Paddle OCR, windows/mac安装指南
Posted HarryLi0520
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Paddle OCR, windows/mac安装指南相关的知识,希望对你有一定的参考价值。
前言:
现在网络上有很多百度PaddleOCR的安装教程,但普遍的问题是缺少对整个安装流程框架的讲解,而遇到的问题又五花八门,导致小白安装时容易被绕晕。
本文将以Anaconda--jupyter notebook为例,梳理PaddleOCR的安装框架,同时提供几个常见报错和解决方案,希望能帮助大家高效地成功安装PaddleOCR:
1.官网安装PaddlePaddle
2.下载github上PaddleOCR包
3. install支持PaddleOCR的包
1. 安装PaddlePaddle
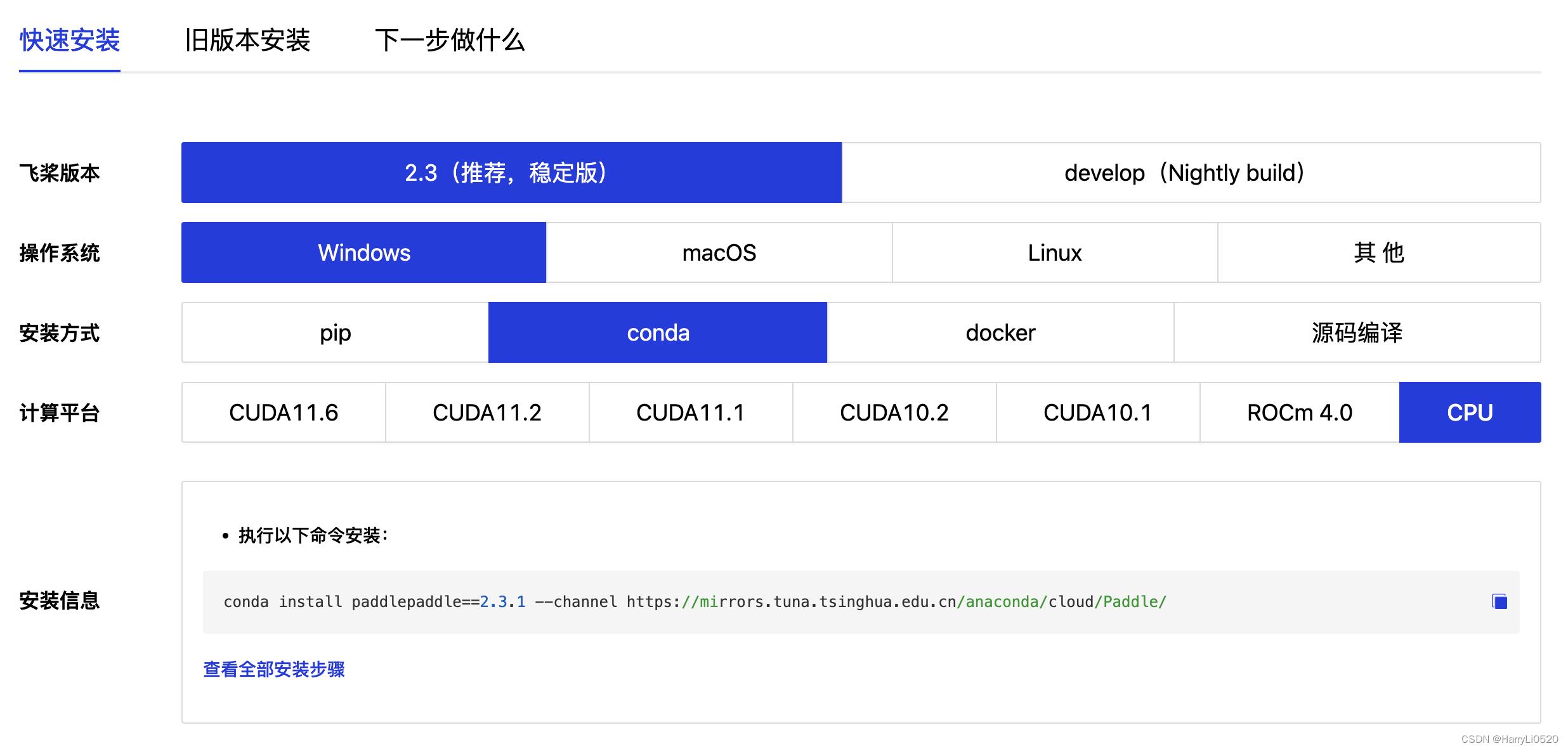
官方快速安装PaddlePaddle
根据自己电脑本次选择windows pip python3 cpu版本的来进行安装
1.确保安装的windows是64位
2.确保python的版本是以下其中之一3.5.1+/3.6+/3.7+,并且是64bit的,不符合的版本下载Paddle异常
python --version以下命令可以输出python是否是64bit和处理器架构
python -c "import platform;print(platform.architecture([0]);print(platform.machine())"确保有python对应的pip,版本9.0.1+
python -m ensurepip
python -m pip --version
4.进行安装paddlepaddle(根据官网选择
#执行以下命令安装(推荐使用百度源)
python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
#或
conda install paddlepaddle==2.3.1 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
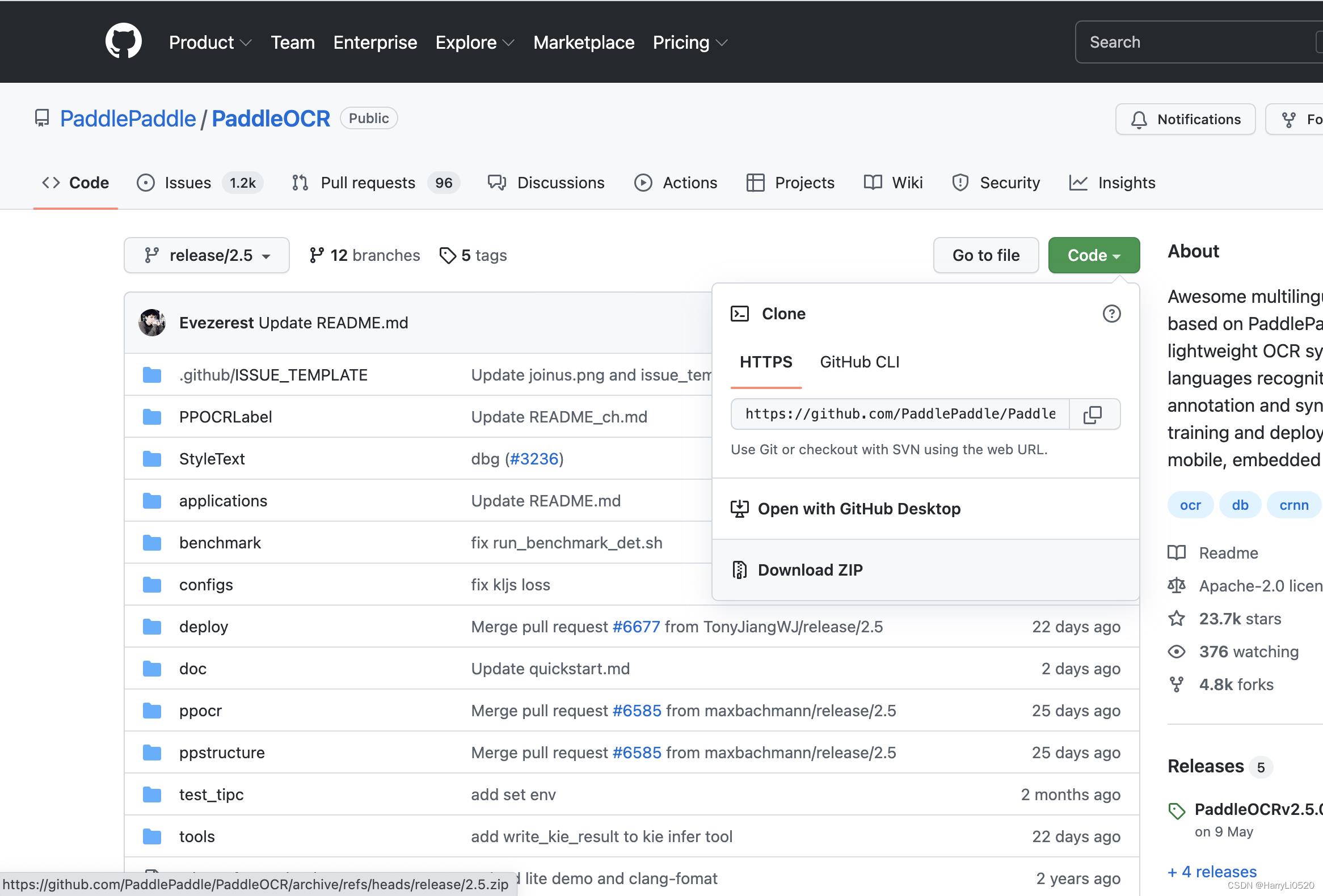
2.下载github上PaddleOCR包
根据项目文档第3步,克隆PaddleOCR代码,本地新建目录后
#推荐
git clone https://github.com/PaddlePaddle/PaddleOCR
#因为网络问题无法pull成功,也可选择使用码云上的托管, 码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先使用推荐方式
git clone https://gitee.com/paddlepaddle/PaddleOCR
也可直接在这里下载zip文件,解压到对应位置
3. install支持PaddleOCR的包
下载github成功后进入PaddleOCR文件
cd PaddleOCR
python -m pip install -r requirements.txt此处易发生的问题:
1. PaddleOCR文档的位置:放在默认目录下即可
2. requirements.txt 文件找不到:用dir列出目录下所有文件,再复制粘贴
此步解释:
install requirement.txt其实是安装的最后一步, 即安装支持PaddleOCR的必要包,其中大部分都在requirements.txt中列出。
通常的报错也是在这步报错,因为有些包安装的问题,需要手动在这里下载。网上已经有很多解决“有些包安装不上”的报错及解决方案,以下为几个常见范例:
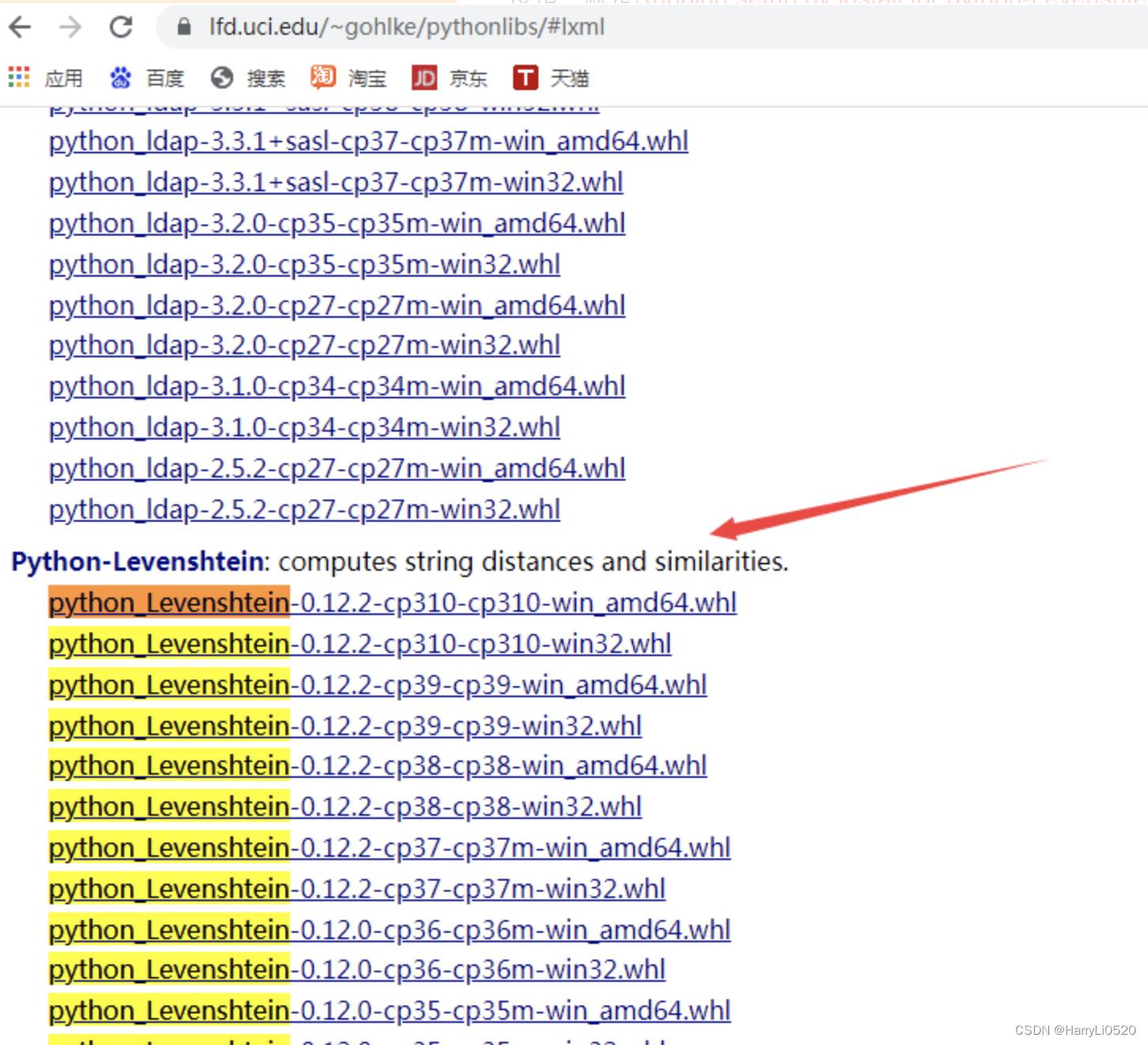
1. shapely包:
官方强调windows环境下,建议从这里下载shapely安装包完成安装, 直接通过pip安装的shapely库可能出现[winRrror 126] 找不到指定模块的问题。
下载和自己电脑,python版本吻合的文件即可

下载好后放到PaddleOCR文件夹里(和requirements.txt同级)并安装(下载其他包的流程都一样
pip install Shapely-1.7.1-cp37-cp37m-win_amd64.whl(根据下载文件的名字改
