hadoop分布式搭建
Posted 黑曼巴后仰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop分布式搭建相关的知识,希望对你有一定的参考价值。
一,前提:下载好虚拟机和安装完毕Ubuntu系统。因为我们配置的是hadoop分布式,所以需要两台虚拟机,一台主机(master),一台从机(slave)
选定一台机器作为 Master 在 Master 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
在 Master 节点上安装 Hadoop,并完成配置
在其他 Slave 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
将 Master 节点上的 /usr/local/hadoop 目录复制到其他 Slave 节点上
在 Master 节点上开启 Hadoop
二,在Ubuntu中打开终端,可使用快捷键ctrl+alt+t
1.首先要搭建好java环境,这时候,Ubuntu安装的时候默认是nat的网络连接,可通过执行命令:
sudo apt-get install openjdk-8-jre openjdk-8-jdk
回车,这时候会要求你输入密码,就是安装的时候 你自己设置的密码,输入密码你是不到的,不管它,直接回车,下载的时候会需要一些时间
下载完毕后,还要安装 ssh 和 vim
同样的做法: sudo apt-get install openssh-server
sudo apt-get install vim
执行 apt-get 命令的时候要保证网络是通的
2,好,这时候已经下载完毕,java默认路径是在 /usr/lib/jvm/java-8-openjdk-amd64
我们这时候要配置java环境变量,在终端输入 :
vim ~/.bashrc
回车
你就进到一个文件里面,这时候按快捷键 shift+G,跳到文件的最后面部分,你发现,不能够写入数据,按 i ,进入 insert 模式,这时候输入
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
写入完毕,按 esc 然后 shift+冒号(shift + :),然后 wq (保存并退出)
3,回到终端,输入
source ~/.bashrc
使环境变量生效
4. 在终端输入 javac -version出现 java的版本号则说明配置成功
三,ssh实现无密码登录
1. 
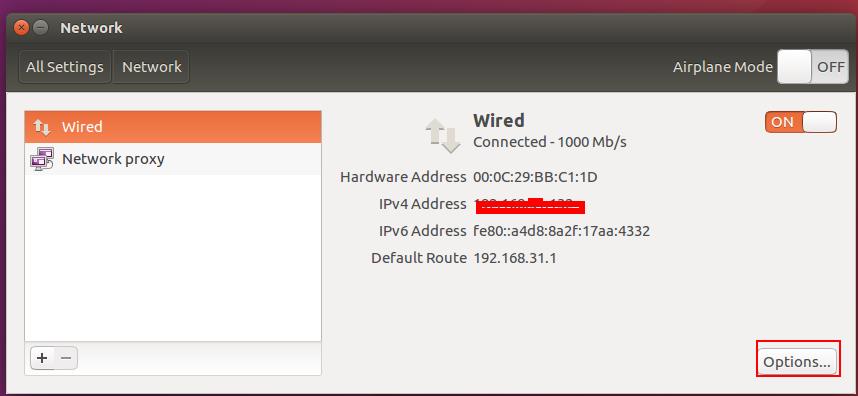
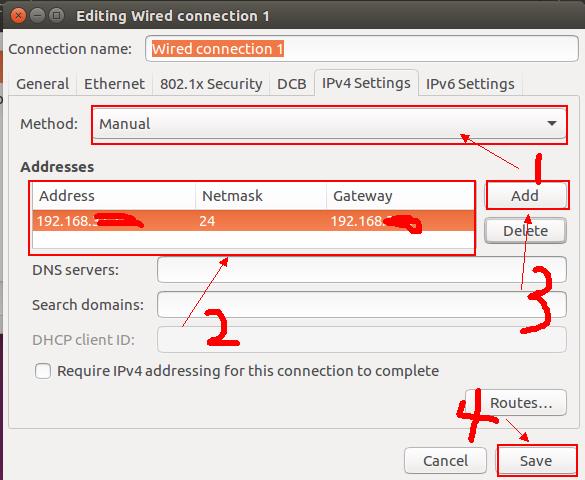
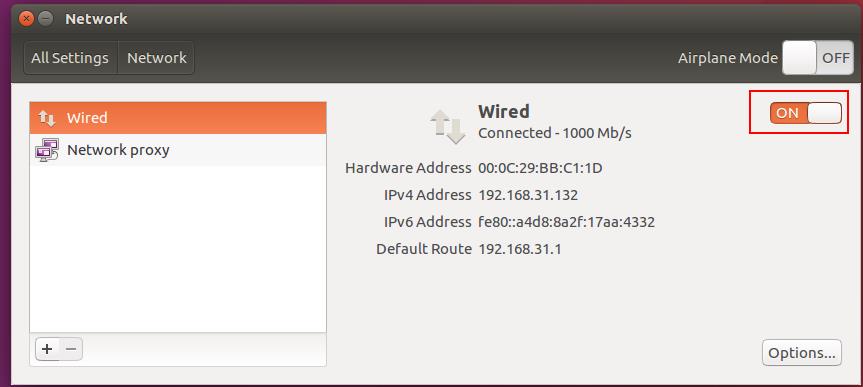
这时候操作是在master(主机)上,第四张图按两下,其中ip要怎么改呢?,打开你的本机的doc窗口,输入ipconfig,假如你的ip是192.168.41.128,则你的如图所示的ip改为192.168.41.129,记得保存,时候你的虚拟机的网络方式要由默认的 nat 改为桥接模式,怎么改?虚拟机主页左上角有个虚拟机,设置,网络适配器,改为桥接模式,确定。
由于我们要配置的是hadoop分布式,一个主机一个从机,主机名是master,从机是slave
2. vim /etc/hostname
修改你的用户名为master
同样在slave中的 /etc/hostname改为slave
3. vim /etc/hosts
添加 :192.168.31.129 master
192.168.41.130 slave
重启
通过ping master和ping slave 是否成功
4. ssh-keygen -t rsa
一直回车,生成公匙
cat ./id_rsa.pub >> ./authorized_keys
授权
5. ssh localhost
会看到一个welcome页面,不用输入密码,要是还要输入密码,那就是前面的步骤出错了
scp ./authorized_keys 192.168.41.130:/home/hadoop/.ssh
// 这个直接把授权好的钥匙复制到slave上。若是slave上没有.ssh目录,则先生成该目录,一般都有的,
这一步完成后,执行
ssh slave
不用输入密码就可以登录slave。出现欢迎页面,到这里,完成Ubuntu无密码登录
四,hadoop的安装与配置
1. 首先把下载好的hadoop压缩包解压到指定的文件夹 (hadoop文件:链接:https://pan.baidu.com/s/1kVahwYb 密码:qzpi)
