memcached中hash表相关操作
Posted 飘舞的雪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了memcached中hash表相关操作相关的知识,希望对你有一定的参考价值。
以下转自http://blog.csdn.net/luotuo44/article/details/42773231
memcached源码中assoc.c文件里面的代码是构造一个哈希表。memcached快的一个原因是使用了哈希表。现在就来看一下memcached是怎么使用哈希表的。
哈希结构:
main函数会调用assoc_init函数申请并初始化哈希表。为了减少哈希表发生冲突的可能性,memcached的哈希表是比较长的,并且哈希表的长度为2的幂。全局变量hashpower用来记录2的幂次。main函数调用assoc_init函数时使用全局变量settings.hashpower_init作为参数,用于指明哈希表初始化时的幂次。settings.hashpower_init可以在启动memcached的时候设置。
- //memcached.h文件
- #define HASHPOWER_DEFAULT 16
- //assoc.h文件
- unsigned int hashpower = HASHPOWER_DEFAULT;
- #define hashsize(n) ((ub4)1<<(n))//这里是1 左移 n次
- //hashsize(n)为2的幂,所以hashmask的值的二进制形式就是后面全为1的数。这就很像位操作里面的 &
- //value & hashmask(n)的结果肯定是比hashsize(n)小的一个数字.即结果在hash表里面
- //hashmask(n)也可以称为哈希掩码
- #define hashmask(n) (hashsize(n)-1)
- //哈希表数组指针
- static item** primary_hashtable = 0;
- //默认参数值为0。本函数由main函数调用,参数的默认值为0
- void assoc_init(const int hashtable_init) {
- if (hashtable_init) {
- hashpower = hashtable_init;
- }
- //因为哈希表会慢慢增大,所以要使用动态内存分配。哈希表存储的数据是一个
- //指针,这样更省空间。
- //hashsize(hashpower)就是哈希表的长度了
- primary_hashtable = calloc(hashsize(hashpower), sizeof(void *));
- if (! primary_hashtable) {
- fprintf(stderr, "Failed to init hashtable.\\n");
- exit(EXIT_FAILURE);//哈希表是memcached工作的基础,如果失败只能退出运行
- }
- }
说到哈希表,那么就对应有两个问题:哈希算法,怎么解决冲突。
对于哈希函数(算法),memcached直接使用开源的MurmurHash3和jenkins_hash两个中的一个。默认是使用jenkins,可以在启动memcached的时候设置设置为MurmurHash3。memcached是直接把客户端输入的键值作为哈希算法的输入,得到一个32位的无符号整型输出(用变量hv存储)。因为哈希表的长度没有2^32- 1这么大,所以需要一个函数将hv映射在哈希表的范围之内。memcached采用了最简单的取模运算作为映射函数,即hv%hashsize(hashpower)。对于CPU而言,取模运算是一个比较耗时的操作。所以memcached利用哈希表的长度是2的幂的性质,采用位操作进行优化,即: hv & hashmask(hashpower)。因为对哈希表进行增删查操作都需要定位,所以经常本文的代码中经常会出现hv & hashmask(hashpower)。
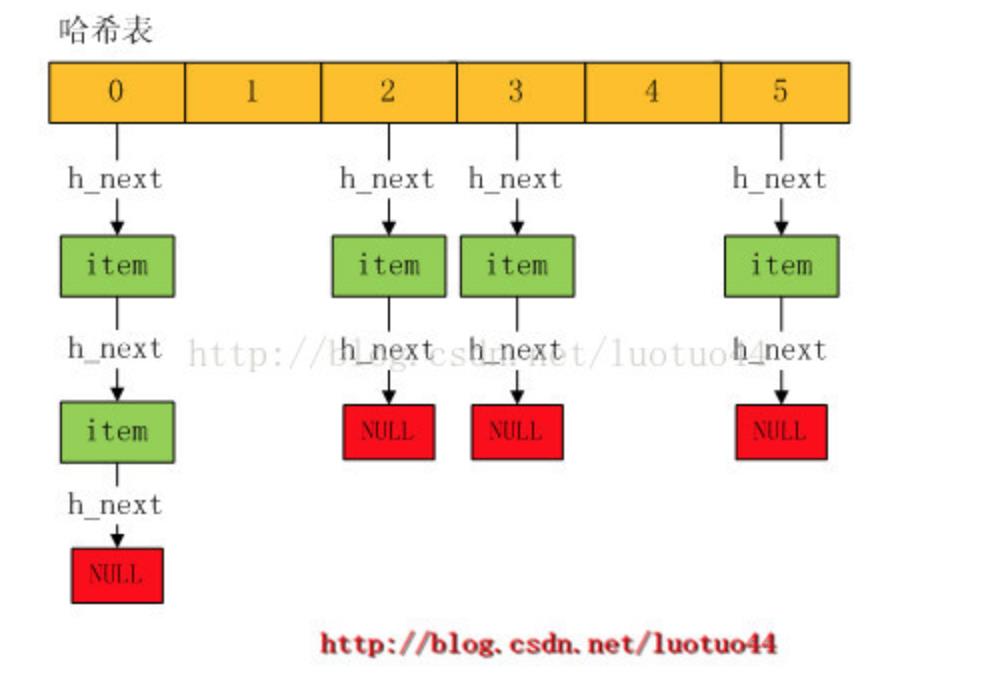
memcached使用最常见的链地址法解决冲突问题。从前面的代码可以看到,primary_hashtable是一个的二级指针变量,它指向的是一个一维指针数组,数组的每一个元素指向一条链表(链表上的item节点具有相同的哈希值)。数组的每一个元素,在memcached里面也称为桶(bucket),所以后文的表述中会使用桶。下图是一个哈希表,其中第0号桶有2个item,第2、3、5号桶各有一个item。item就是用来存储用户数据的结构体。