2. Running setup.py install for python-Levenshtein ... error:
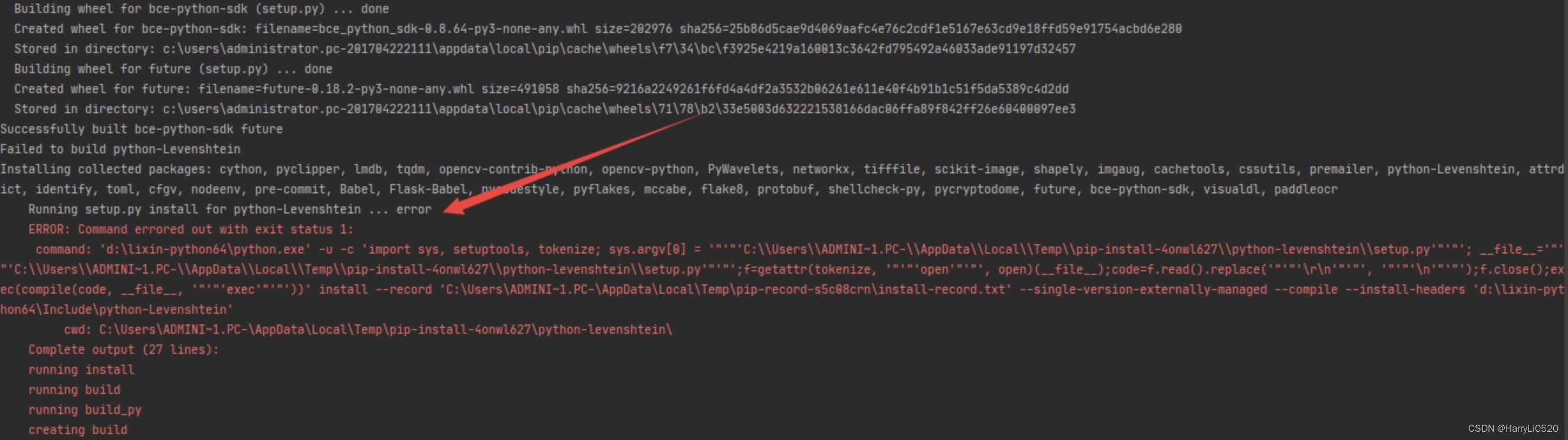
下载并install Python-Levenshtein
注:现在网站上的很多博客有提到安装C++环境的步骤,其实也是为了解决某个python包无法安装的问题,建议采取上述步骤进行安装,比较简单快捷。
4.PaddleOCR的使用
1.在paddle虚拟环境下的jupyter notebook/pycharm
jupyter notebook应把内核切换为paddle(环境名)
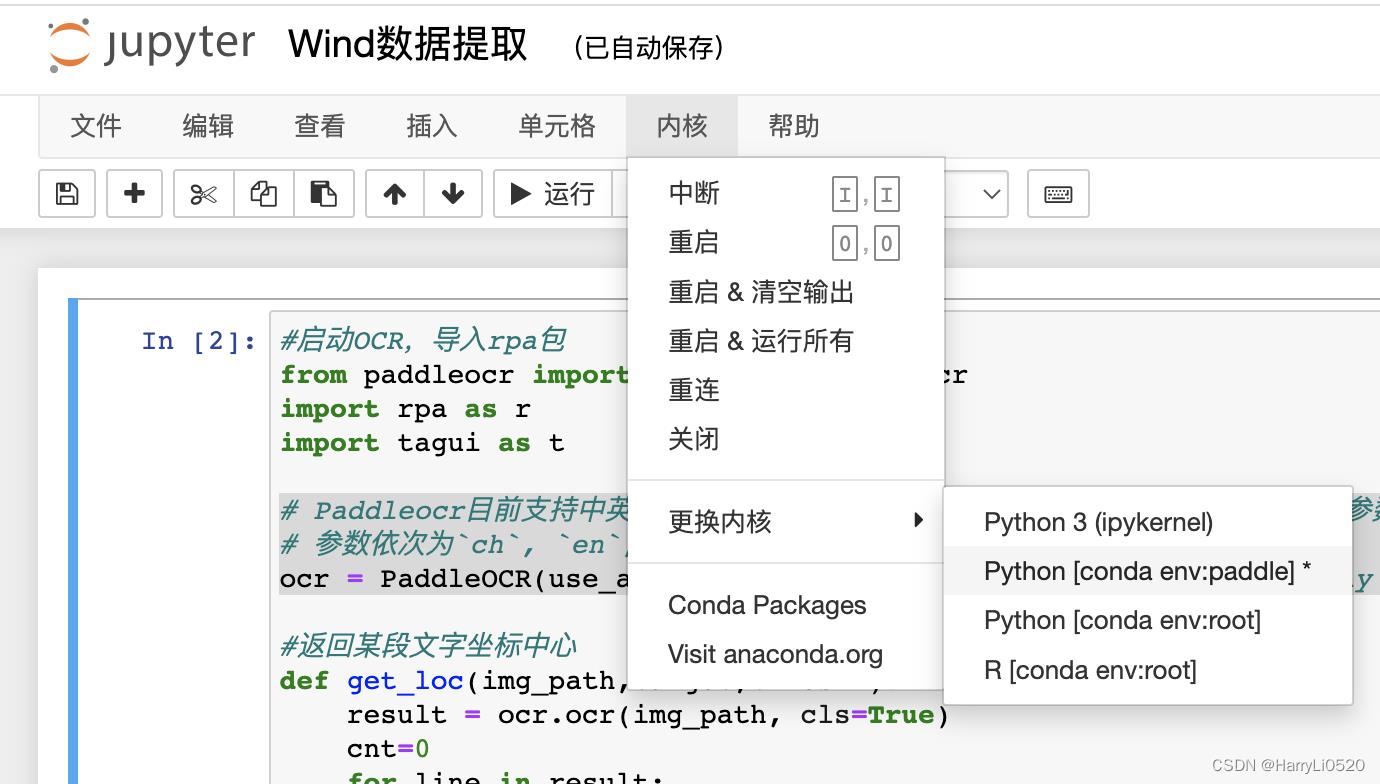
Pycharm同理,具体流程可参考: 利用Anaconda安装pytorch和paddle深度学习环境+pycharm安装---免额外安装CUDA和cudnn(适合小白的保姆级教学)_炮哥带你学的博客-CSDN博客_利用anaconda安装pytorch
2.使用范例:
pip install paddleocrfrom paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = r'C:\\Users\\Administrator.PC-201704222111\\Desktop\\66.png'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
总结
以上就是本次分享的内容,当时在安装paddle ocr时因为没有搞清楚安装的结构,和每个步骤之间的关系,遇到了很多难以解决的问题,所以写了这篇安装指南。
希望可以帮助大家理解安装paddle的几个重要步骤,在查找文中未提到的内容时也能带着清晰的头脑及思路,高效地找到问题的答案!
参考1:PaddleOCR windows10下的安装使用_一路前行_的博客-CSDN博客_paddleocr 安装
参考2: Python|如何正确安装PaddleOCR_写python的鑫哥的博客-CSDN博客_paddleocr安装
(参考2是从另一个角度安装,直接在pip install paddleocr, 然后遇到什么问题解决什么问题,也建议大家看看)
(如果你是Pycharm用户,可以看参考三Pycharm与虚拟环境部分的讲解)
openVINO+paddle基于 Paddle2ONNX实现Paddle-Detection/OCR/Seg导出
【openVINO+paddle】基于 Paddle2ONNX实现Paddle-Detection/OCR/Seg导出
这篇文章所有的代码我都已经跑通。我会提供所有的源代码和数据集和相关文件,我这个用的环境是BML codeLAB ,他的文件路径是/home/work/而不是aistudio的/home/aistudio/这一个路径,所以请小伙伴们开发时注意下路径转化问题,有任何不懂或者出错的地方,欢迎到CSDN搜索翼达口香糖这个账号私聊我。
我已经把代码和数据都上传到aistudio ,想要对照结果或者体验一下的朋友可以直接使用aistudio 在线运行一下,下面是链接 点击打开:
https://aistudio.baidu.com/aistudio/projectdetail/3459413
一般飞桨的部署通过ONNX模型来进行的,所以想要在CPU等上使用飞桨训练好的模型,大多数都需要将模型导出后再进行部署。所以在这个项目中我先提供了一个总体的飞桨动静态的导出演示,然后分别拿我们常见的detection、OCR、Seg为例子做演示,全方位演示模型的导出问题,以便后期的部署和使用。
目录
- 【openVINO+paddle】基于 Paddle2ONNX实现Paddle-Detection/OCR/Seg导出
- paddle动静态模型的ONNX导出(以u2netp为例)
- paddle detection模型的ONNX导出(以YOLO3为例)
- paddleSeg模型的ONNX导出
- PPOCR模型的ONNX导出
1、ONNX介绍
ONNX是一种针对机器学习所设计的一种开源文件格式,用来存储我们训练好的模型。假设一个模型通过学习框架训练好后,我们可以把它存储下来,然后存储的格式可以使用ONNX的这种格式,在模型中模型构造是有向无环的,图里面它有很多的节点,然后每一个节点会有一个或者多个的输入,并且这个节也会有一个或者多个的输出。这些输入和输出就可以构成一副完整的图。每个节点都是都成为一个OP。
