Hadoop 开发基础与进阶
Posted stackupdown
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop 开发基础与进阶相关的知识,希望对你有一定的参考价值。
Hadoop是一个用于部署计算密集型分布式系统的框架,最早是根据谷歌公司发表的MapReduce计算框架和GFS谷歌文件系统完成的。谷歌内部的系统跟hadoop不是同一个系统。
由于谷歌的贡献,工业界模仿开发了一些分布式应用,如HBase对应NoSQL列数据库,类似谷歌公司BigTable。Apache Hive是构建于hadoop之上的数据仓库,通过一种类SQL语言HiveQL为用户提供数据的归纳、查询和分析等功能;Hive最初由Facebook贡献。Apache ZooKeeper:分布式锁设施,提供类似Google Chubby的功能,由Facebook贡献。
hadoop的计算框架
hadoop的计算框架是MapReduce框架,可以参见下面的文章。
http://www.cnblogs.com/sharpxiajun/p/3151395.html
MapReduce可以针对海量数据进行任务分发,将其分散到特定的主机上进行计算最后汇总结果。不是所有的算法都可以用MapReduce来改写成分布式算法, 要视面对的问题而定。
要执行MapReduce,需要下载hadoop的jar包, 在org.apache.hadoop.mapreduce中可以找到待改写的类。利用已有的Mapper和Reducer可以填充自己的代码,写出核心的数据处理程序。
框架里的类
hadoop的基本数据类型:与boolean,int,byte,long,double(float), 对应的各种类型
自定义数据类型:需要实现Writable函数
1.继承Reducer和Mapper的两种类:
了解mapper的两个键值,reducer的两个键值
Reducer 的泛型参数类型按顺序为输入key, 输入value, 输出key, 输出value来写
继承格式:
public class newClassName extends Reducer<Text, LongWritable, Text, LongWritable> { protected void reduce(Param1, Param2, …){} }
2.作业提交类Submit不需要继承,只要写出符合要求的Main函数就OK
public static void main(String[] args)throws IOException { }
3. 设定JobTracker






Eclipse开发
如果你要在Ubuntu下开发但是缺少调试工具,效率可能会很低。一般在搭建好集群后,都要在IDE下进行开发,可以参考:
Hadoop Eclipse 开发
http://www.cnblogs.com/justinzhang/p/4261851.html
Eclipse调用hadoop2运行MR程序
http://www.mamicode.com/info-detail-1155245.html
注意导入包的时候Add jars和Add External Jars的区别:前者会copy文件,后者只是根据引用调用包
在eclipse下安装hadoop插件,以新建MapReduce项目,
然后用eclipse导入一些外部的jar包,这些jar包是Hadoop/share/下的jar包,再新建一个Hadoop/Map Reduce的项目。
MapReduce项目需要连接服务器(真实的Ubuntu服务器或CentOS之类的),需要连接IP,端口,可能还有SSH。参考的资料要有hadoop的安装包,还有jar包(不一样?)。
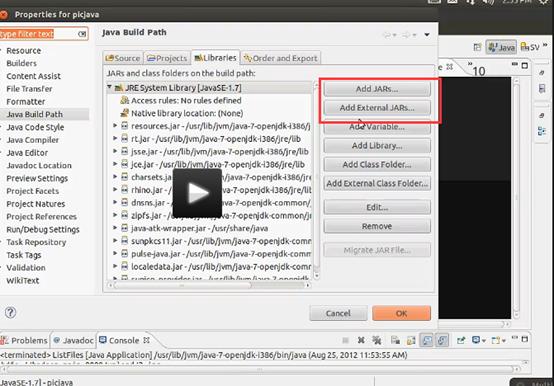
数据的上传
远程copy和push
在Ubuntu下:
* 复制文件:
* 命令格式:
scp local_file remote_username@remote_ip:remote_folder
或者
scp local_file remote_ip:remote_folder
第1,2个指定了用户名,命令执行后需要再输入密码,第1个仅指定了远程的目录,文件名字不变,第2个指定了文件名;
第3,4个没有指定用户名,命令执行后需要输入用户名和密码,第3个仅指定了远程的目录,文件名字不变,第4个指定了文件名;
* 例子:
scp /home/space/music/1.mp3 root@www.cumt.edu.cn:/home/root/others/music
scp /home/space/music/1.mp3 www.cumt.edu.cn:/home/root/others/music
* 复制目录:
* 命令格式:
scp -r local_folder remote_username@remote_ip:remote_folder
或者
scp -r local_folder remote_ip:remote_folder
第1个指定了用户名,命令执行后需要再输入密码;
第2个没有指定用户名,命令执行后需要输入用户名和密码;
* 例子:
scp -r /home/space/music/ root@www.cumt.edu.cn:/home/root/others/
scp -r /home/space/music/ www.cumt.edu.cn:/home/root/others/
上面命令将本地 music 目录复制到远程 others 目录下,即复制后有远程有 ../others/music/ 目录
======
从远程复制到本地,只要将从本地复制到远程的命令的后2个参数调换顺序即可;
scp 本地用户名 @IP地址:文件名1 远程用户名@IP地址:文件2
[ 本地用户名 @IP 地址 :] 可以不输入
可能有用的几个参数 :
-v 和大多数 linux 命令中的 -v 意思一样 , 用来显示进度 . 可以用来查看连接 , 认证 , 或是配置错误 .
