mysql基操04---mysql表查询强化01
Posted 程序员 DELTA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql基操04---mysql表查询强化01相关的知识,希望对你有一定的参考价值。
1. mysql 表查询–加强
1.1 介绍

-- 查询加强
-- ■ 使用 where 子句
-- ?如何查找 1992.1.1 后入职的员工
-- 老师说明: 在 mysql 中,日期类型可以直接比较, 需要注意格式
SELECT * FROM emp
WHERE hiredate > '1992-01-01'
-- ■ 如何使用 like 操作符(模糊)
-- %: 表示 0 到多个任意字符 _: 表示单个任意字符
-- ?如何显示首字符为 S 的员工姓名和工资
SELECT ename, sal FROM emp
WHERE ename LIKE 'S%' -- ?如何显示第三个字符为大写 O 的所有员工的姓名和工资
SELECT ename, sal FROM emp
WHERE ename LIKE '__O%'
-- ■ 如何显示没有上级的雇员的情况
SELECT * FROM emp
WHERE mgr IS NULL;
-- ■ 查询表结构
DESC emp
-- 使用 order by 子句
-- ?如何按照工资的从低到高的顺序[升序],显示雇员的信息
SELECT * FROM emp
ORDER BY sal
-- ?按照部门号升序而雇员的工资降序排列 , 显示雇员信息
SELECT * FROM emp
ORDER BY deptno ASC , sal DESC;
1.2 分页查询

-- 分页查询
-- 按雇员的id号升序取出, 每页显示3条记录,请分别显示 第1页,第2页,第3页
-- 第1页
SELECT * FROM emp
ORDER BY empno
LIMIT 0, 3;
-- 第2页
SELECT * FROM emp
ORDER BY empno
LIMIT 3, 3;
-- 第3页
SELECT * FROM emp
ORDER BY empno
LIMIT 6, 3;
-- 推导一个公式
SELECT * FROM emp
ORDER BY empno
LIMIT 每页显示记录数 * (第几页-1) , 每页显示记录数
1.3 使用分组函数和分组子句

-- 增强group by 的使用
-- (1) 显示每种岗位的雇员总数、平均工资。
SELECT COUNT(*), AVG(sal), job
FROM emp
GROUP BY job;
-- (2) 显示雇员总数,以及获得补助的雇员数。
-- 思路: 获得补助的雇员数 就是 comm 列为非null, 就是count(列),如果该列的值为null, 是
-- 不会统计 , SQL 非常灵活,需要我们动脑筋.
SELECT COUNT(*), COUNT(comm)
FROM emp
-- 老师的扩展要求:统计没有获得补助的雇员数
SELECT COUNT(*), COUNT(IF(comm IS NULL, 1, NULL))
FROM emp
SELECT COUNT(*), COUNT(*) - COUNT(comm)
FROM emp
-- (3) 显示管理者的总人数。小技巧:尝试写->修改->尝试[正确的]
SELECT COUNT(DISTINCT mgr)
FROM emp;
-- (4) 显示雇员工资的最大差额。
-- 思路: max(sal) - min(sal)
SELECT MAX(sal) - MIN(sal)
FROM emp;
SELECT * FROM emp;
select * from dept;
1.4 数据分组的总结

