微信小程序抓包与逆向+微信小程序反编译教程+解包教程+解包工具
Posted ONExiaobaijs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微信小程序抓包与逆向+微信小程序反编译教程+解包教程+解包工具相关的知识,希望对你有一定的参考价值。
免责声明
做视频的初衷是为了学习交流,是想让自己在分享过程中学习到更多的东西
本人发布的视频、环境、软件、脚本、文章、资料等,都只用于学习交流安全技术,请不要用于任何非法用途, 否则后果自付
部分技术来源于技术网站:www.baipaizhong.com
这是我接的一个单子,一个大学生要搞一个他们自己学习的图书馆预约系统。不想早起还想抢到位置。
上来先梭哈分析,毕竟预约嘛,那肯定需要分析包,当开始抓包的哪一个,心里默念了很多我 ** 你的大 **
,因为以前用的抓包工具都抓不到了,记录下时间2022-11-11。那该怎么办,单子接了,不能放弃。
解决抓不到包的难题。
因为微信好像现在使用了云,所以一般的手段应该都抓不到了,最近更新的。
我知道的两种微信小程序办法
- hook他pc逆向的对这个很熟悉。ipad的协议他们好像也是这样做的,没学习过只是简单的了解。这是一种
- 就是通过反编译,也是我们这篇文章介绍的。用反编译工具反编译出来。然后导入微信小程序开发者里面进行调试,相当于你拿到了代码,那后面你想要什么不都是有了。这样抓包自然不在话下。
当进行到这一步,抓包不是简简单单
上图
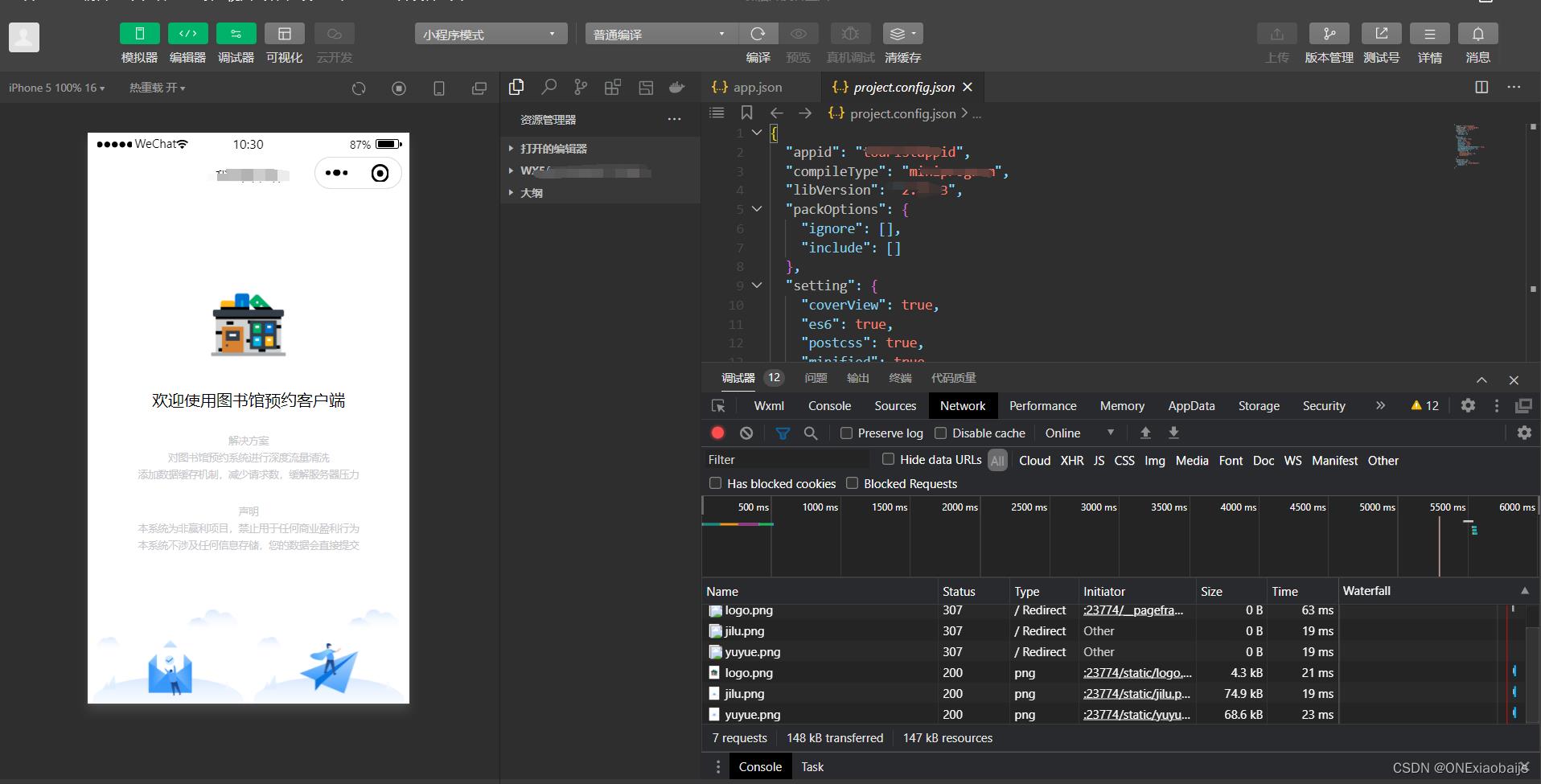
实现第二种抓包方法
一、工具准备(百度免费,找我知识付费)
- 解密工具
- 逆向工具
目前用的是:wxappxxxxcker
 这个是一个大神开发的,之前可以在github下载,不过截止今天,大神已经关闭了下载,具体原因……你懂得。不过,开源是趋势,就像这个世界是不会停止开放的,因此我们还是有很多渠道可以获取,你可以通过自己的渠道获取
这个是一个大神开发的,之前可以在github下载,不过截止今天,大神已经关闭了下载,具体原因……你懂得。不过,开源是趋势,就像这个世界是不会停止开放的,因此我们还是有很多渠道可以获取,你可以通过自己的渠道获取
二、解密小程序
网上有很多教程,是用root过的手机提取小程序包,其实不用那么麻烦,直接用微信PC客户端就可以了。
1.建议修改微信PC端默认的小程序包位置
默认是在C盘,太占内存,建议修改
2.打开一个小程序
推荐一种做法,
打开这里你设置路径文件夹后(如下图),退出微信,删除这个文件夹下面左右内容
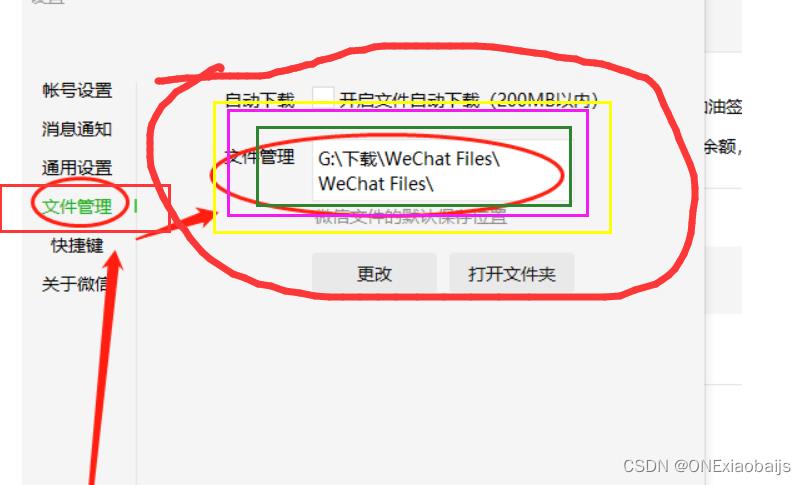
然后在pc端打开一个小程序,尽可能点开所有的页面,让本地自动生成一个本地包,在刚刚设置好的文件夹(如上图)里,内容如下:
