")) # 取hash中所有的key
print(r0.hget("hash1", "k1")) # 单个取hash的key对应的值
print(r0.hmget("hash1", "k1", "k2")) # 多个取hash的key对应的值
r0.hsetnx("hash1", "k2", "v3") # 只能新建, 只有key不存在时,操作才会执行
print(r0.hget("hash1", "k2"))
# hmset(name, mapping) 批量增加,在name对应的hash中批量设置键值对
r0.hmset('hash2', 'k1': 'v1', 'k2': 'v2')
# hmget(name, keys, *args) 在name对应的hash中获取多个key的值
print(r0.hmget('hash2', 'k1', 'k2'))
# hgetall(name) 取出所有的键值对
print(r0.hgetall('hash1'))
# hlen(name) 得到所有键值对的格式 hash长度
print(r0.hlen('hash1'))
# hkeys(name) 得到所有的keys(类似字典的取所有keys)
print(r0.hkeys('hash1'))
# hvals(name) 得到所有的value(类似字典的取所有value)
print(r0.hvals('hash1'))
# hexists(name, key) 判断成员是否存在(类似字典的in
print(r0.hexists("hash1", "k4")) # False 不存在
print(r0.hexists("hash1", "k1")) # True 存在
# hdel(name,*keys) 删除键值对
r0.hdel('hash1', 'k1', 'v1')
print(r0.hget('hash', 'k1'))
# hincrby(name, key, amount=1) 自增自减整数(将key对应的value--整数 自增1或者2,或者别的整数 负数就是自减)
r0.hset('hash1', 'k3', 1)
r0.hincrby('hash1', 'k3', amount=5)
print(r0.hget('hash1', 'k3'))
r0.flushdb()3、list
# redis 基本命令 list
def cmd_list():
conn_pool = redis.ConnectionPool(host='1.1.1.1', port=6379, db=0, decode_responses=True, password='111111')
r0 = redis.StrictRedis(connection_pool=conn_pool)
# lpush(name,values) 增加(类似于list的append,只是这里是从左边新增加)--没有就新建
r0.lpush('list1', 1, 2, 3)
# lrange(name, start, end) 取出元素
print(r0.lrange('list1', 0, -1)) # 取出列表全部元素
# rpush(name,values) 增加(从右边增加)--没有就新建
r0.rpush('list2', 1, 2, 3)
print(r0.lrange('list2', 0, -1))
# lpushx(name,value) 往已经有的name的列表的左边添加元素,没有的话无法创建
r0.lpushx("list2", 77)
print(r0.lrange('list2', 0, -1))
# rpushx(name,value) 往已经有的name的列表的右边添加元素,没有的话无法创建
r0.rpushx("list2", 66)
print(r0.lrange('list2', 0, -1))
# linsert(name, where, refvalue, value)) 新增(固定索引号位置插入元素)
# 参数:where - BEFORE或AFTER; refvalue - 标杆值,即:在它前后插入数据; value - 要插入的数据
r0.linsert("list2", "before", "66", "00") # 往列表中左边第一个出现的元素"66"前插入元素"00"
print(r0.lrange("list2", 0, -1))
# r.lset(name, index, value) 修改(指定索引号进行修改)
r0.lset('list2', 0, 101) # 把索引号是0的元素修改成101
print(r0.lrange("list2", 0, -1))
# r.lrem(name, value, num) 删除(指定值进行删除)
# 参数:value - 要删除的值; num=0,删除列表中所有的指定值; num=2 - 从前到后,删除2个, num=1,从前到后,删除左边第1个; num=-2 - 从后向前,删除2个
r0.lrem("list2", "66", 1) # 将列表中左边第一次出现的"11"删除