-- 应用案例:请统计各个部门group by 的平均工资 avg,
-- 并且是大于1000的 having,并且按照平均工资从高到低排序, order by
-- 取出前两行记录 limit 0, 2
SELECT deptno, AVG(sal) AS avg_sal
FROM emp
GROUP BY deptno
HAVING avg_sal > 1000
ORDER BY avg_sal DESC
LIMIT 0,2
2. mysql 多表查询
2.1 问题的引出(重点,难点)
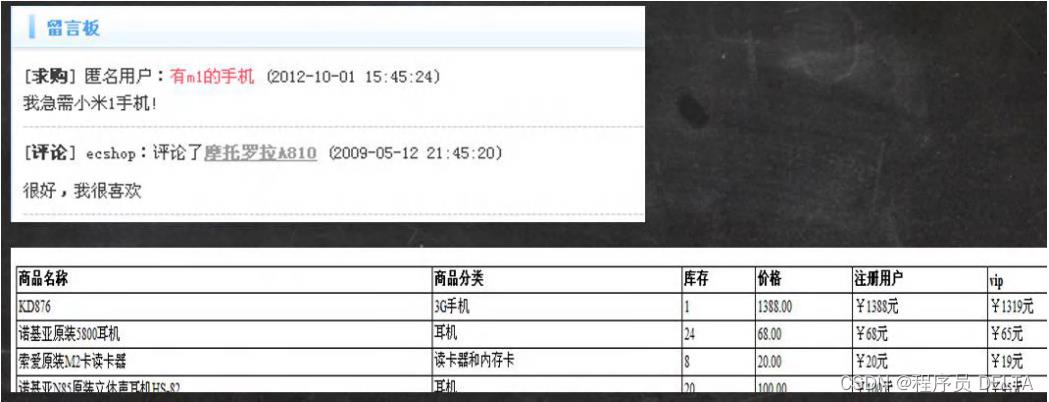
说明:
1.一个留言板,评论用到了评论表,商品用到了商品表,如果想展示评论信息,则必须同时查询两个表的信息
2.2 说明

2.3 多表查询练习

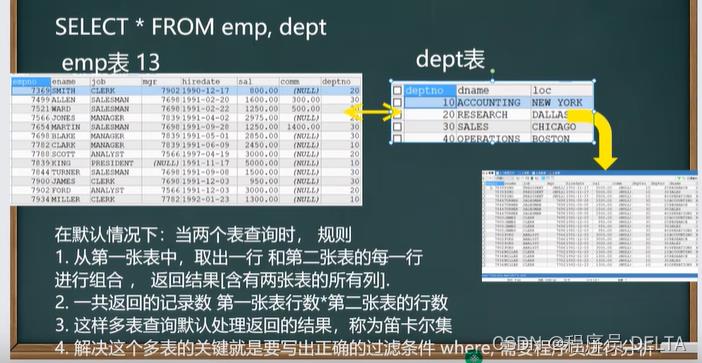
-- 多表查询
-- ?显示雇员名,雇员工资及所在部门的名字 【笛卡尔集】
/*
分析
1. 雇员名,雇员工资 来自 emp表
2. 部门的名字 来自 dept表
3. 需求对 emp 和 dept查询 ename,sal,dname,deptno
4. 当我们需要指定显示某个表的列是,需要 表.列表
*/
SELECT ename,sal,dname,emp.deptno
FROM emp, dept
WHERE emp.deptno = dept.deptno
select * from emp;
select * from dept;
select * from salgrade;
-- 小技巧:多表查询的条件不能少于 表的个数-1, 否则会出现笛卡尔集
-- ?如何显示部门号为10的部门名、员工名和工资
SELECT ename,sal,dname,emp.deptno
FROM emp, dept
WHERE emp.deptno = dept.deptno and emp.deptno = 10
-- ?显示各个员工的姓名,工资,及其工资的级别
-- 思路 姓名,工资 来自 emp 13
-- 工资级别 salgrade 5
-- 写sql , 先写一个简单,然后加入过滤条件...
select ename, sal, grade
from emp , salgrade
where sal between losal and hisal;
-- 作业
select ename 雇员名,sal 雇员工资,dname 部门名称,emp.deptno 部门编号 from emp,dept
where emp.deptno=dept.deptno
order by dept.deptno desc;
2.4 自连接

-- 多表查询的 自连接
-- 思考题: 显示公司员工名字和他的上级的名字
-- 分析: 员工名字 在emp, 上级的名字的名字 emp
-- 员工和上级是通过 emp表的 mgr 列关联
-- 这里老师小结:
-- 自连接的特点 1. 把同一张表当做两张表使用
-- 2. 需要给表取别名 表名 表别名
-- 3. 列名不明确,可以指定列的别名 列名 as 列的别名
SELECT worker.ename AS '职员名' , boss.ename AS '上级名'
FROM emp worker, emp boss
WHERE worker.mgr = boss.empno;
SELECT * FROM emp;
3. mysql 表子查询
3.1 什么是子查询
子查询是指嵌入在其它 sql 语句中的 select 语句,也叫嵌套查询
3.2 单行子查询
单行子查询是指只返回一行数据的子查询语句
请思考:如何显示与 SMITH 同一部门的所有员工?
3.3 多行子查询
多行子查询指返回多行数据的子查询 使用关键字 in