基本操作:
插入item:
接着看一下怎么在哈希表中插入一个item。它是直接根据哈希值找到哈希表中的位置(即找到对应的桶),然后使用头插法插入到桶的冲突链中。item结构体有一个专门的h_next指针成员变量用于连接哈希冲突链。
- static unsigned int hash_items = 0;//hash表中item的个数
- /* Note: this isn\'t an assoc_update. The key must not already exist to call this */
- //hv是这个item键值的哈希值
- int assoc_insert(item *it, const uint32_t hv) {
- unsigned int oldbucket;
- //使用头插法 插入一个item
- //第一次看本函数,直接看else部分
- if (expanding &&
- (oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket)
- {
- ...
- } else {
- //使用头插法插入哈希表中
- it->h_next = primary_hashtable[hv & hashmask(hashpower)];
- primary_hashtable[hv & hashmask(hashpower)] = it;
- }
- hash_items++;//哈希表的item数量加一
- …
- return 1;
- }
查找item:
往哈希表插入item后,就可以开始查找item了。下面看一下怎么在哈希表中查找一个item。item的键值hv只能定位到哈希表中的桶位置,但一个桶的冲突链上可能有多个item,所以除了查找的时候除了需要hv外还需要item的键值。
- //由于哈希值只能确定是在哈希表中的哪个桶(bucket),但一个桶里面是有一条冲突链的
- //此时需要用到具体的键值遍历并一一比较冲突链上的所有节点。虽然key是以\'\\0\'结尾
- //的字符串,但调用strlen还是有点耗时(需要遍历键值字符串)。所以需要另外一个参数
- //nkey指明这个key的长度
- item *assoc_find(const char *key, const size_t nkey, const uint32_t hv) {
- item *it;
- unsigned int oldbucket;
- //直接看else部分
- if (expanding &&
- (oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket)
- {
- it = old_hashtable[oldbucket];
- } else {
- //由哈希值判断这个key是属于那个桶(bucket)的
- it = primary_hashtable[hv & hashmask(hashpower)];
- }
- //到这里,已经确定这个key是属于那个桶的。 遍历对应桶的冲突链即可
- item *ret = NULL;
- while (it) {
- //长度相同的情况下才调用memcmp比较,更高效
- if ((nkey == it->nkey) && (memcmp(key, ITEM_key(it), nkey) == 0)) {
- ret = it;
- break;
- }
- it = it->h_next;
- }
- return ret;
- }
删除item:
下面看一下从哈希表中删除一个item是怎么实现的。从链表中删除一个节点的常规做法是:先找到这个节点的前驱节点,然后使用前驱节点的next指针进行删除和拼接操作。memcached的做法差不多,实现如下:
- void assoc_delete(const char *key, const size_t nkey, const uint32_t hv) {
- item **before = _hashitem_before(key, nkey, hv);//得到前驱节点的h_next成员地址
- if (*before) {//查找成功
- item *nxt;
- hash_items--;
- //因为before是一个二级指针,其值为所查找item的前驱item的h_next成员地址.