print(r0.lrange("list2", 0, -1))
r0.lrem("list2", "99", -1) # 将列表中右边第一次出现的"99"删除
print(r0.lrange("list2", 0, -1))
r0.lrem("list2", "22", 0) # 将列表中所有的"22"删除
print(r0.lrange("list2", 0, -1))
# lpop(name) 删除并返回; rpop(name) 表示从右向左操作
print(r0.lpop('list1'))
# ltrim(name, start, end) 删除索引之外的值
r0.ltrim('list2', 0, 1)
print(r0.lpop('list2'))
# lindex(name, index) 取值(根据索引号取值)
print(r0.lindex("list2", 0)) # 取出索引号是0的值
# rpoplpush(src, dst) 移动 元素从一个列表移动到另外一个列表
r0.rpoplpush('list1', 'list2')
print(r0.lrange("list2", 0, -1))
r0.flushdb()4、set
# redis 基本命令 set
def cmd_set():
conn_pool = redis.ConnectionPool(host='1.1.1.1', port=6379, db=0, decode_responses=True, password='111111')
r0 = redis.StrictRedis(connection_pool=conn_pool)
# sadd(name, values) 向redis中新增集合
r0.sadd('set1', 1, 2, 3)
print(r0.smembers('set1')) # 获取集合中所有的成员
# scard(name) 获取元素个数 类似于len
print(r0.scard('set1'))
# sdiff(keys, *args) 差集
r0.sadd('set2', 1, 22, 33)
print(r0.sdiff('set1', 'set2')) # 在集合set1但是不在集合set2中
print(r0.sdiff("set2", "set1")) # 在集合set2但是不在集合set1中
# sdiffstore(dest, keys, *args) 差集--差集存在一个新的集合中
r0.sdiffstore("set3", "set1", "set2") # 在集合set1但是不在集合set2中
print(r0.smembers("set3")) # 获取集合3中所有的成员
# sinter(keys, *args) 交集
print(r0.sinter('set1', 'set2')) # 取2个集合的交集
# sinterstore(dest, keys, *args) 交集--交集存在一个新的集合中
r0.sinterstore('set3', 'set1', 'set2')
print(r0.smembers('set3'))
# sunion(keys, *args) 并集
print(r0.sunion("set1", "set2")) # 取2个集合的并集
# sunionstore(dest,keys, *args) 并集--并集存在一个新的集合
r0.sunionstore("set3", "set1", "set2") # 取2个集合的并集
print(r0.smembers("set3"))
# sismember(name, value) 判断是否是集合的成员 类似in
print(r0.sismember('set1', 88))
print(r0.sismember('set1', 2))
# smove(src, dst, value) 将某个成员从一个集合中移动到另外一个集合
r0.smove("set1", "set2", 2)
print(r0.smembers("set1"))
print(r0.smembers("set2"))
# spop(name) 随机删除并且返回被删除值
print(r0.spop("set2")) # 这个删除的值是随机删除的,集合是无序的
print(r0.smembers("set2"))
# srem(name, values) 指定值删除
print(r0.srem("set1", 1)) # 从集合中删除指定值 11
print(r0.smembers("set1"))
r0.flushdb()5、有序set
# redis 基本命令 有序set
def cmd_sort_set():
conn_pool = redis.ConnectionPool(host='1.1.1.1', port=6379, db=0, decode_responses=True, password='111111')