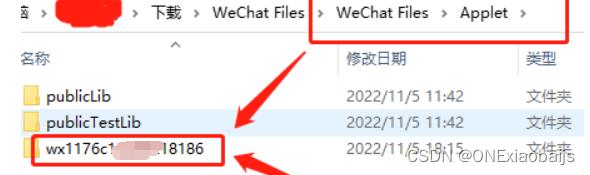
进入箭头指向文件夹里面,不过里面的是加密过的文件:APP.wxapkg就需要用到我们前面的解密软件。
3.解密小程序包
软件长这样:
选择加密小程序包
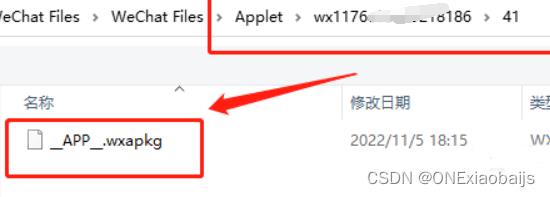
0.1秒解密成功:
解密之后的文件名是:
1 wx4f11048xxxxxxx66.wxapkg
会存放在wxpack文件夹:
三、逆向小程序
正式用到大神开发的【wxappxxxxker】了。下面的操作,都是在cmd命令窗口中操作的,需要强调的是,必须在wxapxxxxker路径里才可以,简易方法是,直接在【wxapxxxer】文件夹的地址栏里输入cmd即可。
如果跟我一样放在桌面,出来的就是这样:
1、检查nodejs 输入node -v检查是否已安装nodejs
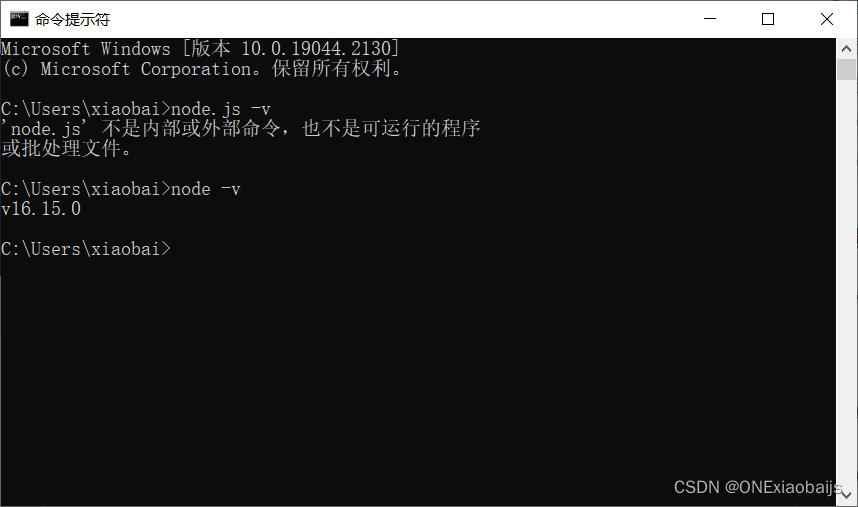
如果没有安装nodejs,请先安装。下载地址:https://nodejs.org/en/安装nodejs一直点击下一步安装即可。
2、安装依赖
依次输入下面7个npm install,分别一个一个安装
- npm install esprima
- npm install css-tree
- npm install cssbeautify
- npm install vm2
- npm install uglify-es
- npm install js-beautify
3、正式逆向
输入:
bingo.bat 主包路径(可以直接拖入)
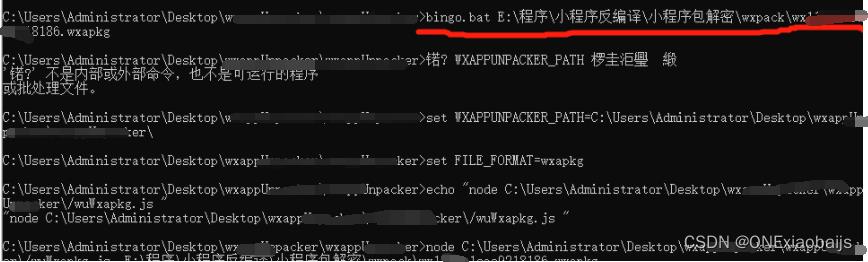
编译后的文件,保存在和【wx4f11xxxxxxxc766.wxapkg】同一个文件夹中,自动以wxxxxxx3xxxx766命名。
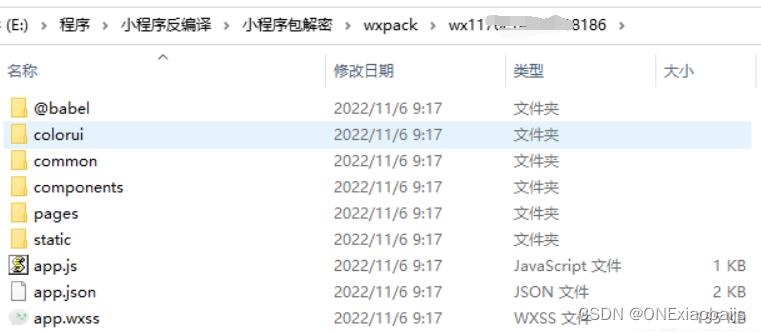
编译完成,接下来直接使用微信开发工具打开,即可学习前辈们的前端设计了,骚年。
4、可能的错误
①、如果在执行编译命令时报
this package is a subPackage which should be unpacked with -s=.
说明这个是分包,打开小程序时生成了两个.wxapkg文件,编译另一个文件即可,编译分包和主包的命令是不一样的:
node ./wuWxapkg.js 分包路径 -s=主包路径
②、如果生成的文件里不包含app.json文件
说明你找的小程序,是大神开发的,已经做了反编译的安全措施,所以解密失败,这也是我发这篇文章的目的。
不过这种大神目前还是比较少见的,你会成为未来的那一个吗?加油,骚年,欧力给!