-- 子查询的演示
-- 请思考:如何显示与SMITH同一部门的所有员工?
/*
1. 先查询到 SMITH的部门号得到
2. 把上面的select 语句当做一个子查询来使用
*/
SELECT deptno
FROM emp
WHERE ename = 'SMITH'
-- 下面的答案.
SELECT *
FROM emp
WHERE deptno = (
SELECT deptno
FROM emp
WHERE ename = 'SMITH'
)
-- 课堂练习:如何查询和部门10的工作相同的雇员的
-- 名字、岗位、工资、部门号, 但是不含10号部门自己的雇员.
/*
1. 查询到10号部门有哪些工作
2. 把上面查询的结果当做子查询使用
*/
select distinct job
from emp
where deptno = 10;
-- 下面语句完整
select ename, job, sal, deptno
from emp
where job in (
SELECT DISTINCT job
FROM emp
WHERE deptno = 10
) and deptno <> 10 -- <>表示不等于,推荐写法
3.4 子查询当做临时表使用
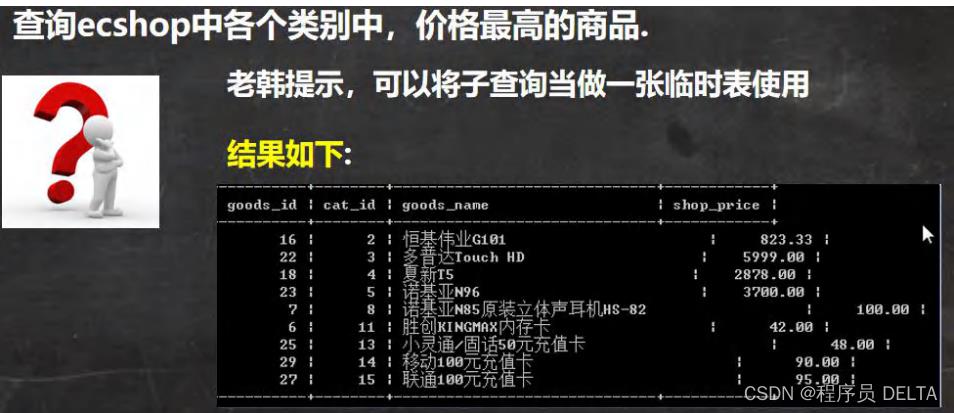
-- 查询ecshop中各个类别中,价格最高的商品
-- 查询 商品表
-- 先得到 各个类别中,价格最高的商品 max + group by cat_id, 当做临时表
-- 把子查询当做一张临时表可以解决很多很多复杂的查询
select cat_id , max(shop_price)
from ecs_goods
group by cat_id
-- 这个最后答案
select goods_id, ecs_goods.cat_id, goods_name, shop_price
from (
SELECT cat_id , MAX(shop_price) as max_price
FROM ecs_goods
GROUP BY cat_id
) temp , ecs_goods
where temp.cat_id = ecs_goods.cat_id
and temp.max_price = ecs_goods.shop_price
3.5 在多行子查询中使用 all 操作符

-- all 和 any的使用
-- 请思考:显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
SELECT ename, sal, deptno
FROM emp
WHERE sal > ALL(
SELECT sal
FROM emp
WHERE deptno = 30
)
-- 可以这样写
SELECT ename, sal, deptno
FROM emp
WHERE sal > (
SELECT MAX(sal)
FROM emp
WHERE deptno = 30
)
3.6 在多行子查询中使用 any 操作符

