提取Word文档中的Excel附件并识别文件名保存
Posted 小小明-代码实体
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了提取Word文档中的Excel附件并识别文件名保存相关的知识,希望对你有一定的参考价值。

📢作者: 小小明-代码实体
📢博客主页:https://blog.csdn.net/as604049322
📢欢迎点赞 👍 收藏 ⭐留言 📝 欢迎讨论!
之前我在《Python读取Word文档中的Excel嵌入文件》一文中演示了如何提取Word文档中的Excel附件数据,链接:https://xxmdmst.blog.csdn.net/article/details/128308639
不过,并不是所有的Excel附件都会以ole格式形式存在,而且有些Excel附件是xls格式。
本文目标是,不仅提供Excel附件的代码更加的通用,而且能识别出Excel对应的原始文件名。
注意:Excel附件的文件名完全以图片形式存在,图像识别的准确率并不能达到100%。
这里我们要处理的示例文件为:

我们将该word文档解压缩,即可本地查看内部的xml文档。除了修改文件后缀名为zip,还可以右键使用360压缩打开,直接解压。
解压后,对应的Word文件夹中可以看到我们需要的数据。
xml解析
使用IE游览器打开word\\_rels\\document.xml.rels文件:

可以查看ID和文件路径的关系。
使用游览器打开word\\document.xml文件:

可以查看每个附件对象对应的形状对象和ole对象(实际可能并不是ole格式)的ID。
我们使用python对该word文档完成xml解析,首先解析word\\_rels\\document.xml.rels文件。该xml文件存在xmlns属性,该值是一个命名空间,没有指定名称。在我们的代码中,可以任意指定一个名称进行解析,这里指定了x:
from zipfile import ZipFile
from lxml import etree
filename = "测试.docx"
rid2obj =
zip_file = ZipFile(filename, "r")
xml_f = zip_file.open("word/_rels/document.xml.rels")
xml = etree.parse(xml_f)
for obj in xml.xpath("//x:Relationship",
namespaces="x": "http://schemas.openxmlformats.org/package/2006/relationships"):
rid2obj[obj.attrib["Id"]] = obj.attrib["Target"]
xml_f.close()
zip_file.close()
rid2obj
'rId9': 'media/image3.emf',
'rId8': 'embeddings/oleObject2.bin',
'rId7': 'media/image2.emf',
'rId6': 'embeddings/oleObject1.bin',
'rId5': 'media/image1.emf',
'rId4': 'embeddings/Workbook1.xlsx',
'rId3': 'theme/theme1.xml',
'rId2': 'settings.xml',
'rId12': 'fontTable.xml',
'rId11': 'media/image4.emf',
'rId10': 'embeddings/oleObject3.bin',
'rId1': 'styles.xml'
顺利的拿到每个rid对应的文件路径。
由于该文件其实是所有节点都需要,也可以使用通配符,这样就不需要传入命名空间。即:
xml.xpath("/*/*")
然后我们继续解析word\\document.xml,上面我们看到几乎所有的节点都存在明确的命名空间,根据xml开头的定义:
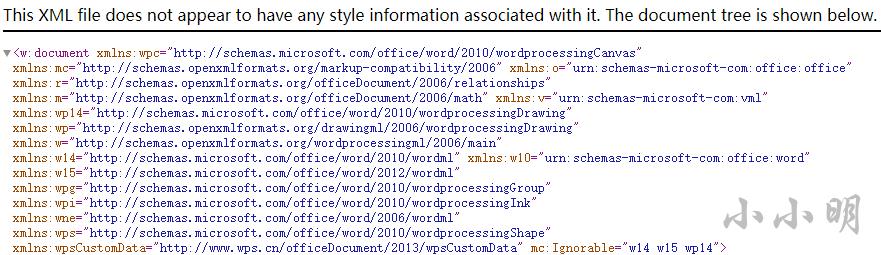
我们将需要使用的命名空间用字典定义,然后解析出需要的信息:
zip_file = ZipFile(filename, "r")
xml_f = zip_file.open("word/document.xml")
xml = etree.parse(xml_f)
namespaces =
"w": "http://schemas.openxmlformats.org/wordprocessingml/2006/main",
"o": "urn:schemas-microsoft-com:office:office",
"v": "urn:schemas-microsoft-com:vml",
"r": "http://schemas.openxmlformats.org/officeDocument/2006/relationships"
for obj in xml.xpath("//w:object", namespaces=namespaces):
progID = obj.xpath("./o:OLEObject/@ProgID", namespaces=namespaces)[0]
rid1 = obj.xpath("./v:shape/v:imagedata/@r:id", namespaces=namespaces)[0]
rid2 = obj.xpath("./o:OLEObject/@r:id", namespaces=namespaces)[0]