效果截图
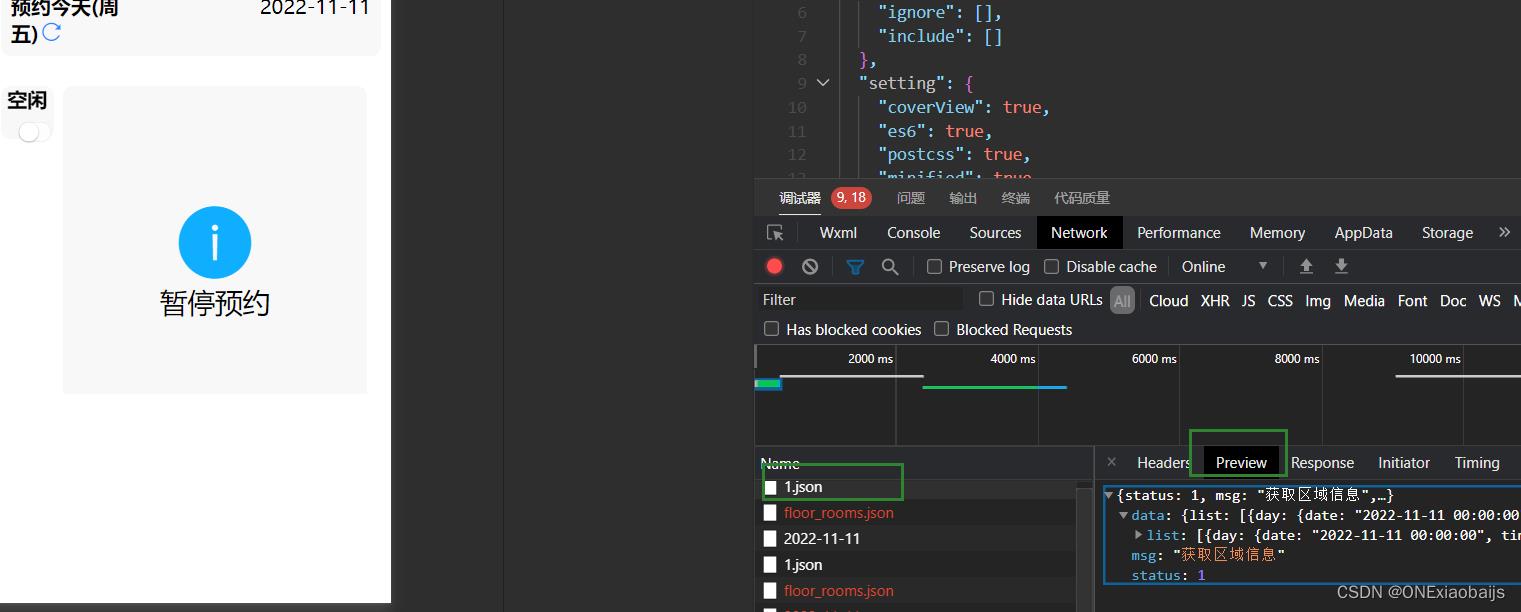
这个跟浏览器抓包一模一样.可以尽情的抓包了
四、结束语
好了,微信小程序反编译教程+解包教程+解包工具的使用以及抓包分析完毕,已经为大家分享完毕;
微信小程序 Spdier - OfferShow 反编译逆向
微信小程序 Spdier - OfferShow 反编译逆向(一)
文章目录
前言
本文需要使用到的工具有:
Charles抓包工具、夜神模拟器、微信开发者工具、wxapkg反编译工具CrackMinApp;
提示:需要安装好Charles和夜神模拟器并配置好App抓包环境,以及安装好微信开发者工具 / 反编译工具CrackMinApp
Charles&夜神模拟器安装教程:https://blog.csdn.net/EXIxiaozhou/article/details/127767808