-- 请思考:如何显示工资比部门30的其中一个员工的工资高的员工的姓名、工资和部门号
SELECT ename, sal, deptno
FROM emp
WHERE sal > any(
SELECT sal
FROM emp
WHERE deptno = 30
)
SELECT ename, sal, deptno
FROM emp
WHERE sal > (
SELECT min(sal)
FROM emp
WHERE deptno = 30
)
3.7 多列子查询

-- 多列子查询
-- 请思考如何查询与allen的部门和岗位完全相同的所有雇员(并且不含allen本人)
-- (字段1, 字段2 ...) = (select 字段 1,字段2 from 。。。。)
-- 分析: 1. 得到smith的部门和岗位
SELECT deptno , job
FROM emp
WHERE ename = 'ALLEN'
-- 分析: 2 把上面的查询当做子查询来使用,并且使用多列子查询的语法进行匹配
SELECT *
FROM emp
WHERE (deptno , job) = (
SELECT deptno , job
FROM emp
WHERE ename = 'ALLEN'
) AND ename != 'ALLEN'
-- 请查询 和宋江数学,英语,语文
-- 成绩 完全相同的学生
SELECT *
FROM student
WHERE (math, english, chinese) = (
SELECT math, english, chinese
FROM student
WHERE `name` = '宋江'
)
SELECT * FROM student;
3.8 练习
3.8.1 在 from 子句中使用子查询


-- 子查询练习
-- 请思考:查找每个部门工资高于本部门平均工资的人的资料
-- 这里要用到数据查询的小技巧,把一个子查询当作一个临时表使用
-- 1. 先得到每个部门的 部门号和 对应的平均工资
SELECT deptno, AVG(sal) AS avg_sal
FROM emp GROUP BY deptno
-- 2. 把上面的结果当做子查询, 和 emp 进行多表查询
--
SELECT ename, sal, temp.avg_sal, emp.deptno
FROM emp, (
SELECT deptno, AVG(sal) AS avg_sal
FROM emp
GROUP BY deptno
) temp
where emp.deptno = temp.deptno and emp.sal > temp.avg_sal
-- 查找每个部门工资最高的人的详细资料
SELECT ename, sal, temp.max_sal, emp.deptno
FROM emp, (
SELECT deptno, max(sal) AS max_sal
FROM emp
GROUP BY deptno
) temp
WHERE emp.deptno = temp.deptno AND emp.sal = temp.max_sal
-- 查询每个部门的信息(包括:部门名,编号,地址)和人员数量,我们一起完成。
-- 1. 部门名,编号,地址 来自 dept表
-- 2. 各个部门的人员数量 -》 构建一个临时表
select count(*), deptno
from emp
group by deptno;
select dname, dept.deptno, loc , tmp.per_num as '人数'
from dept, (
SELECT COUNT(*) as per_num, deptno
FROM emp
GROUP BY deptno
) tmp
where tmp.deptno = dept.deptno
-- 还有一种写法 表.* 表示将该表所有列都显示出来, 可以简化sql语句
-- 在多表查询中,当多个表的列不重复时,才可以直接写列名
SELECT tmp.* , dname, loc
FROM dept, (
SELECT COUNT(*) AS per_num, deptno
FROM emp
GROUP BY deptno
) tmp
WHERE tmp.deptno = dept.deptno
初识MySQL数据库基操篇
MYSQL入门系列——第一篇
每篇前言:
🏆🏆作者介绍:【孤寒者】—CSDN全栈领域优质创作者、HDZ核心组成员、华为云享专家Python全栈领域博主、CSDN原力计划作者
- 🔥🔥本文已收录于三大数据库深入讲解专栏:《三大数据库深入讲解》
- 🔥🔥热门专栏推荐:《Django框架从入门到实战》、《爬虫从入门到精通系列教程》、《爬虫高级》、《前端系列教程》、《tornado一条龙+一个完整版项目》。
- 📝📝本专栏面向广大程序猿,为的是大家入门并精通开发python项目常用的三大数据库:MySql,Redis,MongoDB。
- 🎉🎉订阅专栏后可私聊进一千多人Python全栈交流群(手把手教学,问题解答); 进群可领取Python全栈教程视频 + 多得数不过来的计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
👇
👉🚔直接跳到末尾🚔👈 ——>领取专属粉丝福利💖
☝️
1.数据库简介:
(1)概念:
-
按照一定的数据结构来存储和管理数据的仓库;
-
计算机主要把数据放在磁盘和内存中。
(2)分类:
- 关系型数据库(SQL)
- 例如:MySQL(免费开源),oracle
- 存储方式固定,安全
- 非关系型数据库(NoSQL(Not Only SQL))
- 存储方式比较灵活,存储数据的效率比较高, 不太安全

