Z-score和T-score的区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Z-score和T-score的区别相关的知识,希望对你有一定的参考价值。
一、指代不同
1、Z-score:也叫标准分数是一个数与平均数的差再除以标准差的过程。
2、T-score:是统计中求相对位置数量的一个概念。
二、用处不同
1、Z-score:是一个观测或数据点的值高于被观测值或测量值的平均值的标准偏差的符号数。
2、T-score:求相应对位置数量时,为避免Z分数中小数点和负值情况,常使用T分数。
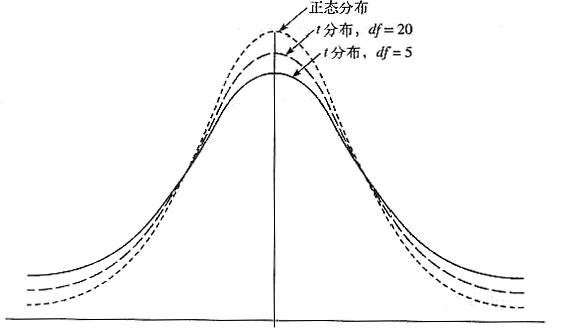
三、特点不同
1、Z-score:z分数能够真实的反应一个分数距离平均数的相对标准距离。如果我们把每一个分数都转换成z分数,那么每一个z分数会以标准差为单位表示一个具体分数到平均数的距离或离差。
2、T-score:T分数是原始分数的导出分数。把原始分数转换成标准化分数为线性转换,Z分数与原始分数的分布形状相同,原始分数为正态分布,则Z分数也为正态分布。
参考资料来源:百度百科-T分数
参考资料来源:百度百科-Z分数
参考技术AZ-score与T-score的区别
1、定义上的区别:在T-score的情况下,平均值或正常值为50,标准差为10。此得分高于或低于50
的人会高于或低于平均值。Z-score的平均值为0,要考虑高于平均水平,一个人必须获得超过0 Z-
score。
2、使用上的区别:当样本较大(n大于30)时,通常计算Z-score,但当样本小于30时,优选T-
score。这是因为你没有很好地估计一个小样本的人口标准差,这就是T-score更好的原因。
扩展资料:
在统计中,标准分数是的符号小数标准偏差,通过该观察或值数据点是上述平均的被观察或测量什
么值。高于平均值的观察值具有正标准分数,而低于平均值的值具有负标准分数。
它是通过从单个原始分数中减去总体均值然后将差异除以总体标准差来计算的。这是一个无量纲的
数量。此转换过程称为标准化或标准化(但是,“标准化”可以指多种类型的比率; 有关更多信息,
请参阅标准化)。
标准分数也称为z-values, z-scores, normal scores, and standardized variables。它们最常用于
将观察结果与理论偏差进行比较,例如标准正常偏差。
计算z-score需要知道数据点所属的完整人口的平均值和标准差; 如果只有一个来自总体的观察样
本,则样本均值和样本标准差的类比计算得到t-statistic。
参考技术B 二者的区别:Z-score 是标准正态分布的坐标值,T-score是在整体标准差不明的情况下,通过样本标准差来估测置信区间的T分布的坐标值。
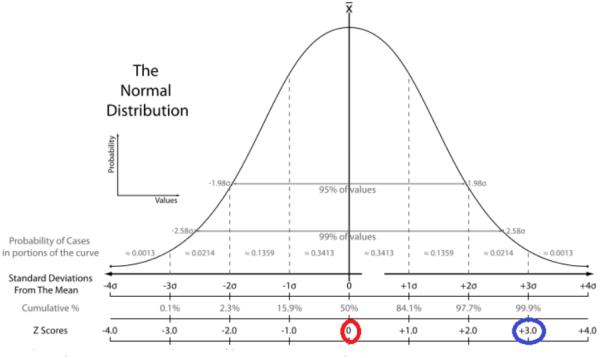
标准正态分布的坐标值,是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。期望值μ=0,即曲线图象对称轴为Y轴,标准差σ=1条件下的正态分布,记为N(0,1)。正态分布的概率密度函数曲线呈钟形,因此人们又经常称之为钟形曲线。我们通常所说的标准正态分布是位置参数均数为0, 尺度参数:标准差为1的正态分布(见右图中绿色曲线)。
t分布(t-distribution)是一种统计分布。t分布曲线形态与n(确切地说与自由度v)大小有关。与标准正态分布曲线相比,自由度v越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度v愈大,t分布曲线愈接近正态分布曲线,当自由度v=∞时,t分布曲线为标准正态分布曲线。 参考技术C Z-score 是标准正态分布的坐标值,T-score是在整体标准差不明的情况下,通过样本标准差来估测置信区间的T分布的坐标值。两者所应用于的环境不同。但都可以用来估测可能性。
如何创建一个应用 z-score 和交叉验证的 scikit-learn 管道?
【中文标题】如何创建一个应用 z-score 和交叉验证的 scikit-learn 管道?【英文标题】:How to create a scikit-learn pipeline that applies z-score and cross-validation? 【发布时间】:2020-09-04 07:43:11 【问题描述】:我正在尝试在交叉验证的每个步骤中标准化我的数据,我遇到了这个question
按照建议,我查看了 scikit-learn 文档并找到了这个示例:
from sklearn.pipeline import make_pipeline
clf = make_pipeline(preprocessing.StandardScaler(), svm.SVC(C=1))
cross_val_score(clf, X, y, cv=cv)
这看起来确实像我想要实现的,但是,我的意图是使用 z-scorer 而不是 StandardScaler,所以我尝试了这个:
clf = make_pipeline(stats.zscore(), DecisionTreeClassifier())
但我收到一条错误消息:
TypeError: zscore() missing 1 required positional argument: 'a'
zscore() 的参数应该是什么?
【问题讨论】:
【参考方案1】:欢迎来到堆栈溢出!在sklearn 管道中有几种使用自定义功能的方法——我认为FunctionTransformer 可能适合您的情况。
创建一个使用zscore 的转换器并将转换器传递给make_pipeline,而不是直接调用zscore。
我希望这会有所帮助!
【讨论】:
这正是我想要的,非常感谢!以上是关于Z-score和T-score的区别的主要内容,如果未能解决你的问题,请参考以下文章