微信开发者工具 / 反编译工具CrackMinApp 下载安装:https://blog.csdn.net/EXIxiaozhou/article/details/128110468
该文章涉及到App抓包以及微信小程序反编译逆向等相关的Spider技术
提示:以下是本篇文章正文内容,下面案例可供参考
一、任务说明
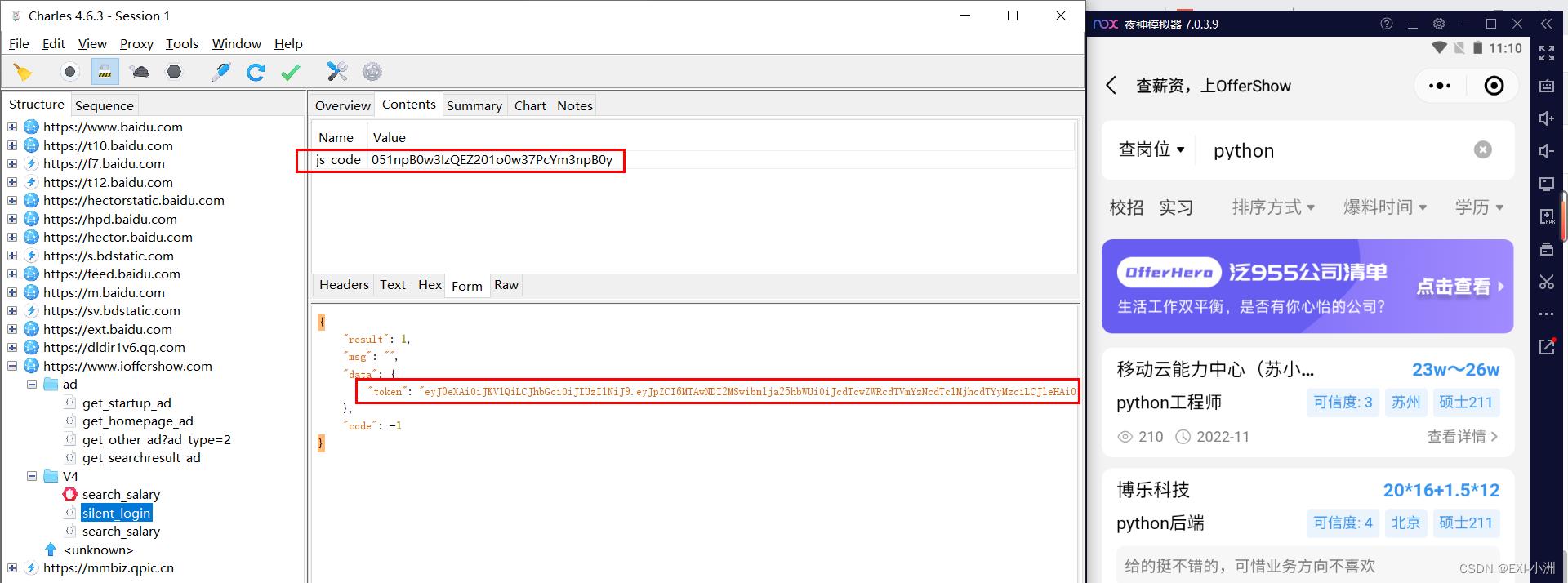
1.尝试反编译分析出js_code参数的生成方式,用来获取token
2.将小程序搜索出来的数据保存至本地excel
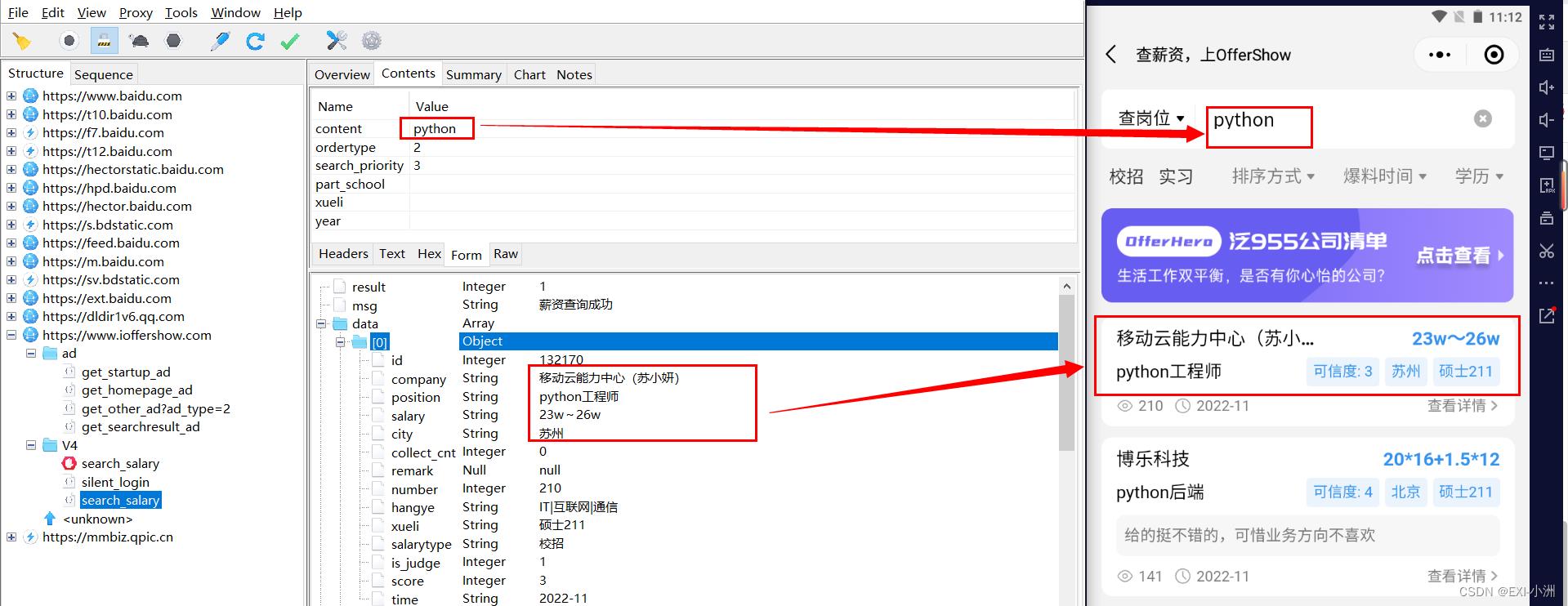
二、微信小程序抓包 - 分析
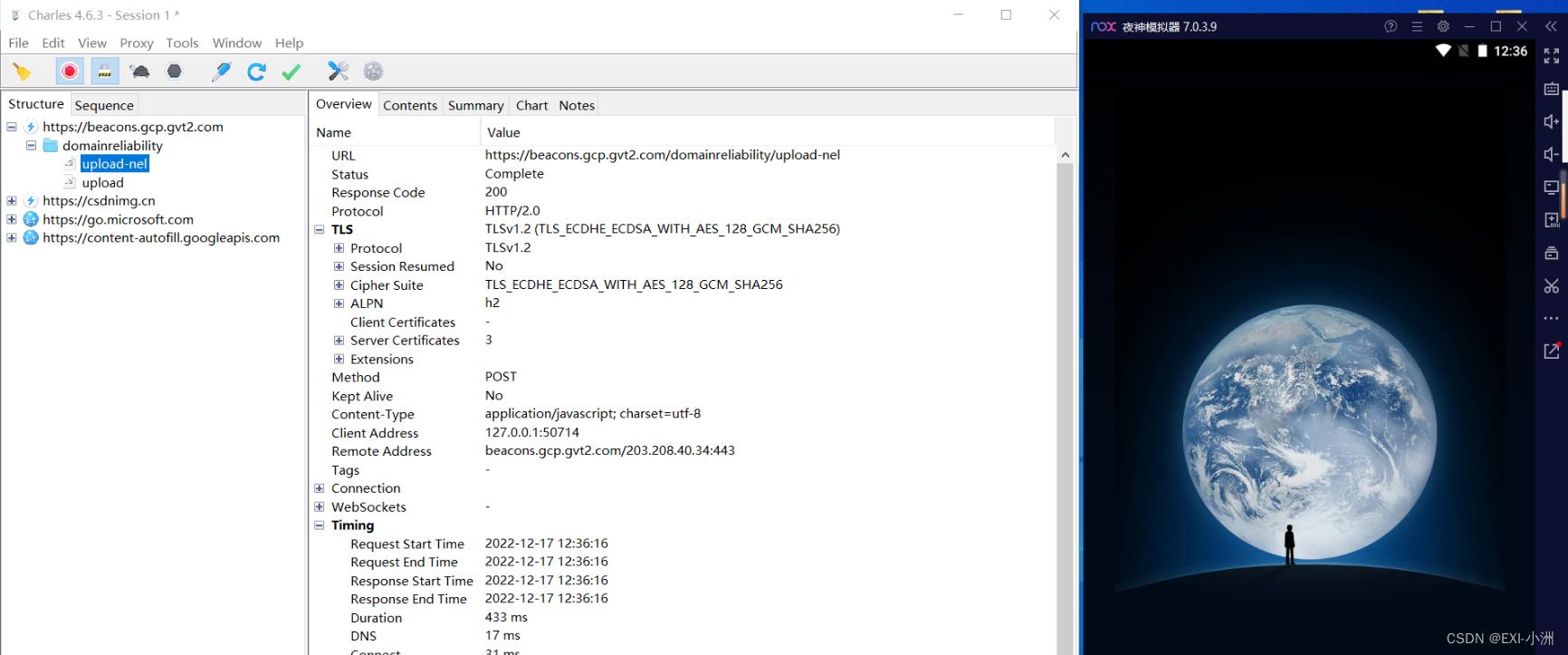
1、打开Charles抓包工具,启动模拟器,进入微信
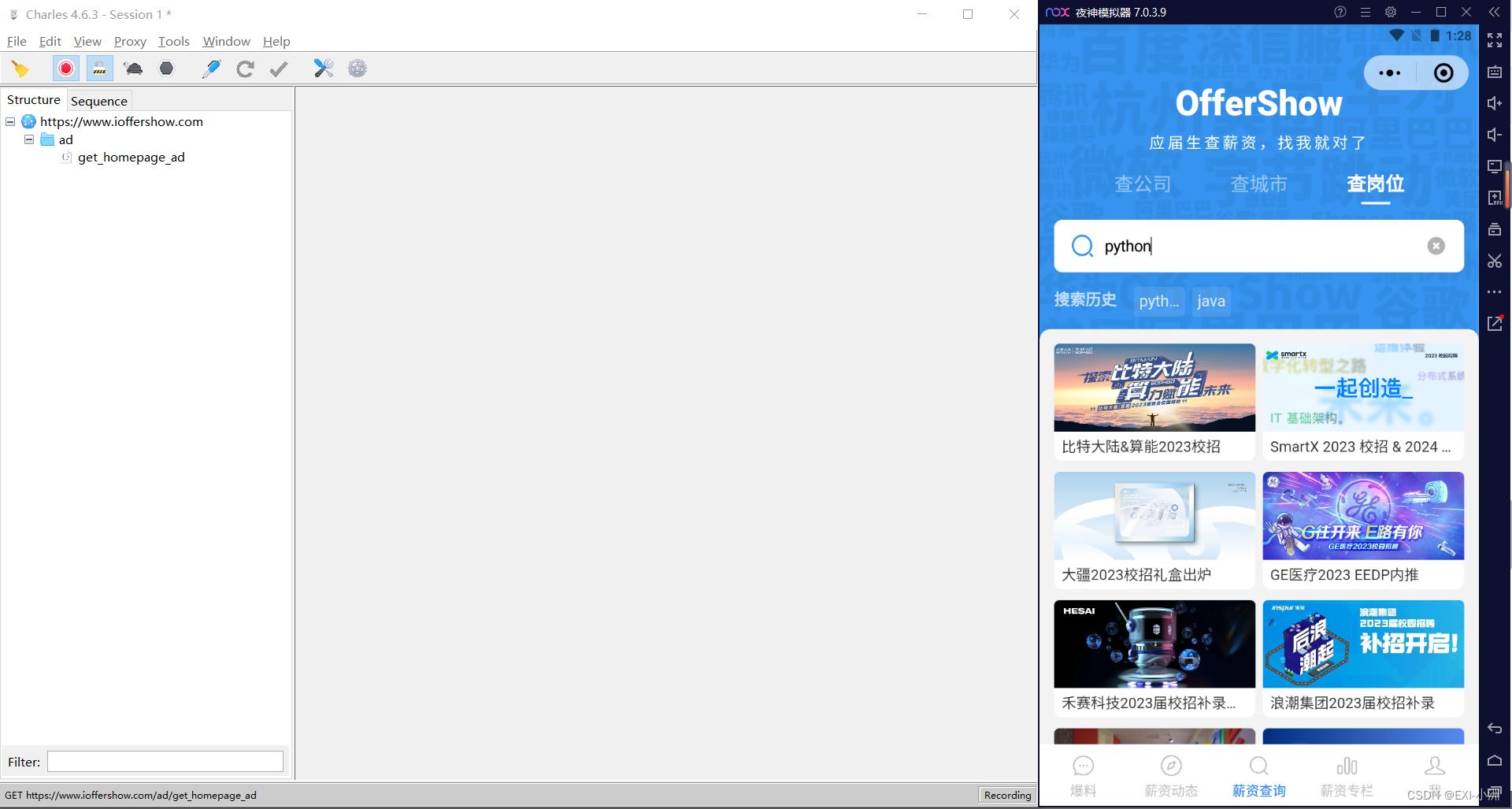