2.MySQL的基本结构:
最流行的关系型数据库管理系统之一,由瑞典MySql AB公司开发,目前属于甲骨文(Oracle)公司。MySQL是一种关系型数据库管理系统,MySQL由于性能高,成本低,可靠性好,是最流行的开源数据库之一,被广泛唉互联网的中小型网站中,随着MySQL的不断成熟,它被逐渐用于更多大规模的网站和应用。
(1)概念与特点
-
关系型数据库管理系统:采用关系模型来组织管理数据的数据库系统
-
把数据保存在不同的表中,而不是将数据放在一个大仓库中
-
可以运行于多个系统上,并且支持多种编程语言,包括C、C++、Python、Java、Perl、PHP、Ruby等
(2)MySQL组织数据的基本格式:
小注意:
【MySQL不是数据库,它是数据库管理软件。】

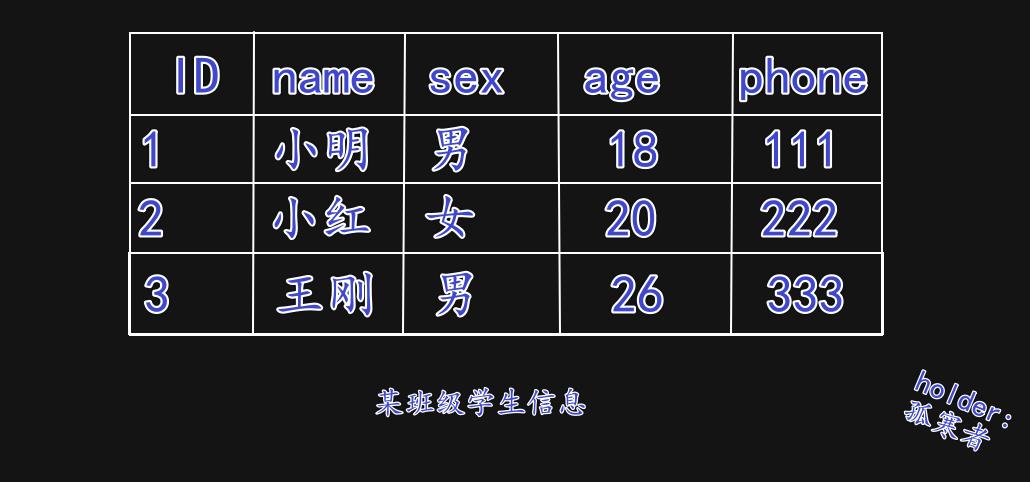
(3)MySQL表中的数据:
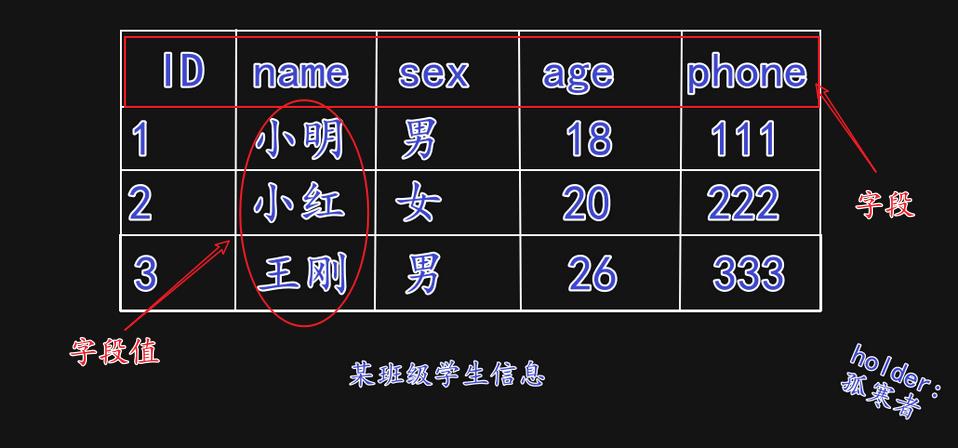
3.MySQL库级和表级操作:
(1)注意事项:
-
大小写:不严格区分大小写,默认大写为程序代码,小写为程序员写的代码
-
语句结束符:每个语句都以;或者\\g结束
-
类型:强制数据类型,任何数据都有自己的数据类型
-
逗号:创建表的时候最后一行不需要逗号
