redis 十五. 缓存穿透 与布隆过滤器原理
Posted 苹果香蕉西红柿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis 十五. 缓存穿透 与布隆过滤器原理相关的知识,希望对你有一定的参考价值。
目录
一. 布隆过滤简基础
- 首先了解一个需求: 现有50亿个电话号码,如何快速准确的判断这些电话号码已经存在(这个问题的关键是大数据量,快速,判断是否存在)不管数据库还是redis,不管什么数据类型50亿都占用内存太大
- 布隆过滤器解释: 实际是一个很长的二进制数组+一系列随机hash算法映射函数,主要用于判断一个元素是否存在某个集合中(简单理解为:由一个初始值都为0的bit数组和多个哈希函数构成用来快速判断某个数据是否存在,类似于set的数据结构,只是统计结果不太准确)
- 布隆过滤器的特点
1)高效的插入和查询,占用空间少,返回结果不确定
2)一个元素如果判断结果为存在实际该元素可能不存在,如果判断该结果不存在则一定不存在
3)布隆过滤器可以添加元素,但是不能删除元素,因为删除元素会导致误判率的增加
4)误判只会发生才过滤器没有添加过的元素,对于添加过的元素不会发生误判
- 误判的原因,假设一个数据aaaa计算到的hash值是"1111",但是hash是可能重复的,布隆过滤器中已经存储了数据bbbb的hash值"1111",这时候通过hash值判断aaaa是否存在,返回true,时间存储的"1111"对应的数据是bbbb
- 布隆过滤器使用场景: 解决缓存穿透问题,黑名单校验
二. 布隆过滤器原理
-
复习java中的hash函数: 将任意大小的数据通过hash算法转换为特定大小的hash编码,也叫散列,可能存在冲突,也就是两个hash值不同实际数据一定不同,两个hash相同,实际数据可能不相同 使用hash表存大量数据时,空间效率低,并且当只有一个hash函数时,很容易发生hash碰撞
-
上面提到过布隆过滤器是一个很长的初始值都为0的,二进制数组+一系列随机hash算法映射函,类似于set的数据结构,统计结果不太准确(在统计存在时)

-
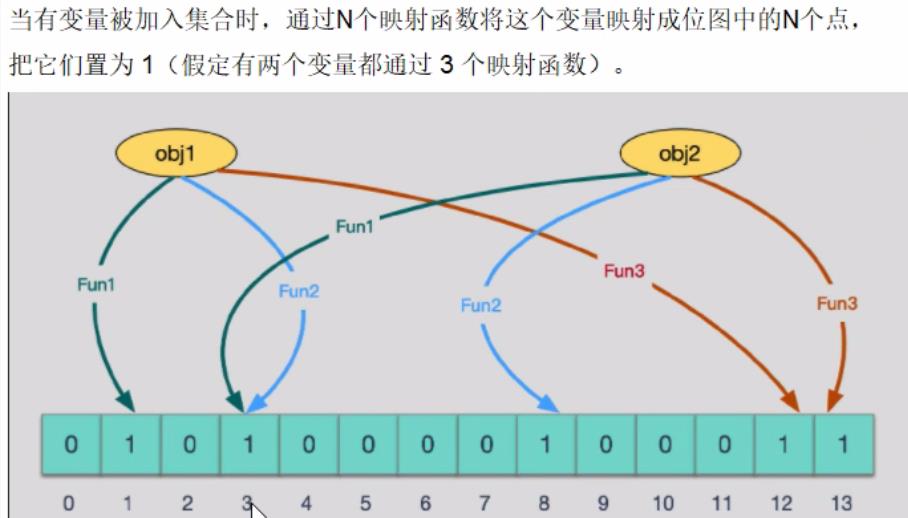
添加key时: 使用多个hash函数,对key进行hash运算得到一个整数索引,然后与位数组长度进行取模运算拿到位置,每个hash函数都会得到不同的位置,将这几个位置设置为1,完成了一次add操作
-
查询key时,只要通过key进行hash运算拿到整数索引后与位数组长度进行取模运算,拿到位数组的位置,只要一次位数组中指定的位置值为0,就说明key不存在
-
解释为什么判断存在的可能不存在,假设在判断一个key是经过hash运算,与位数组长度取模运算获取到位置后判断该位置上是1,这个1可能是对别的key进行标记的
-
解释为什么不能删除,删除会造成误判率增加的原因: 看上图,添加obj1与obj2两个数据,假设需要通过三次hash运算获取到了三个位置obj1对应1,3,12, obj2对应3, 8, 13,会发现obj1与obj2同时都用到了3位置,假设我要删除obj1,将索引为1,3,12位置上的1设置为0,当查询obj2是否存在时走到3位置上会发现在删除obj1时已经设置为0了,实际存在的却返回不存在,发生误判
-
基于布隆过滤器的快速检测特性,我们可以在做数据库写入是,使用布隆过滤器做标记,当缓存缺失后,查询数据库前(或存储数据库–>redis成功后再使用布隆过滤器进行标记)先通过查询布隆过滤器判断是否存在,如果不存在则直接返回不需要操作数据库
-
优化布隆过滤器出现了布谷鸟过滤器, 相比布谷鸟过滤器,布隆过滤器查询性能低,空间利用率低,不支持删除以及计数操作
三. redis 缓存穿透
- 什么是缓存穿透: 查询数据,先查询redis,后查询mysql,都查询不到的记录,请求每次都会打到数据库导致数据库压力暴增,数据库宕机
- 解决方案:
1)空对象缓存: 假设查询到redis没有,数据库也没有的数据时,存储一个空或一个缺省值到redis,后续再去查询这个为空的key,就会走redis(但是恶意攻击使用大量不同数据库redis同时都不存在的key查询不能解决,并且防止出现这种情况在向redis中存储空对象时要设置过期时间,防止redis中存储大量为空的key)
2)bloomfilter过滤器: 在存储数据是,除了存储redis与数据库,在布隆过滤器中再存储一份进行标记,后续查询时走布隆过滤器判断这个key是否不存在或存在,如果不存在直接return
Google 布隆过滤器Guava解决缓存穿透
- 创建项目工程
- 项目中引入 Guava 依赖
<!--guava-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
- Guava helloWorld 重点关注几个API
1)BloomFilter 对象的创建,指定当前过滤器能存储多少个元素,误判率
3)BloomFilter put(元素) 方法, 将元素数据存入过滤器中,实际存储的并不是元素本身(具体了解布隆过滤器原理)
2)BloomFilter mightContain(元素) 方法, 判断元素是否存在
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class Test
public void bloomFilter()
//1.创建布隆过滤器对象
//create方法中的Funnels 与 100 表示创建一个位数组可以容纳100个数据的过滤器,误判率是0.03
BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(), 100, 0.03d);
//BloomFilter<String> filter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), 100000, 0.03d);
//2.判断指定元素是否存在 mightContain(元素)
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
//3.将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
- 实际开发中Guava 布隆过滤器应用流程
1)需要使用布隆过滤器的模块估算该模块大概会存多少个key,确定布隆过滤器存放数据大小
2)项目启动时,插入对应该功能模块数据时同步将数据key存入布隆过滤器
3)编写过滤器,请求查询时拦截过滤查询过滤器是否不存在,如果不存在直接return
4)插入对应功能模块数据时插入数据库,插入redis,对应的key插入布隆过滤器
- 注意误判问题,判断一个元素在过滤器中不存在,则一定不存在,判断一个元素在过滤器中存在,也可能不存在,误判率0.03的误判率
- 查看创建 BloomFilter对象create()源码发现在Guava过滤器中底层默认指定使用了5个hash函数,默认的误判率为0.03

- 在上面的示例代码中我们创建BloomFilter指定了误判率,需要注意,可以手动指定,但是误判率越低,性能越低,误判率越小,位数组长度越大,hash此处越多

- 注意点: Guava 是单机版
Redis 布隆过滤器解决缓存穿透(推荐)
- 使用流程
1)项目中引入redisson依赖
2)配置redissonClient注意是单机模式还是集群模式
3)通过redissonClient构造redis 布隆过滤器
4)初始化布隆过滤器,设置存放数据量,误判率
5)存储数据到mysql,redis后在redis中做存储标识将key存入布隆过滤器
6)查询时判断过滤器中如果不存在,直接return
- 项目中添加相关依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>
- redissonClient 集群模式配置示例
/**
* 单机版
* @return
*/
@Bean
public Redisson redisson()
Config config = new Config();
config.useSingleServer().setAddress("redis://47.100.63.107:16379").setDatabase(0);
return (Redisson) Redisson.create(config);
/**
* 集群版
* @return
*/
@Bean
public RedissonClient getRedisson()
//redi集群地址
String cluster="10.10.1.1:7000,10.10.1.1:7001,10.10.1.1:7002,10.10.1.1:7003,10.10.1.1:7004,10.10.1.1:7005";
String[] nodes = cluster.split(",");
//redisson版本是3.5,集群的ip前面要加上“redis://”,不然会报错,3.2版本可不加
for (int i = 0; i < nodes.length; i++)
nodes[i] = "redis://" + nodes[i];
Config config = new Config();
//SentinelServersConfig serverConfig = config.useSentinelServers()
//useSentinelServers() 与 useClusterServers() 前者要指定masterName
//调用 setMasterName("masterName")
config.useClusterServers() //这是用的集群server
.addNodeAddress(nodes)
.setScanInterval(2000) //设置集群状态扫描时间
.setPassword("password")
.setTimeout(3000)
.setMasterConnectionPoolSize(8)
.setSlaveConnectionPoolSize(8)
.setSlaveConnectionMinimumIdleSize(1)
.setMasterConnectionMinimumIdleSize(1);;
RedissonClient redisson = Redisson.create(config);
//可通过打印redisson.getConfig().toJSON().toString()来检测是否配置成功
return redisson;
- redis布隆过滤器helloWorld
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RBucket;
import org.redisson.api.RedissonClient;
import org.redisson.client.codec.StringCodec;