- //所以*before指向的是所查找的item.因为before是一个二级指针,所以
- //*before作为左值时,可以给h_next成员变量赋值。所以下面三行代码是
- //使得删除中间的item后,前后的item还能连得起来。
- nxt = (*before)->h_next;
- (*before)->h_next = 0; /* probably pointless, but whatever. */
- *before = nxt;
- return;
- }
- /* Note: we never actually get here. the callers don\'t delete things
- they can\'t find. */
- assert(*before != 0);
- }
- //查找item。返回前驱节点的h_next成员地址,如果查找失败那么就返回冲突链中最后
- //一个节点的h_next成员地址。因为最后一个节点的h_next的值为NULL。通过对返回值
- //使用 * 运算符即可知道有没有查找成功。
- static item** _hashitem_before (const char *key, const size_t nkey, const uint32_t hv) {
- item **pos;
- unsigned int oldbucket;
- //同样,看的时候直接跳到else部分
- if (expanding &&//正在扩展哈希表
- (oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket)
- {
- pos = &old_hashtable[oldbucket];
- } else {
- //找到哈希表中对应的桶位置
- pos = &primary_hashtable[hv & hashmask(hashpower)];
- }
- //遍历桶的冲突链查找item
- while (*pos && ((nkey != (*pos)->nkey) || memcmp(key, ITEM_key(*pos), nkey))) {
- pos = &(*pos)->h_next;
- }
- //*pos就可以知道有没有查找成功。如果*pos等于NULL那么查找失败,否则查找成功。
- return pos;
- }
扩展哈希表:
当哈希表中item的数量达到了哈希表表长的1.5倍时,那么就会扩展哈希表增大哈希表的表长。memcached在插入一个item时会检查当前的item总数是否达到了哈希表表长的1.5倍。由于item的哈希值是比较均匀的,所以平均来说每个桶的冲突链长度大概就是1.5个节点。所以memcached的哈希查找还是很快的。
迁移线程:
扩展哈希表有一个很大的问题:扩展后哈希表的长度变了,item哈希后的位置也是会跟着变化的(回忆一下memcached是怎么根据键值的哈希值确定桶的位置的)。所以如果要扩展哈希表,那么就需要对哈希表中所有的item都要重新计算哈希值得到新的哈希位置(桶位置),然后把item迁移到新的桶上。对所有的item都要做这样的处理,所以这必然是一个耗时的操作。后文会把这个操作称为数据迁移。
因为数据迁移是一个耗时的操作,所以这个工作由一个专门的线程(姑且把这个线程叫做迁移线程吧)负责完成。这个迁移线程是由main函数调用一个函数创建的。看下面代码:
- #define DEFAULT_HASH_BULK_MOVE 1
- int hash_bulk_move = DEFAULT_HASH_BULK_MOVE;
- //main函数会调用本函数,启动数据迁移线程
- int start_assoc_maintenance_thread() {
- int ret;
- char *env = getenv("MEMCACHED_HASH_BULK_MOVE");
- if (env != NULL) {
- //hash_bulk_move的作用在后面会说到。这里是通过环境变量给hash_bulk_move赋值
- hash_bulk_move = atoi(env);
- if (hash_bulk_move == 0) {
- hash_bulk_move = DEFAULT_HASH_BULK_MOVE;
- }
- }
- if ((ret = pthread_create(&maintenance_tid, NULL,
- assoc_maintenance_thread, NULL)) != 0) {
- fprintf(stderr, "Can\'t create thread: %s\\n", strerror(ret));
- return -1;
- }
- return 0;
- }
迁移线程被创建后会进入休眠状态(通过等待条件变量),当worker线程插入item后,发现需要扩展哈希表就会调用assoc_start_expand函数唤醒这个迁移线程。
- static bool started_expanding = false;
- //assoc_insert函数会调用本函数,当item数量到了哈希表表长的1.5倍才会调用的
- static void assoc_start_expand(void) {
- if (started_expanding)
- return;
- started_expanding = true;
- pthread_cond_signal(&maintenance_cond);
- }
- static bool expanding = false;//标明hash表是否处于扩展状态
