Oracle Spatial分区应用研究之四:不同分区粒度+全局空间索引效率对比
Posted 6宇航
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle Spatial分区应用研究之四:不同分区粒度+全局空间索引效率对比相关的知识,希望对你有一定的参考价值。
1、实验目的
在实验之前先回答这样一个问题——对同一份数据使用不同的分区粒度,但均创建全局空间索引,问:它们的全局空间索引一致吗?
怎样算是一致的呢?R-TREE的树结构一致算一致吗?空间索引条目数及大小一致算一致吗?严格的一致,当然是指索引条目数、索引大小、R-TREE树结构完全一致。但经过分析发现,它们的索引条目数、R-TREE树结构是完全一致的,但索引大小有微小的差别。但我们仍然认为它们的全局索引是一致的,这是因为,R-TREE树结构才是决定空间索引是否一致的关键。
基于上述前提条件,思考一个问题:在执行空间查询时,若执行计划的第一步是扫描全局空间索引,这种情况下使用不同分区粒度的表,查询效率是相同的吗?实验之前,我会认为是相同的。因为尽管分区粒度不一样,但执行逻辑完全一致——根据全局空间索引查找匹配的ROWID,根据ROWID返回记录。而ROWID是无差别的,即相同磁盘设备下访问不同ROWID损耗是一样的。但真实情况呢?
2实验数据
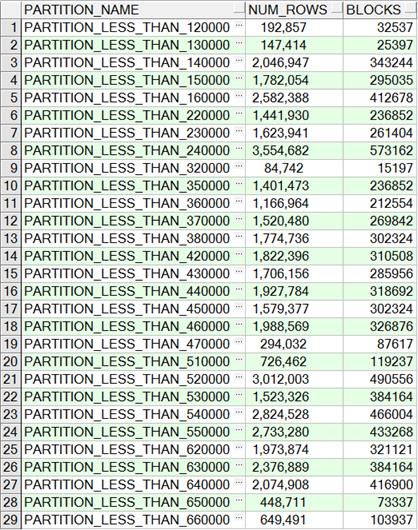
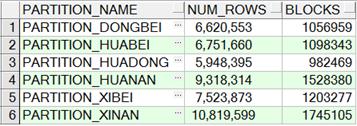
实验数据为全国2531个区县,要素总数为46982394。分别以按县、市、省、区域分区,以及不分区来进行组织。在所有表上均创建全局空间索引。先介绍按省分区、按区域分区相关信息。
按省分区,各分区记录数及blocks:
按区域分区,各分区记录数及blocks:
3实验方法
在1:500、1:2000、1:10000、1:25000、1:50000、1:100000比例尺下,随机从全国范围内选择3个样本范围,作为空间查询时的查询范围。将6*3个样本范围分别与3个实验主体进行空间查询运算,记录每次查询的耗时。
算法统一使用最适合全局空间索引的算法:part_query3。
4实验结果
实验结果如下表:

求每种比例尺3个样本的平均值:
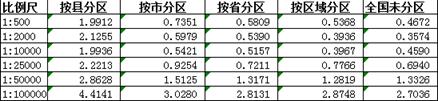
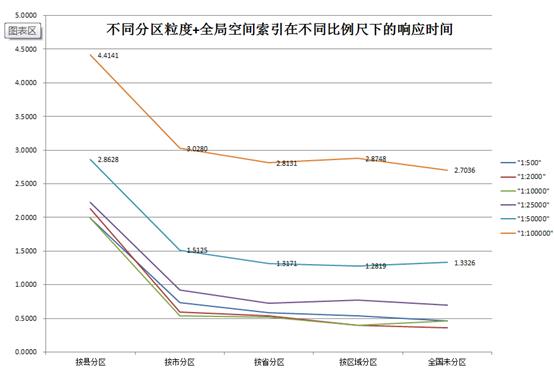
绘制不同分区粒度在不同比例尺下响应时间的折线图。
5实验结论
- 尽管全局空间索引一致,但不同的数据组织方式影响查询效率。从图中可知,过于分散数据(按县分区)将导致性能下降;适度分散对性能影响较小甚至没有影响。
- 在使用全局索引的情况下,未分区效率最高(命中18次中的9次),按区域分区次之(18次命中6次),按省分区又次之(18次命中3次)。
- 按省分区、按区域分区、不分区在全局空间索引下的查询效率相差不大,是否产用分区,产用何种分区,应结合业务场景选择合适的组织方式。
(未完待续……)
以上是关于Oracle Spatial分区应用研究之四:不同分区粒度+全局空间索引效率对比的主要内容,如果未能解决你的问题,请参考以下文章