(2)进入与退出:
-
进入:
mysql –uusername -ppassword (显示密码)或者mysql -uroot -p (不显示密码)
解释: mysql(调用mysql程序) -u(mysql里创建的用户) -p(用户的密码) -
退出:
exit或者\\q
(3)库级操作语句:
-
显示所有的库:
show databases; -
创建库:
create database [if not exists] db_name;
重复创建会报错, 可以加上if not exists -
删除库:
drop database [if exists] db_name;
如果不知道数据库是否存在,记得加if exists -
进入数据库:
use db_name; -
显示当前的数据库:
select database();
(4)表级操作语句:
-
显示所有的表:
show tables; -
创建表:
create table [if not exists] tb_name (create definition…);
重复创建会报错, 可以加上if not exists -
显示创建表的信息:(共两种方法~)
(1)show create table tb_name;
(2)describe tb_name; -
删除表:
drop table tb_name;
if exists tb_name
4.MySQL表中数据的操作:
(1)插入数据:
-
指定字段插入:
insert into tb_name(field_name) values (field_values); -
全字段插入:
insert into tb_name values(all_values);
values后面的s可加可不加(数据特别多的时候加s)。 -
多行插入:(两种方法~)
(1)insert into tb_name(field_name) values (value_1), (value_2), …;
(2)insert into tb_name set field_name = value,field_name2 = value;
(2)查询数据:
-
指定字段查询:
select field_names from tb_name; -
全字段查询:
select * from tb_name; -
带条件的查询:
select field_names from tb_name where conditions;
(3)修改数据:
-
修改所有数据:
update tb_name set field_1=value_1; -