有了ONNX模型后,不同的算法架构的模型也可以使用相同的这种文件格式进行存储。
实际中可能遇到这样子一个问题,如果你遇到很好的一个pytorch模型,但是你无法获取他们的数据集,或者没有硬件条件去支撑设备。在这个时候科学那我们就有一个很好的想法,就是说把pytorch这个模型呢,直接迁移过来,然后进行部署就可以解决这个问题。在这里就提供一种新的解决方案,就是我们可以通过ONNX接受的转换格式。首先,我们将想要转换的pytorch模型保存出来,保存成一个ONNX格式,保存之后呢,因为我们是ONNX格式,它可以通过,比如说我们的操作paddleX(paddle的一个工具套件)进行转换。然后就可以转换成我们的一个paddle的一个inference模型。之后就可以通过这个inference模型去进行部署了。

这个是很有利于我们去做研究和部署的。从下面这个图,我们可以看到ONNX支持很多深度学习框架,比如tensorflow、pytorch、caffe、paddlepaddle。同时转化可以把它部署到我们的cpu gpu或者FPGA上上面。

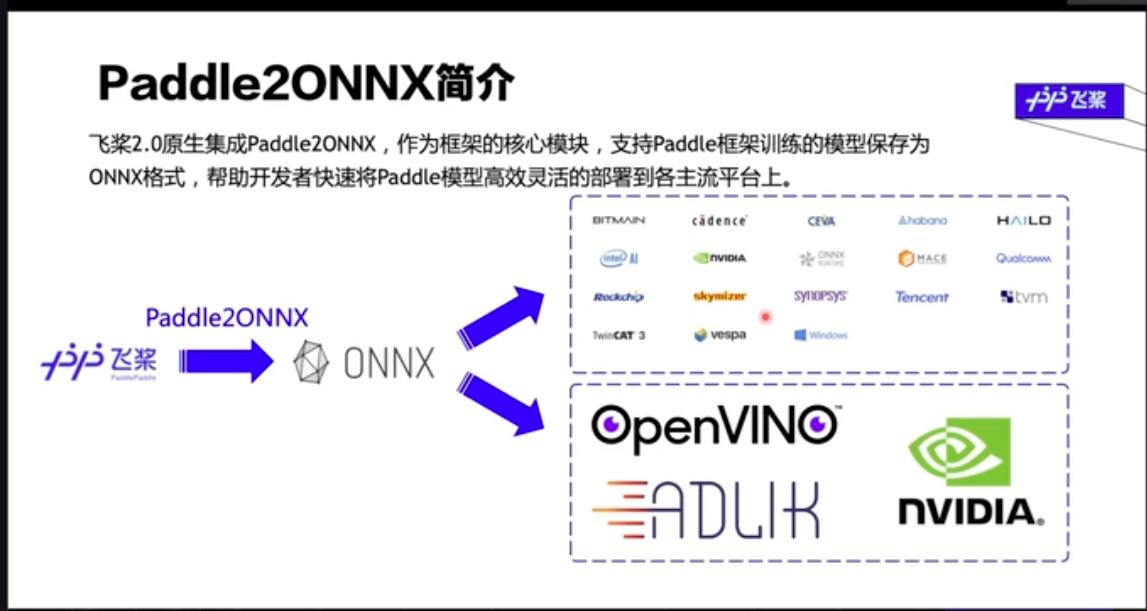
2、paddle2ONNX简介
飞桨是国内最早开源的框架,早就已经和ONNX进行了深入的合作,也开源了paddle2ONNX作为paddle paddle的一个核心模块,然后支持将paddlepaddle框架训练的这个模型直接保存为ONNX格式来帮助我们的开发者快速地将我们的paddle模型高速、高效、灵活地部署到各种主流的平台上。
我们从下面这幅图可以看一下,就是我们的paddlepaddle是作为一个深度学习的学习框架,我们能用大量的数据去训练了一个模型,我们部署可能就说我们要做的一个某个平台上,然后这个平台呢,可能用我们飞桨自带的模型。如果说那个平台不支持这个模型,比如说类似于tensorRT种情况,我们应该怎么办呢?这个时候paddle ONNX就起了很大的作用就可以,首先将要我们的飞桨模型,训练完之后直接导出出来,我们的模型直接导成ONNX格式,然后ONNX可以用模型进行部署进行部署。然后基于这个特点可以直接把我们的paddle都收到很多多不同的平台上,用各种不同的一些形式来进行部署。也就是说,ONNX是直接使用paddle模型到到各种平台上的一个桥梁。
3、动静态图导出
动态导出
我们可以用几行简单的命令行,就可以把我们的这个paddle模型了导出来生成ONNX一个模型。左侧是一个动态导出的例子,首先我们用paddle的API进行组网,比如说我们组了一个模型网络。然后我们再根据我们网络的输入,给他随机定一个输入。然后就只需要一行(export)那里,就就可以进行模型导出。这个括号内部,我们需要传入我们的模型,还有我们导出来的这个onnx这个文件名称,还有根据他的输出输入,他就会运行里面相关的一些一些逻辑,然后把我们的模型导出导出成ONNX格式。
静态导出
上面是我们直接用2.0之后动态图组网的一种导出方式,那如果就说,如果我们已经把一个模型已经导出来了,导出成一个inference就是静态导出的方式。我们就支持直接用最下方的这个命令行的方式直接去进行转换,下面就是一个转换的一个命令行,我们只需要指定我们转换的模型、它的地址、还有这个模型他的模型文件的名称、还有她参数文件的名称,以及我们需要导入onnx文件的一个名字,那我们就可以很方便进行模型转化。

现在飞桨已经支持了很多开源的很多的一些优秀的算法,比如说飞桨的NLP、Seg、object Detection、class、OCR等等。假如说有一天也看到paddle有个模型,然后想把它用到你的项目里面,就可以支持ONNX进行部署,转换之后就可以把它部署到我们的各种平台上。
4、Paddle2ONNX支持模型

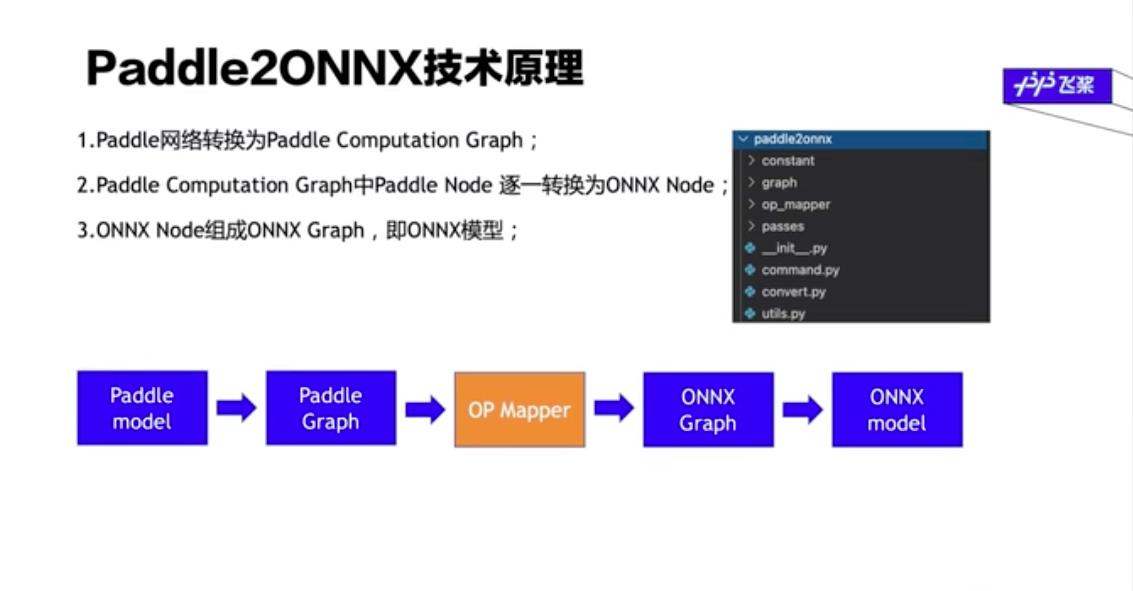
5、paddle2ONNX技术原理
总的来说有三个主要的步骤吧,首先呢,第一步是用paddle 2.0之后的API进行一个组网的,一个网络的组成包括有一些卷积层、或者全连接层进行组成网络,然后我们我们第一步是把它转换成paddle的一个计算图,代码结构由这些这些计算图表示,包括paddle的计算图或者ONNX计算图都会实现在我们的这个graph下面实现。然后这是第一步,就是转化得到paddle的计算图