2、搜索小程序offershow,打开进入,岗位搜索,输入关键词:“python”
3、生成token接口分析,接口url:https://www.ioffershow.com/V4/silent_login
提示:第一次打开,需要请求这个接口提交js_code参数才能拿到token,headers添加一个token即可风雨无阻
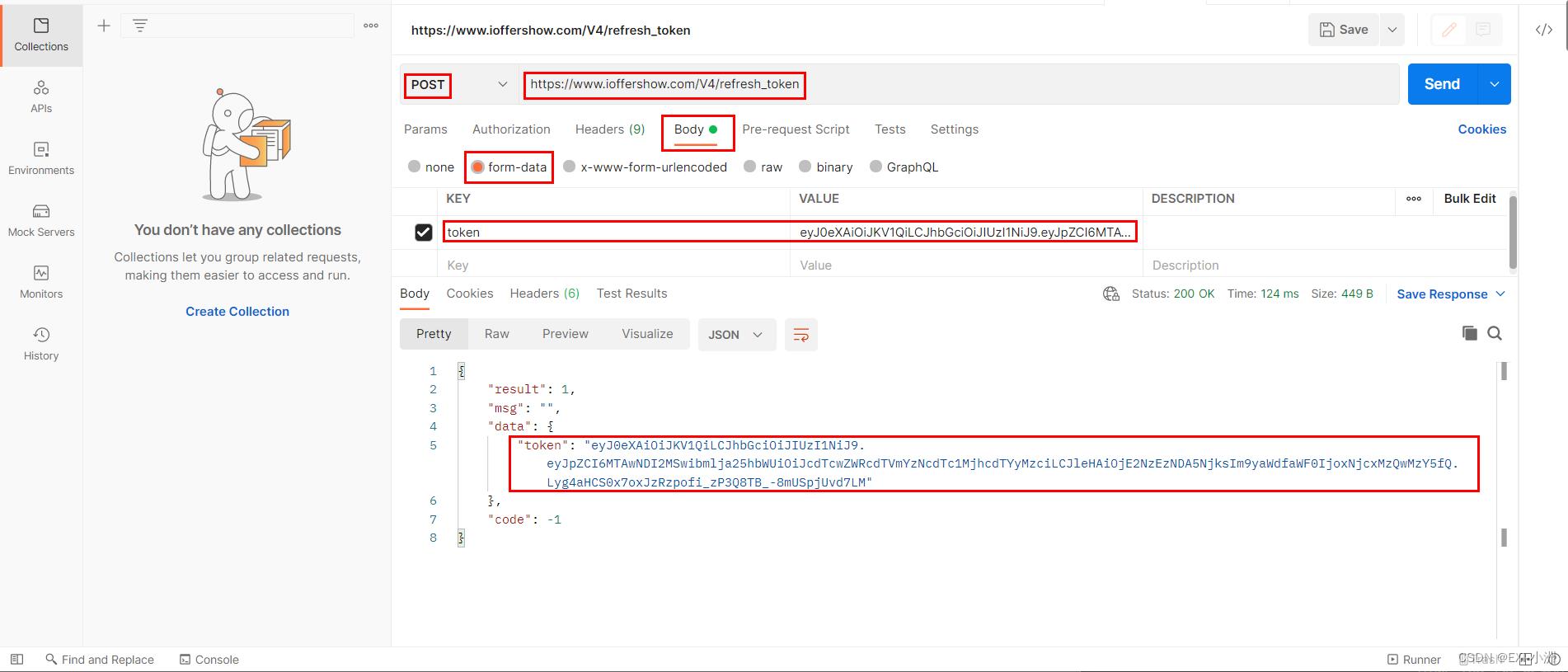
4、刷新token接口分析,小程序每隔一段时间会刷新token
接口url:https://www.ioffershow.com/V4/refresh_token
请求该接口时,提交当天服务器返回的任意一个token,即可请求成功获得新的token;
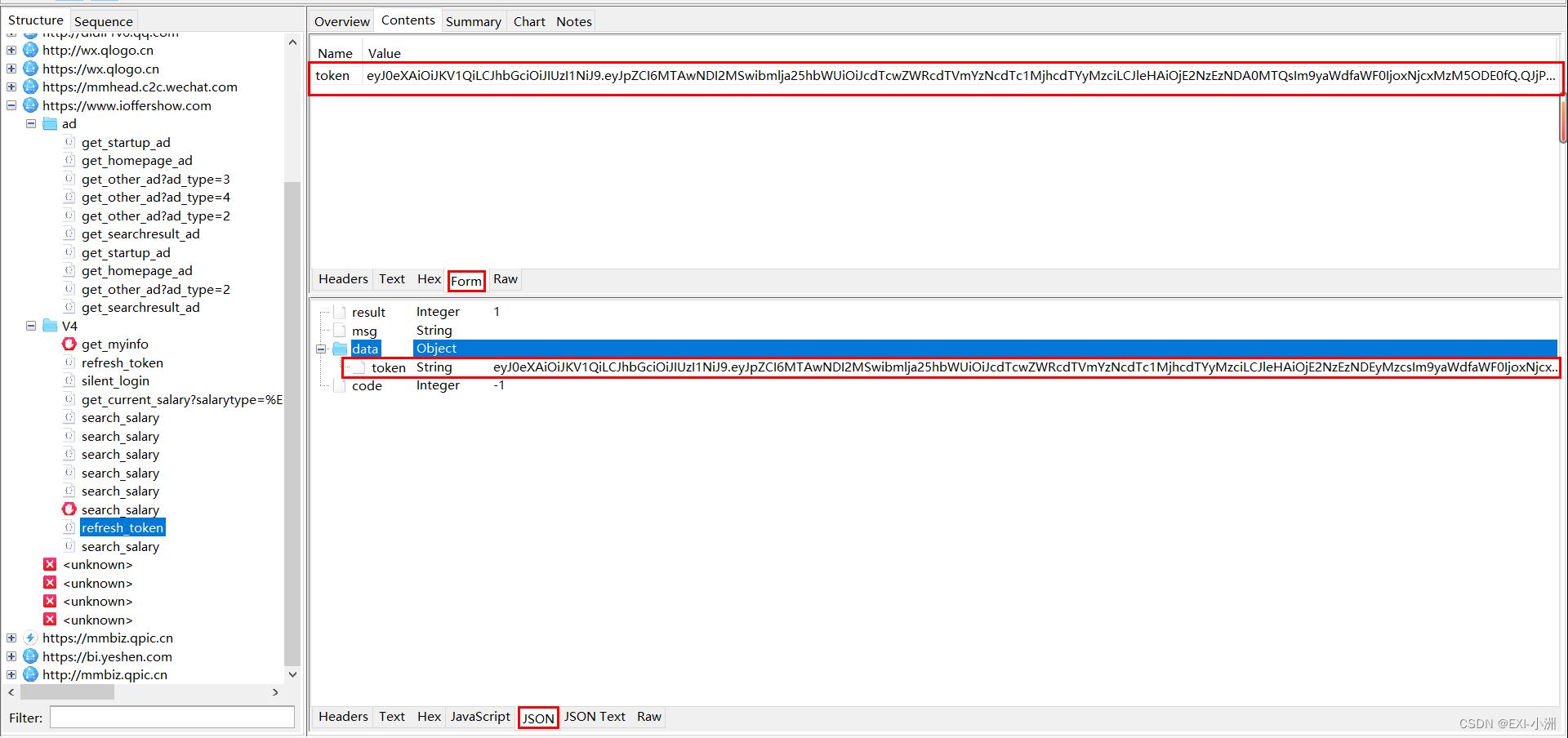