print(progID, rid1, rid2)
Excel.Sheet.12 rId5 rId4
Excel.Sheet.12 rId7 rId6
Excel.Sheet.12 rId9 rId8
Excel.Sheet.8 rId11 rId10
结合前面的解析结果我们就可以获取图片文件对应的实际数据文件,同时可以通过progID知道该文件的格式。解析代码:
from zipfile import ZipFile
from lxml import etree
filename = "测试.docx"
img2file =
rid2obj =
namespaces =
"w": "http://schemas.openxmlformats.org/wordprocessingml/2006/main",
"o": "urn:schemas-microsoft-com:office:office",
"v": "urn:schemas-microsoft-com:vml",
"r": "http://schemas.openxmlformats.org/officeDocument/2006/relationships",
"x": "http://schemas.openxmlformats.org/package/2006/relationships"
zip_file = ZipFile(filename, "r")
with zip_file.open("word/_rels/document.xml.rels") as f:
xml = etree.parse(f)
for obj in xml.xpath("//x:Relationship", namespaces=namespaces):
rid2obj[obj.attrib["Id"]] = obj.attrib["Target"]
with zip_file.open("word/document.xml") as f:
xml = etree.parse(f)
for obj in xml.xpath("//w:object", namespaces=namespaces):
suffix = None
progID = obj.xpath("./o:OLEObject/@ProgID", namespaces=
"o": "urn:schemas-microsoft-com:office:office")[0]
if progID == "Excel.Sheet.8":
suffix = "xls"
elif progID == "Excel.Sheet.12":
suffix = "xlsx"
if suffix is None:
continue
rid1 = obj.xpath("./v:shape/v:imagedata/@r:id",
namespaces=namespaces)[0]
rid2 = obj.xpath("./o:OLEObject/@r:id", namespaces=namespaces)[0]
img2file[rid2obj[rid1]] = (rid2obj[rid2], suffix)
img2file
'media/image1.emf': ('embeddings/Workbook1.xlsx', 'xlsx'),
'media/image2.emf': ('embeddings/oleObject1.bin', 'xlsx'),
'media/image3.emf': ('embeddings/oleObject2.bin', 'xlsx'),
'media/image4.emf': ('embeddings/oleObject3.bin', 'xls')
ocr识别
首先测试一下easyocr库,可以使用pip安装pip install easyocr。
首先读取一张图片:
from PIL import Image
f = zip_file.open("word/media/image4.emf")
img = Image.open(f)
img

easyocr支持传入numpy数组:
import numpy as np
import easyocr
ocr = easyocr.Reader(['ch_sim', 'en'], gpu=False)
text_r = ocr.readtext(np.array(img))
filename = text_r[0][1]
filename
'叫川司立士二'
可惜识别效果不佳。
为了更好的识别效果,我们使用云服务进行识别,这里我选择百度云的接口:
https://cloud.baidu.com/product/ocr.html
登录后,点击领取免费资源领取免费使用次数:
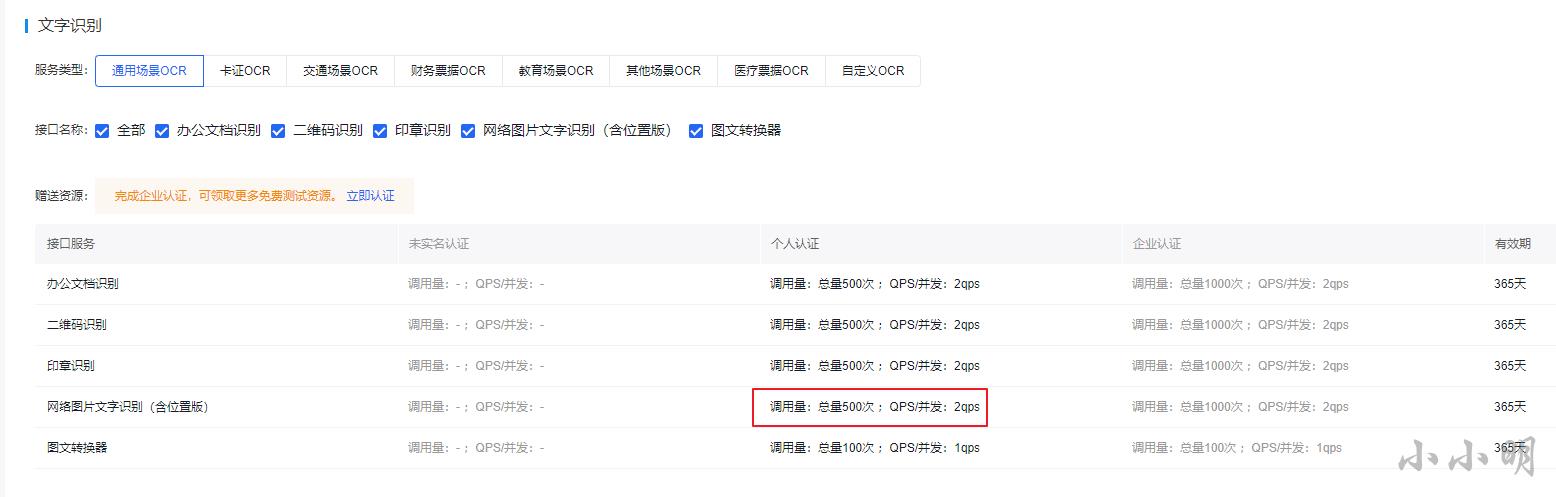
领取后可以看到三个比较合适的接口是每个月1000次免费使用:

要使用百度云的图片识别接口,首先要根据文档获取Access_token,文档地址:https://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjhhu
需要先获取ak和sk,这里我们需要先创建对应的应用,在文字识别-》公有云服务-》应用列表 里 点击 创建应用:

这里我只选择基本权限,然后点击立即创建:
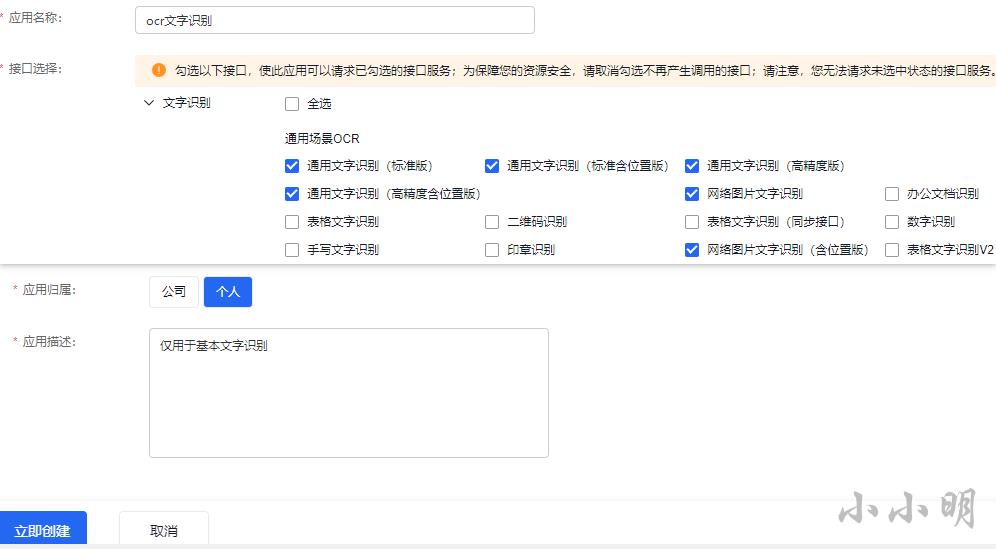
创建完应用,就可以从应用复制ak和sk:

python代码:
import requests
ak="你的API Key"
sk="你的Secret Key"
url = f'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=ak&client_secret=sk'
access_token = requests.get(url).json()['access_token']
然后我们测试一下通用文字识别(标准版),链接:https://cloud.baidu.com/doc/OCR/s/zk3h7xz52
该接口以base64形式传入图片,所以先编写一个将图片转换为base64编码字符串的方法:
from io import BytesIO
import base64
def image_to_base64(img):
output_buffer = BytesIO()
img.save(output_buffer, format='JPEG')
byte_data = output_buffer.getvalue()
base64_str = base64.b64encode(byte_data)
return base64_str
然后调用该接口:
import requests
url = f"https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic?access_token=access_token"
params = "image": image_to_base64(img), "language_type": "CHN_ENG"
res = requests.post(url, data=params)
res.json()
'words_result': ['words': '四川川公司基本资料', 'words': '.xds'],
'words_result_num': 2,
'log_id': 1632702985448691794
再试试通用文字识别(高精度版),链接:
https://cloud.baidu.com/doc/OCR/s/1k3h7y3db
url = f"https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic?access_token=access_token"
params = "image": image_to_base64(img), "language_type": "CHN_ENG"
res = requests.post(url, data=params)
res.json()
'words_result': ['words': '四川公司基本资料', 'words': '.ds'],
'words_result_num': 2,
'log_id': 1632703616274581791
最后试试网络图片文字识别,链接:https://cloud.baidu.com/doc/OCR/s/Sk3h7xyad
url = f"https://aip.baidubce.com/rest/2.0/ocr/v1/webimage?access_token=access_token"
params = "image": image_to_base64(img)
res = requests.post(url, data=params)
res.json()
'words_result': ['words': '四川公司基本资料', 'words': 'xs '],
'words_result_num': 2,
'log_id': 1632704365479044045
综合来看,网络图片文字识别接口的效果最佳。
将上述代码封装一下:
from io import BytesIO
import base64
import requests
def get_access_token(ak, sk):
url = f'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=ak&client_secret=sk'
return requests.get(url).json()['access_token']
def image_to_base64(img):
output_buffer = BytesIO()
img.save(output_buffer, format='JPEG')
byte_data = output_buffer.getvalue()
base64_str = base64.b64encode(byte_data)
return base64_str
def baidu_ocr_img(access_token, img):
url = f"https://aip.baidubce.com/rest/2.0/ocr/v1/webimage?access_token=access_token"
params = "image": image_to_base64(img)
res = requests.post(url, data=params)
text = "".join([w["words"] for w in res.json()["words_result"]])
return text
附件文件保存
对于xlsx格式的文件,可以使用如下代码保存:
import olefile
from openpyxl import load_workbook