r0 = redis.StrictRedis(connection_pool=conn_pool)
keydict =
keydict['n1'] = 1
keydict['n2'] = 2
keydict['n3'] = 38
keydict['n4'] = 15
keydict['n5'] = 21
keydict['n6'] = 7
r0.zadd('zset1', keydict)
print(r0.zrange('zset1', 0, -1)) # 获取有序集合中所有元素
print(r0.zrange('zset1', 0, -1, withscores=True)) # 获取有序集合中所有元素和分数
# zcard(name) 获取有序集合元素个数 类似于len
print(r0.zcard("zset1")) # 集合长度
# r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float) 获取有序集合的所有元素
# 按照索引范围获取name对应的有序集合的元素
# name - redis的name
# start - 有序集合索引起始位置(非分数)
# end - 有序集合索引结束位置(非分数)
# desc - 排序规则,默认按照分数从小到大排序
# withscores - 是否获取元素的分数,默认只获取元素的值
# score_cast_func - 对分数进行数据转换的函数
print(r0.zrange('zset1', 0, -1, desc=False, withscores=True, score_cast_func=int))
# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float) 按照分数范围获取name对应的有序集合的元素
print(r0.zrangebyscore('zset1', 1, 18, withscores=True))
# zcount(name, min, max) 获取name对应的有序集合中分数 在 [min,max] 之间的个数
print(r0.zcount('zset1', 1, 20))
# zincrby(name, amount, value) 自增
r0.zincrby("zset1", amount=2.0, value='n2') # 每次将n2的分数自增2
print(r0.zrange("zset1", 0, -1, withscores=True))
# zrank(name, value) 获取值的索引号
print(r0.zrank("zset1", "n1")) # n1的索引号是0 这里按照分数顺序(从小到大)
print(r0.zrank("zset1", "n6")) # n6的索引号是2
print(r0.zrevrank("zset1", "n1")) # n1的索引号是5 这里按照分数倒序(从大到小)
# zrem(name, values) 指定值删除
r0.zrem("zset1", "n3") # 删除有序集合中的元素n3 删除单个
print(r0.zrange("zset1", 0, -1))
# zremrangebyrank(name, min, max) 根据排行范围删除,按照索引号来删除
r0.zremrangebyrank('zset1', 0, 1)
print(r0.zrange("zset1", 0, -1, withscores=True))
# zremrangebyscore(name, min, max) 根据分数范围删除
r0.zremrangebyscore("zset1", 3, 16) # 删除有序集合中的分数是11-22的元素
print(r0.zrange("zset1", 0, -1, withscores=True))
# zscore(name, value) 获取值对应的分数
print(r0.zscore("zset1", "n5")) # 获取元素n27对应的分数27
r0.flushdb()五、python 操作redis集群
1、redis构建集群(一主二从、哨兵模式)
redis的基本操作这里不再详细叙述,本节直接记录redis如何构建集群,为了演示方便,本集群配置在一台服务器下配置一主二从的集群模式,并使用哨兵监视。
(1)首先,需要配置redis.conf文件,构建redis6379.conf、redis6380.conf、redis6381.conf三个文件分别对应,端口为6379、6380、6381三个redis,并通过这三个文件开启集群。对于每个文件内容需要进行一些更改。步骤如下:
创建多个redis文件:
root@ymumu-server1:/home/redis-6.2.5# cp redis.conf redis6379.conf
root@ymumu-server1:/home/redis-6.2.5# cp redis.conf redis6380.conf