我们的第二步就是最重要的一步就是OP匹配,他是做一个什么工作呢?就是我们paddle的计算图,上面提到过,其实他是一个有向无环图里面会有很多那些节点,然后第二步我们就是把这些OP进行逐一的转换,就根据他的拓扑排序,从头到尾依次进行转换,然后通通把它转完成ONNX的node,那这些node就是我们的ONNX模型。当然,在我们导出成一个模型之前呢,我们还需要对这个模型进行检测,比如说里面有没有一些没有用的节点等等,这些检测来检测我们这个模型是否是合理的。假如说这个模型是合理的话,那么它就可以导出出来,拼接生成我们的ONNX的模型。其中我们这个paddle2ONNX这个项目里面最重要的一部分就是我们的这个op mapper,它实现了就是paddle node到onnx node 的一个转换,是整个工程的一个核心的部分。
6、OP流程开发
现在paddle可以进行转化的模型还不算事非常多,很多很好的模型无法进行部署使用,所以还需要开发者进行新OP的开发流程。
这就是最核心的op mapper开发。比如说说如果遇到一个op不支持,我们应该怎么去进行新op的开发。我们平时使用的paddle API进行转化时,他其实是真正下沉到代码层,对计算图里面的API转换了。什么是API呢?API指的是我们和用户交互的一些接口,用户可以通过这些API直接去调用我们paddle里面的op,这个API有多个或者一个OP去组成一个模型网络。
在调用转化成onnx时,如果是选择官方没开发的部分,导出时肯定会因为这些API里面会有不支持的一些OP,然后导出的时候会提示说到底里面是哪一个OP不支持。
所以我们需要手动地编写代码,去理清这个转化关系。这个需要补充一点,两个模型的OP有可能不是一一对应的关系,但是也是可能由有多个OP去进行组合,这个时候需要开发者去进行开发,但是这个难度太高太复杂,所以需要进行一个项目来开发,下面拿来做例子的都不会涉及OP开发,都是可以直接进行转化的例子。

在做这次开发时,主要参考了以下这些资料、视频,如果有讲的不清楚的地方可以翻阅这些反复斟酌。
-
https://aistudio.baidu.com/aistudio/projectdetail/3458732?forkThirdPart=1
-
https://aistudio.baidu.com/aistudio/projectdetail/1904306
-
https://aistudio.baidu.com/aistudio/projectdetail/2187665?channelType=0&channel=0
-
https://aistudio.baidu.com/aistudio/projectdetail/1637670?channelType=0&channel=0
-
https://aistudio.baidu.com/aistudio/projectdetail/2250546?channelType=0&channel=0
-
https://aistudio.baidu.com/aistudio/projectdetail/2254777?channelType=0&channel=0
-
https://www.bilibili.com/video/BV1aq4y1G7Ma?from=search&seid=14303610212269096609&spm_id_from=333.337.0.0
paddle动静态模型的ONNX导出(以u2netp为例)
1、环境准备
https://aistudio.baidu.com/aistudio/projectdetail/3459413
安装依赖
这里首先要安装的是pycocotools、paddle2onnx、onnxruntime,大家对第二个已经不陌生,第三个是我们到时候部署验证的时候会使用到onnxruntime,第一个是pycocotools(python api tools of COCO)用来处理COCO的数据集。这里很多朋友会看到第一步和第二步为什么不一起安装,这个强调一下,一定不能一起。一定要制定onnx的版本,他需要小于1.9.0。很多分享的开源项目都是直接安装了,那是因为他们那时候版本更新的没这么快还可以支持。
!pip install pycocotools paddle2onnx onnxruntime
!pip install onnx==1.9.0
接下里你需要下载paddle2onnx的代码文件以及将他们初始化,由于我使用的BML,所以每次只要你关机再重新登录的话就需要重新跑一步这些环境的配置代码,否则就会因为环境缺失而报错。
!git clone https://github.com/paddlepaddle/paddle2onnx --depth 1