f = zip_file.open("word/embeddings/oleObject1.bin")
if olefile.isOleFile(f):
f = olefile.OleFileIO(f).openstream("package")
book = load_workbook(f)
book.save("t1.xlsx")
经测试,个别Excel文件直接保存后,WPS无法打开。其中还有一部分文件使用上述代码用openpyxl加载后保存,也无法打开。
我们必须生成全新的Excel并复制所需要的数据,下面模仿openpyxl.worksheet.copier.WorksheetCopy的源码,创建一个跨工作薄复制工作表的方法:
from copy import copy
from openpyxl.worksheet.worksheet import Worksheet
def copyWorksheet(source, target):
if (not isinstance(source, Worksheet)
and not isinstance(target, Worksheet)):
raise TypeError("Can only copy worksheets")
if source is target:
raise ValueError("Cannot copy a worksheet to itself")
for (row, col), source_cell in source._cells.items():
target_cell = target.cell(column=col, row=row)
target_cell.value = source_cell._value
target_cell.font = copy(source_cell.font)
target_cell.alignment = copy(source_cell.alignment)
target_cell.border = copy(source_cell.border)
target_cell.fill = copy(source_cell.fill)
if source_cell.hyperlink:
target_cell._hyperlink = copy(source_cell.hyperlink)
if source_cell.comment:
target_cell.comment = copy(source_cell.comment)
for attr in ('row_dimensions', 'column_dimensions'):
src = getattr(source, attr)
dst = getattr(target, attr)
for key, dim in src.items():
dst[key] = copy(dim)
dst[key].worksheet = target
target.sheet_format = copy(source.sheet_format)
target.sheet_properties = copy(source.sheet_properties)
target.merged_cells = copy(source.merged_cells)
target.page_margins = copy(source.page_margins)
target.page_setup = copy(source.page_setup)
target.print_options = copy(source.print_options)
target._images = source._images
target.freeze_panes = source.freeze_panes
然后创建一个复制工作簿的方法:
def copyWorkbook(book):
nwb = Workbook()
nwb.remove(nwb.active)
for sht in book.worksheets:
nsht = nwb.create_sheet(title=sht.title)
copyWorksheet(sht, nsht)
return nwb
然后前面的代码可以通过复制法保存:
f = zip_file.open("word/embeddings/oleObject1.bin")
if olefile.isOleFile(f):
f = olefile.OleFileIO(f).openstream("package")
book = load_workbook(f)
nwb = copyWorkbook(book)
nwb.save("t1.xlsx")
nwb.close()
对于xls格式的文件,可以使用xlutils进行复制,从而实现代码保存:
from xlutils.copy import copy
import xlrd
import olefile
f = zip_file.open("word/embeddings/oleObject3.bin")
if olefile.isOleFile(f):
f = olefile.OleFileIO(f).openstream("workbook")
with open("t.xls", "wb") as out:
out.write(f.read())
wb = xlrd.open_workbook('t.xls', formatting_info=True)
nwb = copy(wb)
nwb.save('t2.xls')
代码整合