- static volatile int do_run_maintenance_thread = 1;
- static void *assoc_maintenance_thread(void *arg) {
- //do_run_maintenance_thread是全局变量,初始值为1,在stop_assoc_maintenance_thread
- //函数中会被赋值0,终止迁移线程
- while (do_run_maintenance_thread) {
- int ii = 0;
- //上锁
- item_lock_global();
- mutex_lock(&cache_lock);
- ...//进行item迁移
- //遍历完就释放锁
- mutex_unlock(&cache_lock);
- item_unlock_global();
- if (!expanding) {//不需要迁移数据(了)。
- /* We are done expanding.. just wait for next invocation */
- mutex_lock(&cache_lock);
- started_expanding = false; //重置
- //挂起迁移线程,直到worker线程插入数据后发现item数量已经到了1.5倍哈希表大小,
- //此时调用worker线程调用assoc_start_expand函数,该函数会调用pthread_cond_signal
- //唤醒迁移线程
- pthread_cond_wait(&maintenance_cond, &cache_lock);
- mutex_unlock(&cache_lock);
- ...
- mutex_lock(&cache_lock);
- assoc_expand();//申请更大的哈希表,并将expanding设置为true
- mutex_unlock(&cache_lock);
- }
- }
- return NULL;
- }
逐步迁移数据:
为了避免在迁移的时候worker线程增删哈希表,所以要在数据迁移的时候加锁,worker线程抢到了锁才能增删查找哈希表。memcached为了实现快速响应(即worker线程能够快速完成增删查找操作),就不能让迁移线程占锁太久。但数据迁移本身就是一个耗时的操作,这是一个矛盾。
memcached为了解决这个矛盾,就采用了逐步迁移的方法。其做法是,在一个循环里面:加锁-》只进行小部分数据的迁移-》解锁。这样做的效果是:虽然迁移线程会多次抢占锁,但每次占有锁的时间都是很短的,这就增加了worker线程抢到锁的概率,使得worker线程能够快速完成它的操作。一小部分是多少个item呢?前面说到的全局变量hash_bulk_move就指明是多少个桶的item,默认值是1个桶,后面为了方便叙述也就认为hash_bulk_move的值为1。
逐步迁移的具体做法是,调用assoc_expand函数申请一个新的更大的哈希表,每次只迁移旧哈希表一个桶的item到新哈希表,迁移完一桶就释放锁。此时就要求有一个旧哈希表和新哈希表。在memcached实现里面,用primary_hashtable表示新表(也有一些博文称之为主表),old_hashtable表示旧表(副表)。
前面说到,迁移线程被创建后就会休眠直到被worker线程唤醒。当迁移线程醒来后,就会调用assoc_expand函数扩大哈希表的表长。assoc_expand函数如下:
- static void assoc_expand(void) {
- old_hashtable = primary_hashtable;
- //申请一个新哈希表,并用old_hashtable指向旧哈希表
- primary_hashtable = calloc(hashsize(hashpower + 1), sizeof(void *));
- if (primary_hashtable) {
- hashpower++;
- expanding = true;//标明已经进入扩展状态
- expand_bucket = 0;//从0号桶开始数据迁移
- } else {
- primary_hashtable = old_hashtable;
- /* Bad news, but we can keep running. */
- }
- }
现在看一下完整一点的assoc_maintenance_thread线程函数,体会迁移线程是怎么逐步数据迁移的。为什么说完整一点呢?因为该函数里面还是有一些东西本篇博文是没有解释的,但这并不妨碍我们阅读该函数。后面还会有其他博文对这个线程函数进行讲解的。
- static unsigned int expand_bucket = 0;//指向待迁移的桶
- #define DEFAULT_HASH_BULK_MOVE 1
- int hash_bulk_move = DEFAULT_HASH_BULK_MOVE;
- static volatile int do_run_maintenance_thread = 1;
- static void *assoc_maintenance_thread(void *arg) {
- //do_run_maintenance_thread是全局变量,初始值为1,在stop_assoc_maintenance_thread
- //函数中会被赋值0,终止迁移线程
- while (do_run_maintenance_thread) {
- int ii = 0;
- //上锁
- item_lock_global();
- mutex_lock(&cache_lock);
- //hash_bulk_move用来控制每次迁移,移动多少个桶的item。默认是一个.