下图使用postman工具模拟请求刷新token接口,Postman API测试工具 基本使用:https://blog.csdn.net/EXIxiaozhou/article/details/128333884
5、search_salary、根据关键词进行接口请求,url:https://www.ioffershow.com/V4/search_salary

可以看到返回的json数据
三、wxapkg反编译 - 分析
1.在夜神模拟器获取微信程序员的包
1.1 获取wxapkg的地址
方式一、直接全局搜索文件后缀(.wxapkg)
点击右侧的任意处,再点击右上侧的三个点,选择搜索,输入.wxapkg
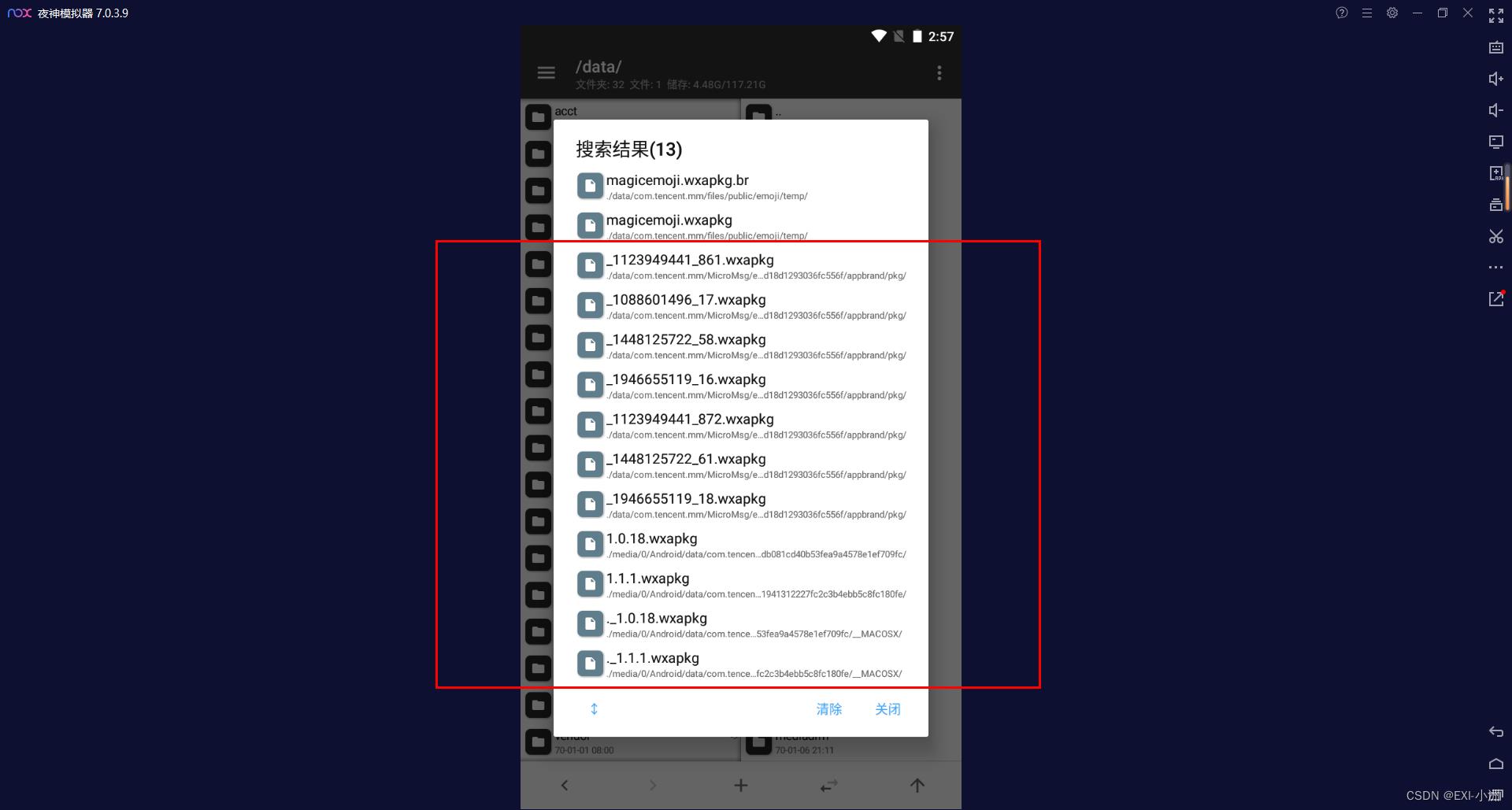
方法二、一般具体的文件目录地址是:/data/data/com.tencent.mm/MicroMsg/一串16进制字符/appbrand/pkg/