!cd ~/paddle2onnx && python setup.py install
提前安装一下GPU环境吧,避免到时候出错,后面我也还会安装一次。
!python -m pip install paddlepaddle-gpu==2.1.3.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
解压模型相关文件,由于是第一个项目,我直接配置好了相关的文件以及环境,你只需要在百度网盘上下载这个压缩包,如何解压到这个文件同一目录下即可。或者运行这个项目,以及上传到work中。百度网盘链接:链接:https://pan.baidu.com/s/1k7rRTGoGGyLRQdEU2SnYvg 密码:mp95 文件失效或者有任何问题可以在CSDN找翼达口香糖私聊我。
!unzip wenjiang.zip
2、动态图模型导出ONNX协议
使用Paddle2.0构建的动态图模型,通过调用paddle.onnx.export来实现ONNX模型的快速导出
大致的原理是动态图->静态图->ONNX模型,接下来就通过代码来演示一下导出的流程
import os
import time
import paddle
# 从模型代码中导入模型
from u2net import U2NETP
# 实例化模型
model = U2NETP()
# 加载预训练模型参数
model.set_dict(paddle.load('u2netp.pdparams'))
# 将模型设置为评估状态
model.eval()
# 定义输入数据
input_spec = paddle.static.InputSpec(shape=[None, 3, 320, 320], dtype='float32', name='image')
# ONNX模型导出
paddle.onnx.export(model, 'u2netp', input_spec=[input_spec], opset_version=12)
3、静态图模型导出ONNX协议
除了动态图模型可以导出为ONNX模型,静态图的推理模型当然也可以转换为ONNX模型。
通过命令行调用如下命令即可完成转换,更多命令行参数使用介绍,请移步Github主页。
]
!paddle2onnx \\
--model_dir u2netp \\
--model_filename __model__ \\
--params_filename __params__ \\
--save_file u2netp_static.onnx \\
--opset_version 12
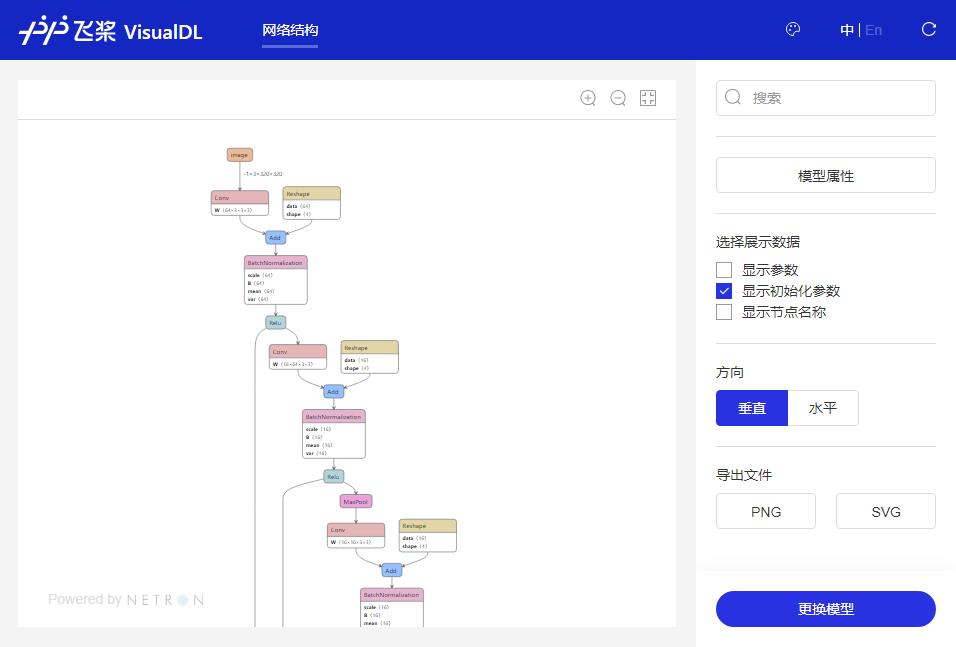
4、模型可视化
通过VisualDL工具可以轻松的进行模型结构的可视化查看。
在AIStudio平台上,可点击左侧 可视化->选择模型文件,选择刚才保存后缀为.onnx的模型文件。
然后启动服务即可查看模型的计算图结构和模型的相关信息。


paddle detection模型的ONNX导出(以YOLO3为例)
1、环境准备
克隆 PaddleDetection 代码
!git clone https://gitee.com/PaddlePaddle/PaddleDetection.git -b develop
安装依赖和GPU环境
! pip install -r PaddleDetection/requirements.txt
!python -m pip install paddlepaddle-gpu==2.1.3.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
2、导出模型
这里使用 PaddleDetection 静态图版本作为演示
模型选择预训练的 YOLO v3 行人检测模型
%cd ~/PaddleDetection/static/
!python tools/export_model.py -c contrib/PedestrianDetection/pedestrian_yolov3_darknet.yml --output_dir ~/inference_model
3、模型转换
这里使用 Paddle2ONNX 来转换模型
%cd ~
!paddle2onnx \\
--model_dir inference_model/pedestrian_yolov3_darknet \\