最终我们将各个模块的代码整合起来并封装,最终代码为:
from PIL import Image
from copy import copy
from openpyxl import load_workbook, Workbook
from openpyxl.worksheet.worksheet import Worksheet
import olefile
import xlrd
from xlutils.copy import copy as xcopy
import requests
import base64
import os
from io import BytesIO
from zipfile import ZipFile
from lxml import etree
def parse_file_obj(zip_file):
img2file =
rid2obj =
namespaces =
"w": "http://schemas.openxmlformats.org/wordprocessingml/2006/main",
"o": "urn:schemas-microsoft-com:office:office",
"v": "urn:schemas-microsoft-com:vml",
"r": "http://schemas.openxmlformats.org/officeDocument/2006/relationships",
"x": "http://schemas.openxmlformats.org/package/2006/relationships"
with zip_file.open("word/_rels/document.xml.rels") as f:
xml = etree.parse(f)
for obj in xml.xpath("//x:Relationship", namespaces=namespaces):
rid2obj[obj.attrib["Id"]] = obj.attrib["Target"]
with zip_file.open("word/document.xml") as f:
xml = etree.parse(f)
for obj in xml.xpath("//w:object", namespaces=namespaces):
suffix = None
progID = obj.xpath("./o:OLEObject/@ProgID", namespaces=
"o": "urn:schemas-microsoft-com:office:office")[0]
if progID == "Excel.Sheet.8":
suffix = "xls"
elif progID == "Excel.Sheet.12":
suffix = "xlsx"
if suffix is None:
continue
rid1 = obj.xpath("./v:shape/v:imagedata/@r:id",
namespaces=namespaces)[0]
rid2 = obj.xpath("./o:OLEObject/@r:id", namespaces=namespaces)[0]
img2file[rid2obj[rid1]] = (rid2obj[rid2], suffix)
return img2file
def copyWorksheet(source, target):
if (not isinstance(source, Worksheet)
and not isinstance(target, Worksheet)):
raise TypeError("Can only copy worksheets")
if source is target:
raise ValueError("Cannot copy a worksheet to itself")
for (row, col), source_cell in source._cells.items():
target_cell = target.cell(column=col, row=row)
target_cell.value = source_cell._value
target_cell.font = copy(source_cell.font)
target_cell.alignment = copy(source_cell.alignment)
target_cell.border = copy(source_cell.border)
target_cell.fill = copy(source_cell.fill)
if source_cell.hyperlink:
target_cell._hyperlink = copy(source_cell.hyperlink)
if source_cell.comment:
target_cell.comment = copy(source_cell.comment)
for attr in ('row_dimensions', 'column_dimensions'):
src = getattr(source, attr)
dst = getattr(target, attr)
for key, dim in src.items():
dst[key] = copy
参考技术A
java的poi插件可以读取word文件。
以上是关于提取Word文档中的Excel附件并识别文件名保存的主要内容,如果未能解决你的问题,请参考以下文章