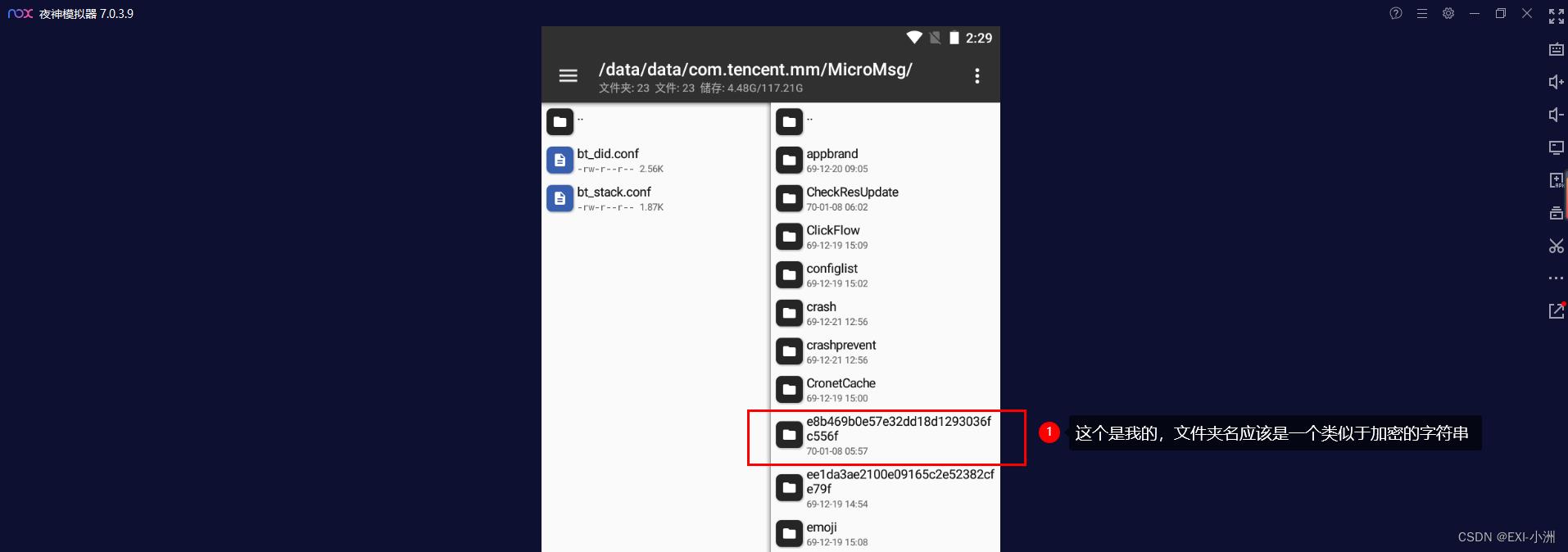
1.2 删除wxapkg文件重新生成
区分那些包是属于offershow小程序
- 1.需要将微信的OfferShow小程序清除掉,再退出微信
- 2.将原来已经生成的所有wxapkg文件删除
- 3.重新登录微信,再次打开小程序再生成新的wxapkg文件
- 4.再次打开模拟器存放wxapkg文件的目录,里面出现的wxapkg文件都属于OfferShow
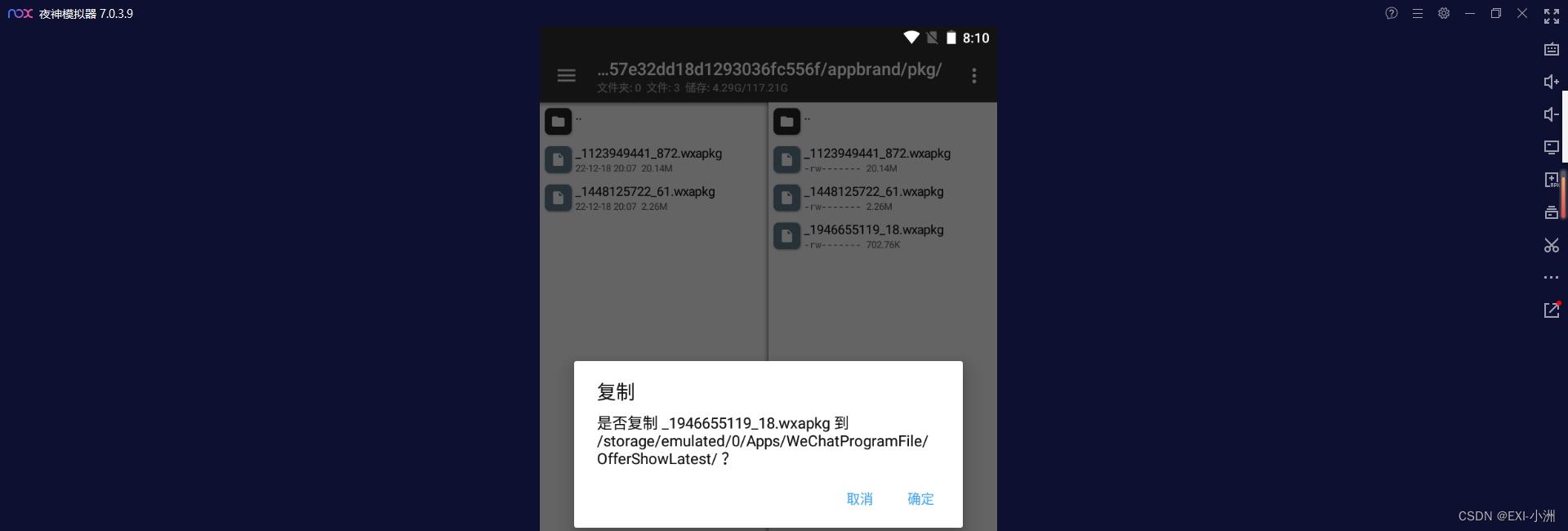
1.3 复制wxapkg文件至windows目录,用来反编译调试
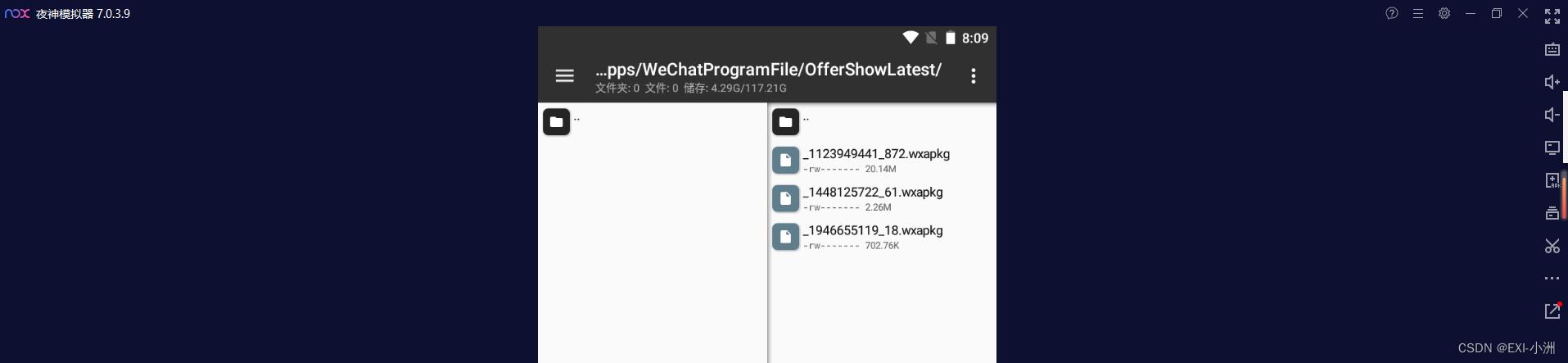
路径:/data/data/com.tencent.mm/MicroMsg/e8b469b0e57e32dd18d1293036fc556f/appbrand/pkg/