解压hadoop
sudo tar -zxf hadoop-2.7.4.tar .gz -C /usr/local
这时候的hadoop文件的压缩包是在 /home/hadoop 下,若是操作失败,检查该路径下是否有需要操作的文件
2. cd /usr/local
// 进入该路径,ls 看一下解压后的hadoop文件是否存在
sudo mv hadoop-2.7.4 hadoop
// 改hadoop-2.7.4为hadoop,改个文件名而已
sudo chown -R hadoop ./hadoop
// -R把hadoop下的所有文件和文件夹都改变所属用户为hadoop用户
cd hadoop
bin/hadoop version
// 测试hadoop是否安装成功,若出现版本号,则说明安装成功
3.接下来配置hadoop环境变量
vim ~/.bashrc
添加
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP/sbin
同样的
source ~/.bashrc
使环境变量生效
4.修改5个配置文件
slave
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
<1> vim /usr/local/hadoop/etc/slave
添加
salve
<2> vim /usr/local/etc/hadoop/core-site.xml


<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://Master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> </property> </configuration>
<3> vim /usr/local/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>Master:50090</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>
<4> vim /usr/local/etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>Master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>Master:19888</value> </property> </configuration>
<5> vim /usr/local/etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
5.配置好后,将 Master 上的 /usr/local/Hadoop 文件夹复制到各个节点上。如果之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。在 Master 节点上执行: tar -zcf ~/hadoop.master.tar.gz ./hadoop
cd ~
scp ./hadoop.master.tar.gz slave:/home/hadoop
在slave上执行
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop
同样,如果有其他 Slave 节点,也要执行将 hadoop.master.tar.gz 传输到 Slave 节点、在 Slave 节点解压文件的操作。
首次启动需要先在 Master 节点执行 NameNode 的格式化:
hdfs namenode –format
如果是centos系统,需要关闭防火墙
这里可能会出现java环境配置不被发现的错误,只需要
vim /usr/local/etc/hadoop/hadoop.env.sh
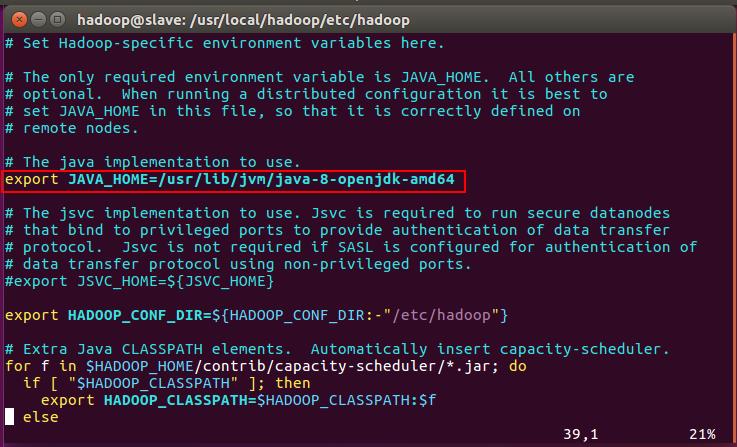
记得source ~/.bashrc
接着可以启动 hadoop 了,启动需要在 Master 节点上进行:
start-dfs.sh
start-yarn.sh
通过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、
在 Slave 节点可以看到 DataNode 和 NodeManager 进程,大功告成!!!
第一次写文档,不足之处,请见谅
以上是关于hadoop分布式搭建的主要内容,如果未能解决你的问题,请参考以下文章