-C 使能压缩选项 .
-P 选择端口 . 注意 -p 已经被 rcp 使用 .
-4 强行使用 IPV4 地址 .
-6 强行使用 IPV6 地址 .
开发实例
Hadoop k-means 算法实现
http://blog.csdn.net/fansy1990/article/details/8028546
hadoop示例程序Grep分析
http://www.cnblogs.com/york-hust/archive/2011/07/20/2111310.html
数据挖掘:用R解析Mahout用户推荐协同过滤算法(UserCF)
http://www.itwendao.com/article/detail/65961.html
Starfish http://www.cs.duke.edu/starfish/
快速测试
http://www.infoq.com/cn/articles/MapReduce-Best-Practice-1 :
某周一和搭档(结对编程)决定重构一个完成近10项统计工作的MapRuduce程序,这个MapReduce(从Spring项目移植过来的),因为依赖Spring框架(原生Spring,非Spring Hadoop框架),导致性能难以忍受,我们决定将Spring从程序中剔除。重构之前程序运行是正确的,所以我们要保障重构后运行结果与重构前一致。搭档说,为什么我们不用TDD来完成这个事情呢?于是我们研究并应用了MRunit,令人意想不到的是,重构工作只用了一天就完成,剩下一天我们进行用findbug扫描了代码,进行了集成测试。这次重构工作我们没有给程序带来任何错误,不但如此我们还拥有了可靠的测试和更加稳固的代码。这件事情让我们很爽的同时,也在思考关于MapReduce开发效率的问题,要知道这次重构我们之前评估的时间是一周,我把这个事情分享到EasyHadoop群里,大家很有兴趣,一个朋友问到,你们的评估太不准确了,为什么开始不评估2天完成呢?我说如果我们没有使用MRUnit,真的是需要一周才能完成。因为有它单元测试,我可以在5秒内得到我本次修改的反馈,否则至少需要10分钟(编译、打包、部署、提交MapReduce、人工验证结果正确性),而且重构是个反复修改,反复运行,得到反馈,再修改、再运行、再反馈的过程,MRunit在这里帮了大忙。
Hadoop的版本兼容性
如果你不幸地参考了《Hadoop实战》,你可能会突然掉进api的坑里。事实上,Hadoop在本书出版以后已经达到了2.0以后了,而本书还在1.0之前,有些类已经删除掉了。所以你最好还是先搭好一个可以用的环境,然后在该环境下照着一些样例进行学习。
References
http://lucene.apache.org/hadoop
http://labs.google.com/papers/mapreduce.html
教程:
https://www.tutorialspoint.com/hadoop
API查询
http://hadoop.apache.org/docs/current/api/index.html
https://www.eclipse.org/recommenders/manual/ 开发者参考文档
http://www.powerxing.com/hadoop-build-project-using-eclipse/ 个人博客
http://wenhai.iteye.com/blog/2288571 Win7+Eclipse+Hadoop2.6.4开发环境搭建
以上是关于Hadoop 开发基础与进阶的主要内容,如果未能解决你的问题,请参考以下文章