--model_filename __model__ \\
--params_filename __params__ \\
--save_file inference_model/pedestrian_yolov3_darknet_onnx/inference.onnx \\
--opset_version 12 \\
--enable_onnx_checker True
!cp inference_model/pedestrian_yolov3_darknet/infer_cfg.yml inference_model/pedestrian_yolov3_darknet_onnx
4、模型测试
使用 ONNXRuntime 测试时候可以正常加载模型
import os
import onnxruntime
def load_onnx(model_dir):
model_path = os.path.join(model_dir, 'inference.onnx')
session = onnxruntime.InferenceSession(model_path)
input_names = [input.name for input in session.get_inputs()]
output_names = [output.name for output in session.get_outputs()]
return session, input_names, output_names
session, input_names, output_names = load_onnx('inference_model/pedestrian_yolov3_darknet_onnx')
print(input_names, output_names)
paddleSeg模型的ONNX导出
paddleSeg简介
paddleseg release2.0版本提供了50+的高质量预训练模型,支持15+主流分割网络,提供了业界的SOTA模型OCRNet,很好的提升了产品易用性。
PaddleSeg是基于飞桨PaddlePaddle开发的端到端图像分割开发套件,涵盖了高精度和轻量级等不同方向的大量高质量分割模型。通过模块化的设计,提供了配置化驱动和API调用两种应用方式,帮助开发者更便捷地完成从训练到部署的全流程图像分割应用。
1、环境准备
安装PaddleSeg
! pip install paddleseg
下载PaddleSeg代码
! git clone https://gitee.com/paddlepaddle/PaddleSeg.git
2、训练模型
! python PaddleSeg/train.py --config PaddleSeg/configs/quick_start/bisenet_optic_disc_512x512_1k.yml --do_eval \\
--use_vdl --save_interval 200 --save_dir output
3、模型验证
当保存完模型后,我们可以通过PaddleSeg提供的脚本对模型进行评估
! python PaddleSeg/val.py \\
--config PaddleSeg/configs/quick_start/bisenet_optic_disc_512x512_1k.yml \\
--model_path output/iter_1000/model.pdparams
4、模型预测
当保存完模型后,可以通过PaddleSeg提供的脚本对模型进行预测,同时对结果进行可视化,查看分割效果。
–model_path output/iter_1000/model.pdparams 表示选择模型路径 --image_path data/optic_disc_seg/JPEGImages/H0003.jpg 表示选择预测的图片,如果次时候image_path中有多张图片,也可实现全部预测 --save_dir output/result 表示预测保存的结果地址
! python PaddleSeg/predict.py --config PaddleSeg/configs/quick_start/bisenet_optic_disc_512x512_1k.yml \\
--model_path output/iter_1000/model.pdparams \\
--image_path data/optic_disc_seg/JPEGImages/N0093.jpg \\