修改多个:
update tb_name set field_1=value_1, field_2=value_2 …; -
修改满足条件的数据:
update tb_name set field_1=value_1 where conditions;
注意:一定要写where条件,不然会修改表中全部数据
(4)删除数据:
-
删除表中所有数据:
delete from tb_name; -
删除表中满足条件的数据:
delete from tb_name where conditions;
注意:一定要写where条件,不然会删除表中全部数据
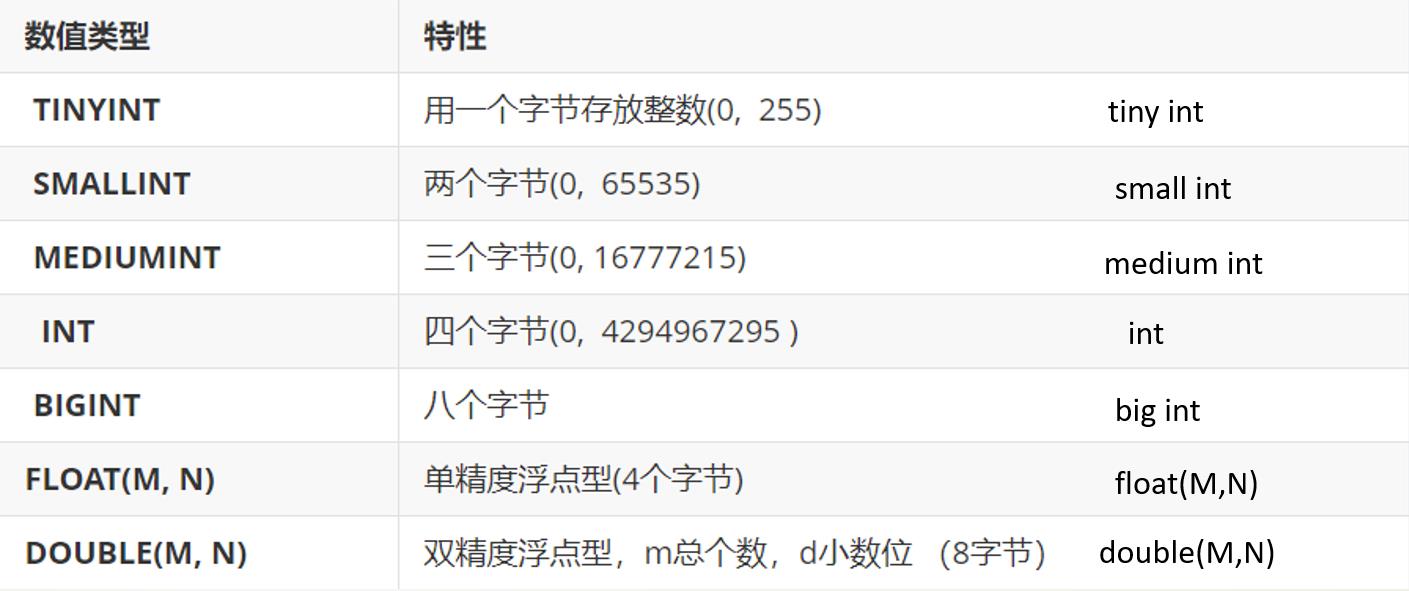
5.MySQL数据类型
1.数值类型:
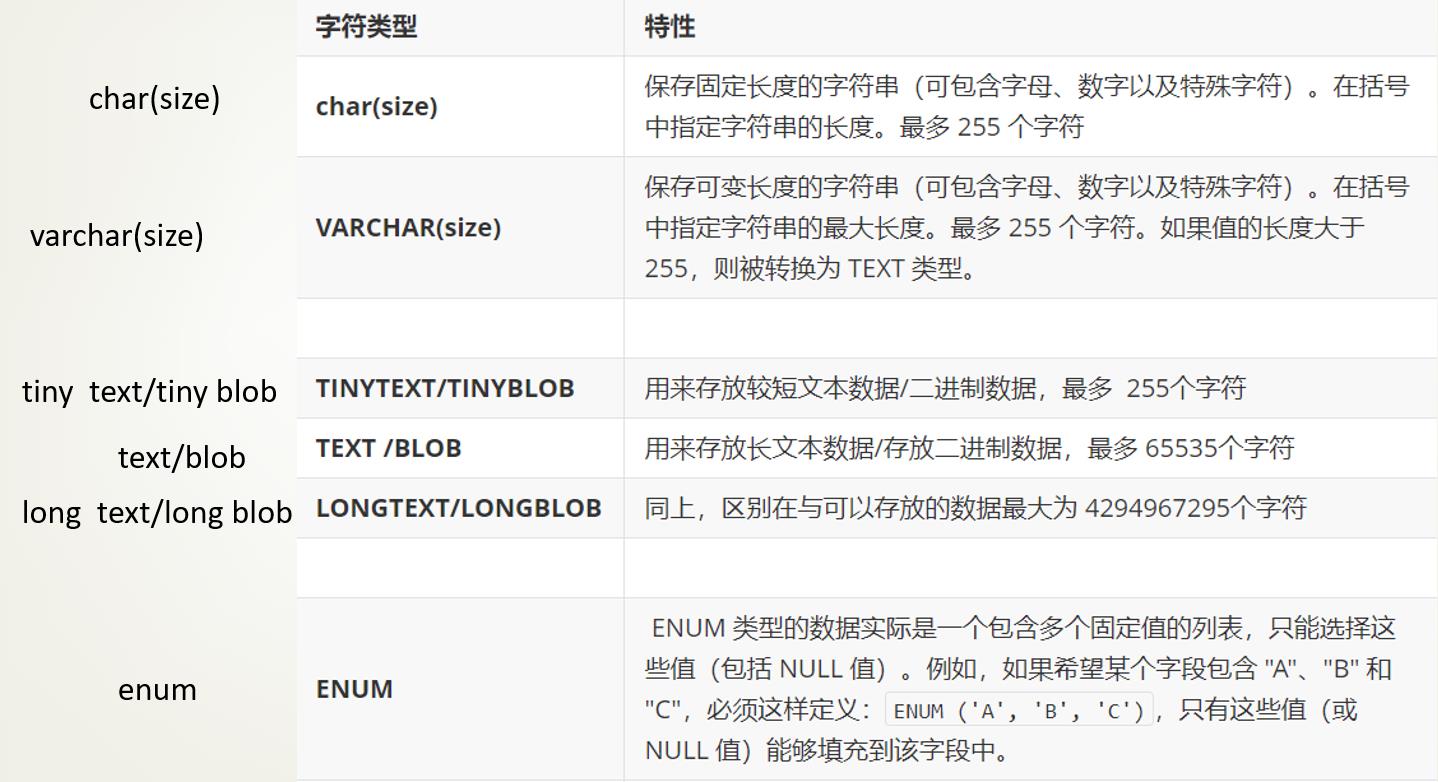
2.字符类型:
3.时间日期类型:
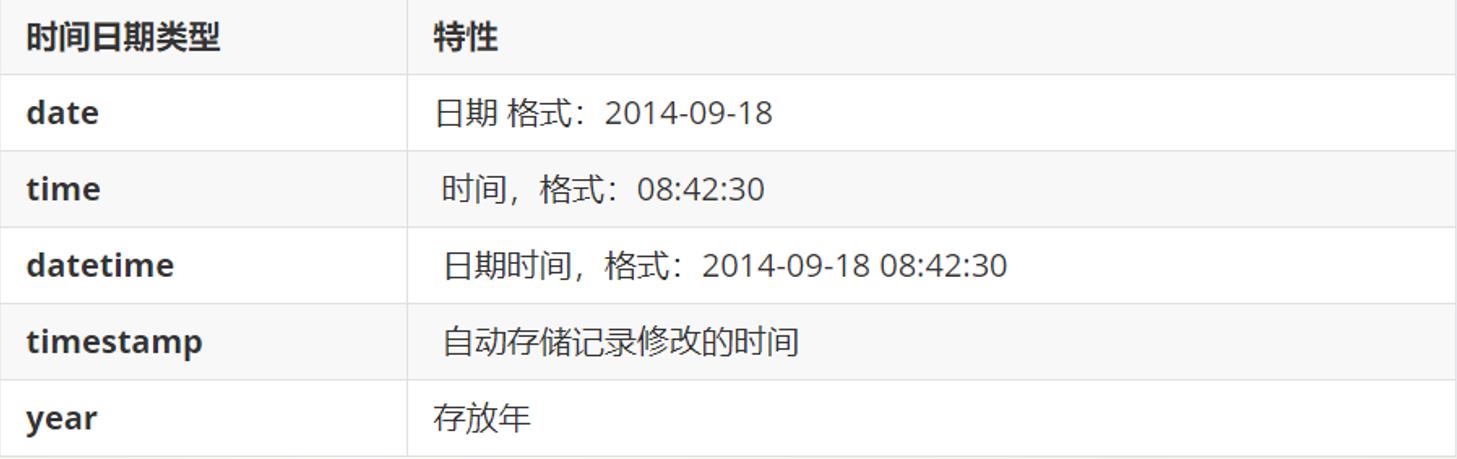
4.实战使用:

insert into tb2 value(1, '小红', 18.0, '小红真的好美!!!', now(), '好评');
以上是关于mysql基操04---mysql表查询强化01的主要内容,如果未能解决你的问题,请参考以下文章