- //如果expanding为true才会进入循环体,所以迁移线程刚创建的时候,并不会进入循环体
- for (ii = 0; ii < hash_bulk_move && expanding; ++ii) {
- item *it, *next;
- int bucket;
- //在assoc_expand函数中expand_bucket会被赋值0
- //遍历旧哈希表中由expand_bucket指明的桶,将该桶的所有item
- //迁移到新哈希表中。
- for (it = old_hashtable[expand_bucket]; NULL != it; it = next) {
- next = it->h_next;
- //重新计算新的哈希值,得到其在新哈希表的位置
- bucket = hash(ITEM_key(it), it->nkey) & hashmask(hashpower);
- //将这个item插入到新哈希表中
- it->h_next = primary_hashtable[bucket];
- primary_hashtable[bucket] = it;
- }
- //不需要清空旧桶。直接将冲突链的链头赋值为NULL即可
- old_hashtable[expand_bucket] = NULL;
- //迁移完一个桶,接着把expand_bucket指向下一个待迁移的桶
- expand_bucket++;
- if (expand_bucket == hashsize(hashpower - 1)) {//全部数据迁移完毕
- expanding = false; //将扩展标志设置为false
- free(old_hashtable);
- }
- }
- //遍历完hash_bulk_move个桶的所有item后,就释放锁
- mutex_unlock(&cache_lock);
- item_unlock_global();
- if (!expanding) {//不再需要迁移数据了。
- /* finished expanding. tell all threads to use fine-grained(细粒度的) locks */
- //进入到这里,说明已经不需要迁移数据(停止扩展了)。
- ...
- mutex_lock(&cache_lock);
- started_expanding = false; //重置
- //挂起迁移线程,直到worker线程插入数据后发现item数量已经到了1.5倍哈希表大小,
- //此时调用worker线程调用assoc_start_expand函数,该函数会调用pthread_cond_signal
- //唤醒迁移线程
- pthread_cond_wait(&maintenance_cond, &cache_lock);
- /* Before doing anything, tell threads to use a global lock */
- mutex_unlock(&cache_lock);
- ...
- mutex_lock(&cache_lock);
- assoc_expand();//申请更大的哈希表,并将expanding设置为true
- mutex_unlock(&cache_lock);
- }
- }
- return NULL;
- }
回马枪:
现在再回过头来再看一下哈希表的插入、删除和查找操作,因为这些操作可能发生在哈希表迁移阶段。有一点要注意,在assoc.c文件里面的插入、删除和查找操作,是看不到加锁操作的。但前面已经说了,需要和迁移线程抢占锁,抢到了锁才能进行对应的操作。其实,这锁是由插入、删除和查找的调用者(主调函数)负责加的,所以在代码里面看不到。
因为插入的时候可能哈希表正在扩展,所以插入的时候要面临一个选择:插入到新表还是旧表?memcached的做法是:当item对应在旧表中的桶还没被迁移到新表的话,就插入到旧表,否则插入到新表。下面是插入部分的代码。
- /* Note: this isn\'t an assoc_update. The key must not already exist to call this */
- //hv是这个item键值的哈希值
- int assoc_insert(item *it, const uint32_t hv) {
- unsigned int oldbucket;
- //使用头插法 插入一个item
- if (expanding &&//目前处于扩展hash表状态
- (oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket)//数据迁移时还没迁移到这个桶
- {
- //插入到旧表
- it->h_next = old_hashtable[oldbucket];
- old_hashtable[oldbucket] = it;
- } else {
- //插入到新表
- it->h_next = primary_hashtable[hv & hashmask(hashpower)];
- primary_hashtable[hv & hashmask(hashpower)] = it;
- }
- hash_items++;//哈希表的item数量加一
- //当hash表的item数量到达了hash表容量的1.5倍时,就会进行扩展
- //当然如果现在正处于扩展状态,是不会再扩展的
- if (! expanding && hash_items > (hashsize(hashpower) * 3) / 2) {
- assoc_start_expand();//唤醒迁移线程,扩展哈希表