--save_dir output/result
5、模型导出
PaddleSeg提供了一键动转静的功能,即将训练出来的动态图模型文件转化成静态图形式。
结果文件
output
├── deploy.yaml # 部署相关的配置文件
├── model.pdiparams # 静态图模型参数
├── model.pdiparams.info # 参数额外信息,一般无需关注
└── model.pdmodel # 静态图模型文件
! python PaddleSeg/export.py \\
--config PaddleSeg/configs/quick_start/bisenet_optic_disc_512x512_1k.yml \\
--model_path output/iter_1000/model.pdparams
6、使用paddle2onnx将paddle模型格式转化到ONNX模型格式。
! paddle2onnx --model_dir ./output/ \\
--model_filename model.pdmodel \\
--params_filename model.pdiparams \\
--save_file segonnx/model.onnx \\
--opset_version 11
7、ONNX模型的验证
import onnx
# onnx_file = save_path + '.onnx'
# onnx_file ='onnx-model/detectionmodel.onnx'
save_path = 'segonnx/'
onnx_file = save_path + 'model.onnx'
onnx_model = onnx.load(onnx_file)
onnx.checker.check_model(onnx_model)
print('The model is checked!')
当然,这里你也可以使用上面的detection的模型来检测一下,也是没有问题的。
import onnx
# onnx_file = save_path + '.onnx'
# onnx_file ='onnx-model/detectionmodel.onnx'
save_path = 'inference_model/pedestrian_yolov3_darknet_onnx/'
onnx_file = save_path + 'inference.onnx'
onnx_model = onnx.load(onnx_file)
onnx.checker.check_model(onnx_model)
print('The model is checked!')
PPOCR模型的ONNX导出
PP-OCR简介
PP-OCR作为Paddle推出的OCR模型库,拥有高质量预训练模型,准确的识别效果。为了更好的将PP-OCR部署到不同的硬件平台,本教程使用Paddle2ONNX将PP-OCR检测、方向分类以及文字识别模型导出为ONNX。
整个教程主要包括以下几个环节:配置环境,分别导出PP-OCR的检测、方向分类以及文字识别的inference模型,然后使用Paddle2ONNX将inference模型转换为ONNX协议。
1、配置环境
下载OCR代码
!git clone https://gitee.com/PaddlePaddle/PaddleOCR.git
可能有朋友觉的这个代码有点奇怪,因为一般只要执行第一步就可以了。但是我发现就没办法下载完,版本没办法匹配,所以你能够只执行第二行的代码就可以。如果不行就打开paddleOCR,打开这个requirements.txt,删掉这个opencv-contrib-python ,保存退出再执行第三行命令
%cd /home/work/PaddleOCR
!pip install -r requirements.txt
!pip install opencv-contrib-python==4.2.0.32
初始化OCR,配置环境
!cd /home/work/PaddleOCR && python setup.py install
2、导出PP-OCR的inference模型
导出检测(det),方向分类(cls)和文字识别(rec)模型。 运行export_ocr.sh,并指定PaddleOCR的路径和导出模型保存的路径。 export_ocr.sh脚本我已经把内部的代码放在下面了,你只需要在自己的电脑创建一个txt改名sh,复制以下进去上传。