import org.redisson.config.Config;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import java.util.concurrent.TimeUnit;
/**
* redis 布隆过滤器 helloWorld 此处以单机redis示例
*/
public class RedissonBloomFilterDemo
@Autowired
private RedisTemplate redisTemplate;
public void redissonBloomFilterHelloWorld()
//1.获取redisClient 连接redis服务器
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.111.147:6379").setDatabase(0);
RedissonClient redissonClient = Redisson.create(config);
//2.通过redisson构造rBloomFilter,"phoneListBloomFilter" 固定
RBloomFilter rBloomFilter = redissonClient.getBloomFilter("phoneListBloomFilter",new StringCodec());
//3.初始化布隆过滤器,指定过滤器中存储数据量为1000000,误判率为0.03
rBloomFilter.tryInit(1000000,0.03d);
//4.使用示例
//4.1向redis中添加kv键值对,"new StringCodec()"是指定编码格式
redissonClient.getBucket("key1",new StringCodec()).set("valu1");
//等同于
redisTemplate.opsForValue().set("key1","valu1");
//4.2
redissonClient.getBucket("key1", new StringCodec());
//等同于
redisTemplate.opsForValue().get("key1");
//4.3向过滤器中添加一个元素key
rBloomFilter.add("key1");
//4.4 判断指定元素在过滤器中是否存在,存在返回true
boolean b = rBloomFilter.contains("key1");
//4.5释放client连接
redissonClient.shutdown()
redis 安装布隆过滤器插件
- 上面演示了redis版本的布隆过滤器使用,但是redis上需要安装布隆过滤器的插件

四. 模拟Guava编码通过redis实现布隆过滤器
- 引入Guava依赖
- 模拟Guava实现布隆过滤器逻辑编码实现,底层基础运算逻辑不变,只是把原Guava通过内存存储数据,修改为通过redis存储数据
import com.google.common.base.Preconditions;
import com.google.common.hash.Funnel;
import com.google.common.hash.Hashing;
public class BloomFilterHelper<T>
private int numHashFunctions;
private int bitSize;
private Funnel<T> funnel;
public BloomFilterHelper(Funnel<T> funnel, int expectedInsertions, double fpp)
Preconditions.checkArgument(funnel != null, "funnel不能为空");
this.funnel = funnel;
// 计算bit数组长度
bitSize = optimalNumOfBits(expectedInsertions, fpp);
// 计算hash方法执行次数
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
public int[] murmurHashOffset(T value)
int[] offset = new int[numHashFunctions];
long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++)
int nextHash = hash1 + i * hash2;
if (nextHash < 0)
nextHash = ~nextHash;
offset[i - 1] = nextHash % bitSize;
return offset;
/**
* 计算bit数组长度
*/
private int optimalNumOfBits(long n, double p)
if (p == 0)
// 设定最小期望长度
p = Double.MIN_VALUE;
return (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
/**
* 计算hash方法执行次数
*/
private int optimalNumOfHashFunctions(long n, long m)
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
import com.google.common.base.Preconditions;