- }
- return 1;
- }
这里有一个疑问,为什么不直接插入到新表呢?直接插入到新表对于数据一致性来说完全是没有问题的啊。网上有人说是为了保证同一个桶item的顺序,但由于迁移线程和插入线程对于锁抢占的不确定性,任何顺序都不能通过assoc_insert函数来保证。本文认为是为了快速查找。如果是直接插入到新表,那么在查找的时候就可能要同时查找新旧两个表才能找到item。查找完一个表,发现没有,然后再去查找另外一个表,这样的查找被认为是不够快速的。
如果按照assoc_insert函数那样的实现,不用查找两个表就能找到item。看下面的查找函数。
- //由于哈希值只能确定是在哈希表中的哪个桶(bucket),但一个桶里面是有一条冲突链的
- //此时需要用到具体的键值遍历并一一比较冲突链上的所有节点。因为key并不是以\'\\0\'结尾
- //的字符串,所以需要另外一个参数nkey指明这个key的长度
- item *assoc_find(const char *key, const size_t nkey, const uint32_t hv) {
- item *it;
- unsigned int oldbucket;
- if (expanding &&//正在扩展哈希表
- (oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket)//该item还在旧表里面
- {
- it = old_hashtable[oldbucket];
- } else {
- //由哈希值判断这个key是属于那个桶(bucket)的
- it = primary_hashtable[hv & hashmask(hashpower)];
- }
- //到这里已经确定了要查找的item是属于哪个表的了,并且也确定了桶位置。遍历对应桶的冲突链即可
- item *ret = NULL;
- while (it) {
- //长度相同的情况下才调用memcmp比较,更高效
- if ((nkey == it->nkey) && (memcmp(key, ITEM_key(it), nkey) == 0)) {
- ret = it;
- break;
- }
- it = it->h_next;
- }
- return ret;
- }
删除操作和查找操作差不多,这里直接贴出,不多说了。删除操作也是要进行查找操作的。
- void assoc_delete(const char *key, const size_t nkey, const uint32_t hv) {
- item **before = _hashitem_before(key, nkey, hv);//得到前驱节点的h_next成员地址
- if (*before) {//查找成功
- item *nxt;
- hash_items--;
- //因为before是一个二级指针,其值为所查找item的前驱item的h_next成员地址.
- //所以*before指向的是所查找的item.因为before是一个二级指针,所以
- //*before作为左值时,可以给h_next成员变量赋值。所以下面三行代码是
- //使得删除中间的item后,前后的item还能连得起来。
- nxt = (*before)->h_next;
- (*before)->h_next = 0; /* probably pointless, but whatever. */
- *before = nxt;
- return;
- }
- /* Note: we never actually get here. the callers don\'t delete things
- they can\'t find. */
- assert(*before != 0);
- }
- //查找item。返回前驱节点的h_next成员地址,如果查找失败那么就返回冲突链中最后
- //一个节点的h_next成员地址。因为最后一个节点的h_next的值为NULL。通过对返回值
- //使用 * 运算符即可知道有没有查找成功。
- static item** _hashitem_before (const char *key, const size_t nkey, const uint32_t hv) {
- item **pos;
- unsigned int oldbucket;
- if (expanding &&//正在扩展哈希表
- (oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket)
- {
- pos = &old_hashtable[oldbucket];
- } else {
- //找到哈希表中对应的桶位置
- pos = &primary_hashtable[hv & hashmask(hashpower)];
- }
- //到这里已经确定了要查找的item是属于哪个表的了,并且也确定了桶位置。遍历对应桶的冲突链即可
- //遍历桶的冲突链查找item
- while (*pos && ((nkey != (*pos)->nkey) || memcmp(key, ITEM_key(*pos), nkey))) {
- pos = &(*pos)->h_next;
- }
- //*pos就可以知道有没有查找成功。如果*pos等于NULL那么查找失败,否则查找成功。
- return pos;
- }
由上面的讨论可以知道,插入和删除一个item都必须知道这个item对应的桶有没有被迁移到新表上了。
以上是关于memcached中hash表相关操作的主要内容,如果未能解决你的问题,请参考以下文章