ppocr_path=$1
model_save_dir=$2
wget -P ~/ch_lite/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar && tar xf ~/ch_lite/ch_ppocr_mobile_v2.0_cls_train.tar -C ~/ch_lite/
wget -P ~/ch_lite/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar && tar xf ~/ch_lite/ch_ppocr_server_v2.0_det_train.tar -C ~/ch_lite/
wget -P ~/ch_lite/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_train.tar && tar xf ~/ch_lite/ch_ppocr_server_v2.0_rec_train.tar -C ~/ch_lite/
cd $ppocr_path
python3 tools/export_model.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml -o Global.pretrained_model=/home/aistudio/ch_lite/ch_ppocr_server_v2.0_rec_train/best_accuracy Global.load_static_weights=False Global.save_inference_dir=$model_save_dir/rec_crnn/
python3 tools/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml -o Global.pretrained_model=/home/aistudio/ch_lite/ch_ppocr_server_v2.0_det_train/best_accuracy Global.load_static_weights=False Global.save_inference_dir=$model_save_dir/det_db/
python3 tools/export_model.py -c configs/cls/cls_mv3.yml -o Global.pretrained_model=/home/aistudio/ch_lite/ch_ppocr_mobile_v2.0_cls_train/best_accuracy Global.load_static_weights=False Global.save_inference_dir=$model_save_dir/cls/
rm -rf ~/ch_lite
然后切换到正确路径
%cd /home/work/
!sh export_ocr.sh PaddleOCR/ /home/work/inference_model/paddle/
3、将inference模型转换为ONNX协议
使用Paddle2ONNX将inference模型转换为ONNX协议。
!paddle2onnx -m /home/work/inference_model/paddle/cls/ --model_filename inference.pdmodel --params_filename inference.pdiparams -s /home/work/inference_model/onnx/cls/model.onnx --opset_version 11
!paddle2onnx -m /home/work/inference_model/paddle/rec_crnn/ --model_filename inference.pdmodel --params_filename inference.pdiparams -s /home/work/inference_model/onnx/rec_crnn/model.onnx --opset_version 11
到这里你就熟练掌握了ONNX的转化了,你可以更具不同的框架对所需要的模型进行转化。但是针对算OP转化,你可以参考官方文档。
以上是关于Paddle OCR, windows/mac安装指南的主要内容,如果未能解决你的问题,请参考以下文章