import org.springframework.data.redis.core.RedisTemplate;
public class BloomRedisService<T>
private RedisTemplate<String, String> redisTemplate;
private BloomFilterHelper<T> bloomFilterHelper;
public void setBloomFilterHelper(BloomFilterHelper<T> bloomFilterHelper)
this.bloomFilterHelper = bloomFilterHelper;
public void setRedisTemplate(RedisTemplate<String, String> redisTemplate)
this.redisTemplate = redisTemplate;
/**
* 根据给定的布隆过滤器添加值
*/
public void addByBloomFilter(String key, T value)
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset)
redisTemplate.opsForValue().setBit(key, i, true);
/**
* 根据给定的布隆过滤器判断值是否存在
*/
public boolean includeByBloomFilter(String key, T value)
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset)
if (!redisTemplate.opsForValue().getBit(key, i))
return false;
return true;
- 配置
import com.google.common.base.Charsets;
import com.google.common.hash.Funnel;
import com.single.mall.service.IUserBusinessService;
import com.single.mall.service.impl.BloomFilterHelper;
import com.single.mall.service.impl.BloomRedisService;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.util.CollectionUtils;
import java.util.Arrays;
import java.util.List;
@Configuration
public class BloomFilterConfiguration implements InitializingBean
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private IUserBusinessService userBusinessService;
/**
* 将模拟Guava自定义实现布隆过滤器底层BloomFilterHelper注入容器
* @return
*/
@Bean
public BloomFilterHelper<String> initBloomFilterHelper()
return new BloomFilterHelper<>((Funnel<String>) (from, into) -> into.putString(from, Charsets.UTF_8)
.putString(from, Charsets.UTF_8), 1000000, 0.01);
/**
* 将通过redis自定义实现的布隆过滤器BloomRedisService bean注入
*
* @return
*/
@Bean
public BloomRedisService<String> bloomRedisService()
BloomRedisService<String> bloomRedisService = new BloomRedisService<>();
bloomRedisService.setBloomFilterHelper(this.initBloomFilterHelper());
bloomRedisService.setRedisTemplate(redisTemplate);
Redis缓存雪崩缓存穿透缓存击穿
Redis缓存雪崩、缓存穿透、缓存击穿
Redis缓存过程
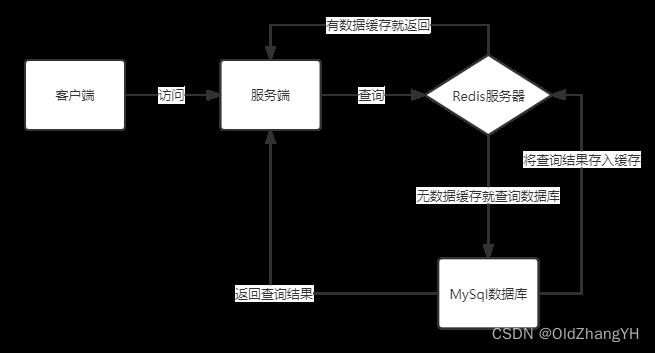
Redis数据库是一个nosql数据库,存储的数据格式是key-value。Redis数据库运行在内存中,因此他的查询速度比MySql快的多。所以我们会把一些用户经常查询的数据放在Redis中,当Redis有的时候就直接返回,当Redis中没有的时候再去数据库中查找。以此增加服务的运行效率。
缓存雪崩
Redis中的缓存数据是有过期时间的,当在同一时间大量的缓存同时失效时就会造成缓存雪崩。
比如说,在11点的时候大家都去饿了么点外卖,这个时候饿了么的Redis中就存了一大批商家的信息,并且饿了么的程序员给这个缓存设置的过期时间是6个小时。那么到下午5点晚饭时间又是一大波人来饿了么点外卖,这个时候Redis的缓存刚刚好集体过期了,短时间内大量的查询请求就全部落到了脆弱的MySql上,导致MySql直接爆炸!