root@ymumu-server1:/home/redis-6.2.5# cp redis.conf redis6381.conf
分别进入各个文件进行内容修改:
1、指定端口 6379,其他两文件依次类推6380、6381
3、开启daemonize yes
4、Pid文件名字 pidfile /var/run/redis_6379.pid , 依次类推
5、Log文件名字 logfile "6379.log" , 依次类推
6、Dump.rdb 名字 dbfilename dump6379.rdb , 依次类推
三个文件都配置完成后,需要服务开启,分别对应三个文件,命令如下:
root@ymumu-server1:/usr/local/bin# redis-server /home/redis-6.2.5/redis6379.conf
root@ymumu-server1:/usr/local/bin# redis-server /home/redis-6.2.5/redis6380.conf
root@ymumu-server1:/usr/local/bin# redis-server /home/redis-6.2.5/redis6381.conf
root@ymumu-server1:/usr/local/bin# ps -ef | grep redis
root 83555 83441 0 11:03 pts/0 00:00:00 vim redis6379.conf
root 83577 1 0 11:15 ? 00:00:00 redis-server 0.0.0.0:6379
root 83584 1 0 11:15 ? 00:00:00 redis-server 0.0.0.0:6380
root 83590 1 0 11:15 ? 00:00:00 redis-server 0.0.0.0:6381
root 83596 83489 0 11:15 pts/1 00:00:00 grep --color=auto redis
准备环境搭建完成,接下来需要进行主从配置,并开启哨兵模式。
默认情况下,开启的三个redis都是主节点,用命令info replication查看,如下所示。
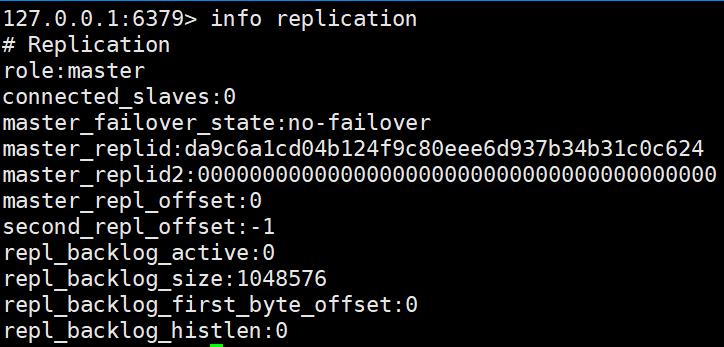
接下来的主从配置 配置为6379为Master 其余两个为Slave,命令如下:
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379
OK
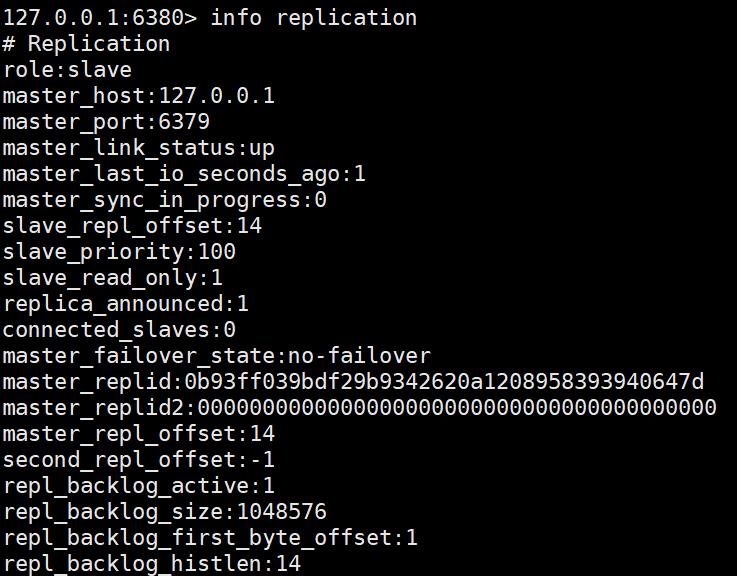
接下来,配置哨兵模式:
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。Redis从2.8开始正式提供了Sentinel(哨兵) 架构来解决这个问题。
哨兵有两个作用:
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
配置步骤如下:
1、redis 目录下sentinel.conf 文件
3、配置哨兵,填写内容
sentinel monitor 被监控主机名字 127.0.0.1 6379 1
上面最后一个数字1,表示主机挂掉后slave投票看让谁接替成为主机,得票数多少后成为主机
4、启动哨兵
Redis-sentinel /redis-6.2.5/sentinel.conf
上述目录依照各自的实际情况配置,可能目录不同
接下来,启动哨兵:
root@ymumu-server1:/usr/local/bin# redis-sentinel /home/redis-6.2.5/sentinel.conf

2、python操作redis集群
首先需要安装:pip3 install redis-py-cluster
from rediscluster import RedisCluster
# python 操作redis集群
def cmd_cluster():
try:
startup_nodes = [
"host": "1.1.1.1", "port": 6379,
"host": "1.1.1.1", "port": 6380,
"host": "1.1.1.1", "port": 6381
]
# 连接redis集群
redis_conn = RedisCluster(startup_nodes=startup_nodes, password='111111').connection
if not redis_conn:
print("连接redis集群失败")
exit()
else:
print("连接redis集群成功")
except Exception as e:
print(e)
print("错误,连接redis 集群失败")以上是关于scala怎样创建redis集群连接池的主要内容,如果未能解决你的问题,请参考以下文章
python redis操作(五个基本类型集群管道池远程连接)
python redis操作(五个基本类型集群管道池远程连接)