解决方案
要解决Redis的缓存雪崩就需要避免Redis的缓存在短时间内大量的过期
永不过期
设置Redis中的key永不过期,但是这样会占用很多服务器的内存。
合理的设置过期时间
根据业务需要来合理的设置过期的时间。但是架不住有一些突发的情况。
使用Redis的分布式锁
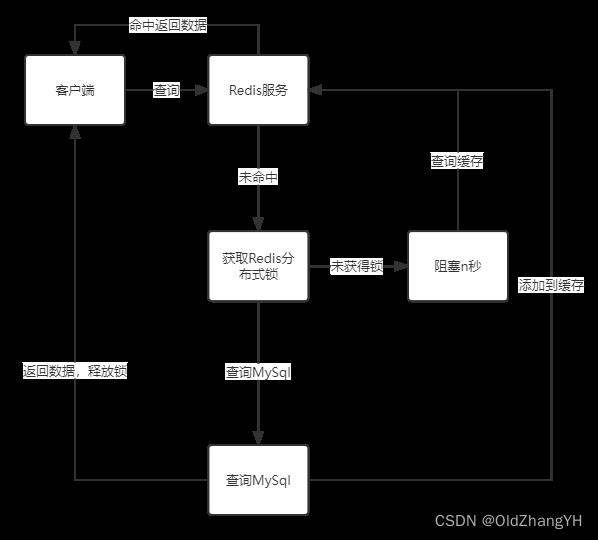
既然一瞬间大量请求落到MySql上会导致MySql爆炸!那么就加一点限制,让一时间只有一个相同请求落到MySql上,反正都是查询同一个信息,之后的其他请求就可以去Redis中找了。
缓存穿透
Redis缓存穿透指的是,在Redis缓存和数据库中都找不到相关的数据。也就是说这是个非法的查询,客户端发出了大量非法的查询 比如id是负的 ,导致每次这个查询都需要去Redis和数据库中查询。导致MySql直接爆炸!

解决方案
过滤非法查询
在后台服务中过滤非法查询,直接不让他落到Redis服务上。比如id<=0或者分页内容过大的等
缓存空对象
如果他的查询数据是合法的,但是确实Redis和MySql中都没有,那么我们就在Redis中储存一个空对象,这样下次客户端继续查询的时候就能在Redis中返回了。但是,如果客户端一直发送这种恶意查询,就会导致Redis中有很多这种空对象,浪费很多空间
布隆过滤器
布隆过滤器由一个二进制数组和k个哈希数组组成。
布隆过滤器的新增
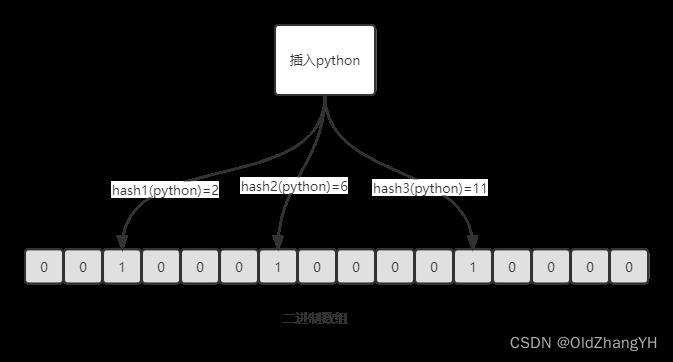
当我们想新增一个元素时(例如新增python),布隆过滤器就会使用hash函数计算出几个索引值,然后将二进制数组中对应的位置修改为1。
布隆过滤器的查询
当我们想查询一个元素时(例如查询python),布隆过滤器就会使用hash函数计算出几个索引值,然后查询二进制数组中的对应位置是否都为1。如果都为1就说明改元素存在。但是布隆过滤器存在误判的可能性,因为不同的元素hash后的值可能是一样的,例如我们查询java,java经过hash计算出来的索引值和python的一模一样,那么就会认为java也在布隆过滤器中。

布隆过滤器的删除
同上,布隆过滤器删除就是把hash后数组对应的位置改成0.但是存在误删的可能。按照上面的例子删除python就会同时把java给删掉。
布隆过滤器解决缓存穿透
我们首先把MySql中的数据存到布隆过滤器中(由于使用二进制数组,也就是位图所以空间使用很少),之后如果Redis缓存中没有命中,就需要查询MySql数据库前先在布隆过滤器中查询是否在MySql有数据。
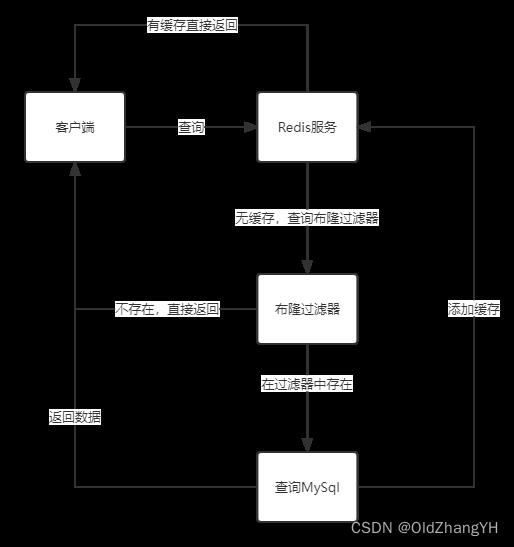
布隆过滤器的特点
- 存在误判的可能性
- 如果数据存在,那么一定返回true
- 查询的时间复杂度是O(k),k为hash函数个数
- k越大,数组长度越大,误判的可能性越低
- 使用位图(二进制数组)所以内存压力较小
缓存击穿
缓存击穿和缓存雪崩类似,也是因为Redis中key过期导致的。只不过缓存击穿是某一个热点的key过期导致的。当有一个热点数据突然过期时,就会导致突然有大量的情况直接落到MySql上,导致MySql直接爆炸!
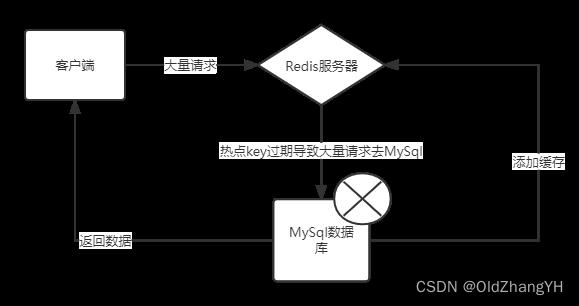
解决方案
主要是两个思路,
- 让那个热点的key不要突然过期
- 不要让大量的请求落到MySql上。
设置热点Key永不过期
简单粗暴,我都不过期了,你就不可能绕开我去访问MySql。但是可能会对Redis内存造成巨大的压力,所以一般会设置一个较长的时间。
使用Redis的分布式锁
既然一瞬间大量请求落到MySql上会导致MySql爆炸!那么就加一点限制,让一时间只有一个相同请求落到MySql上,反正都是查询同一个信息,之后的其他请求就可以去Redis中找了。
以上是关于redis 十五. 缓存穿透 与布隆过滤器原理的主要内容,如果未能解决你的问题,请参考以下文章