左侧找到windows本地目录,右侧找到模拟器存放wxapkg文件的目录,长按文件选择复制即可,全部复制;
2.使用CrackMinApp对.wxapkg文件进行反编译
1、将.wxapkg文件复制到CrackMinApp-master\\wxapkg目录;
微信开发者工具 / 反编译工具CrackMinApp 下载安装:https://blog.csdn.net/EXIxiaozhou/article/details/128110468
2、
将三个.wxapkg文件依次反编译,区分主包和依赖包,真正的小程序包大小1M左右,而依赖包大小2、3M甚至更多,将依赖包复制放入主包;
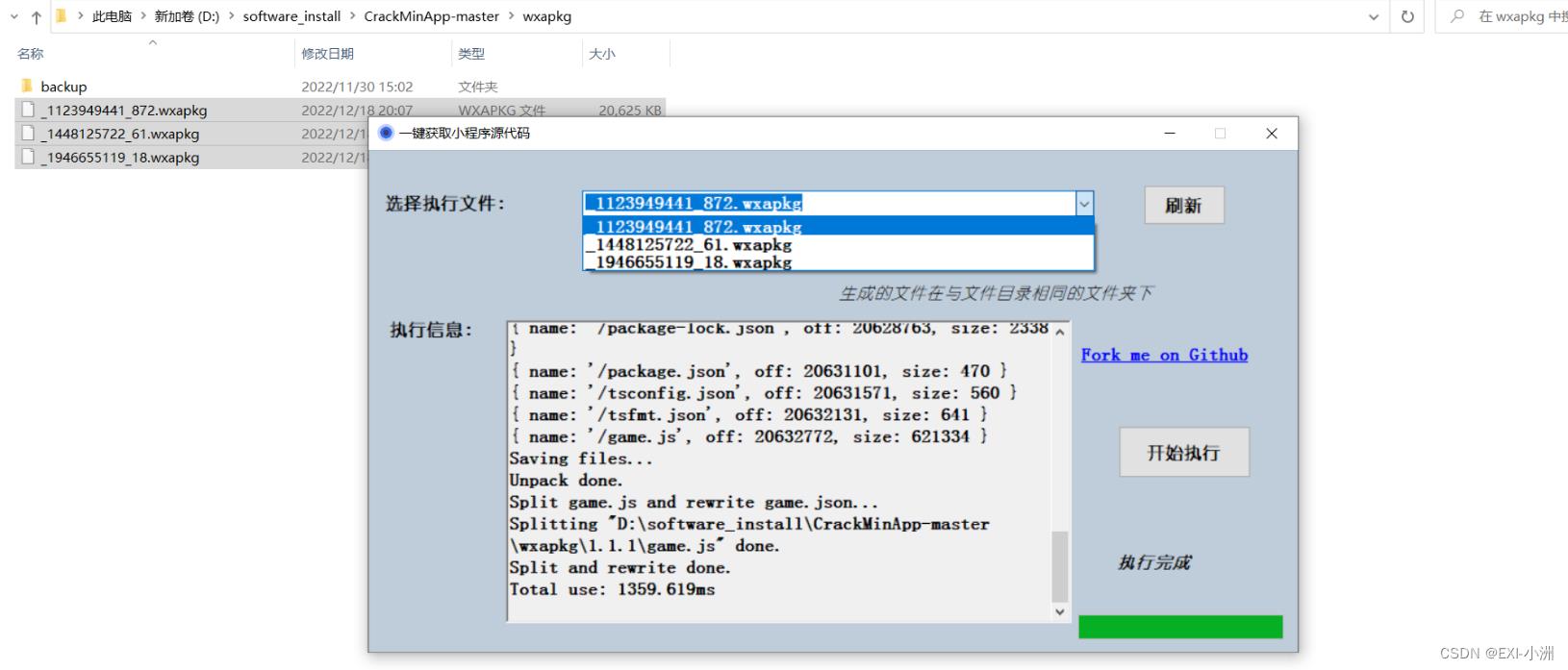
反编译之后的主包
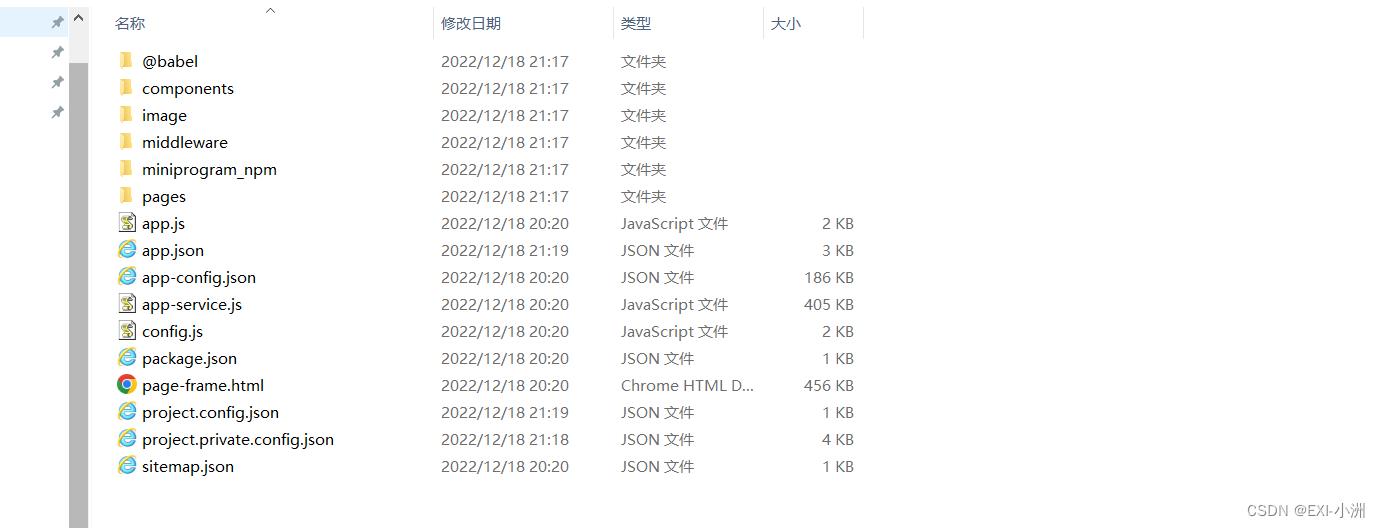
3.使用微信开发者工具打开反编译好的主包开始调试
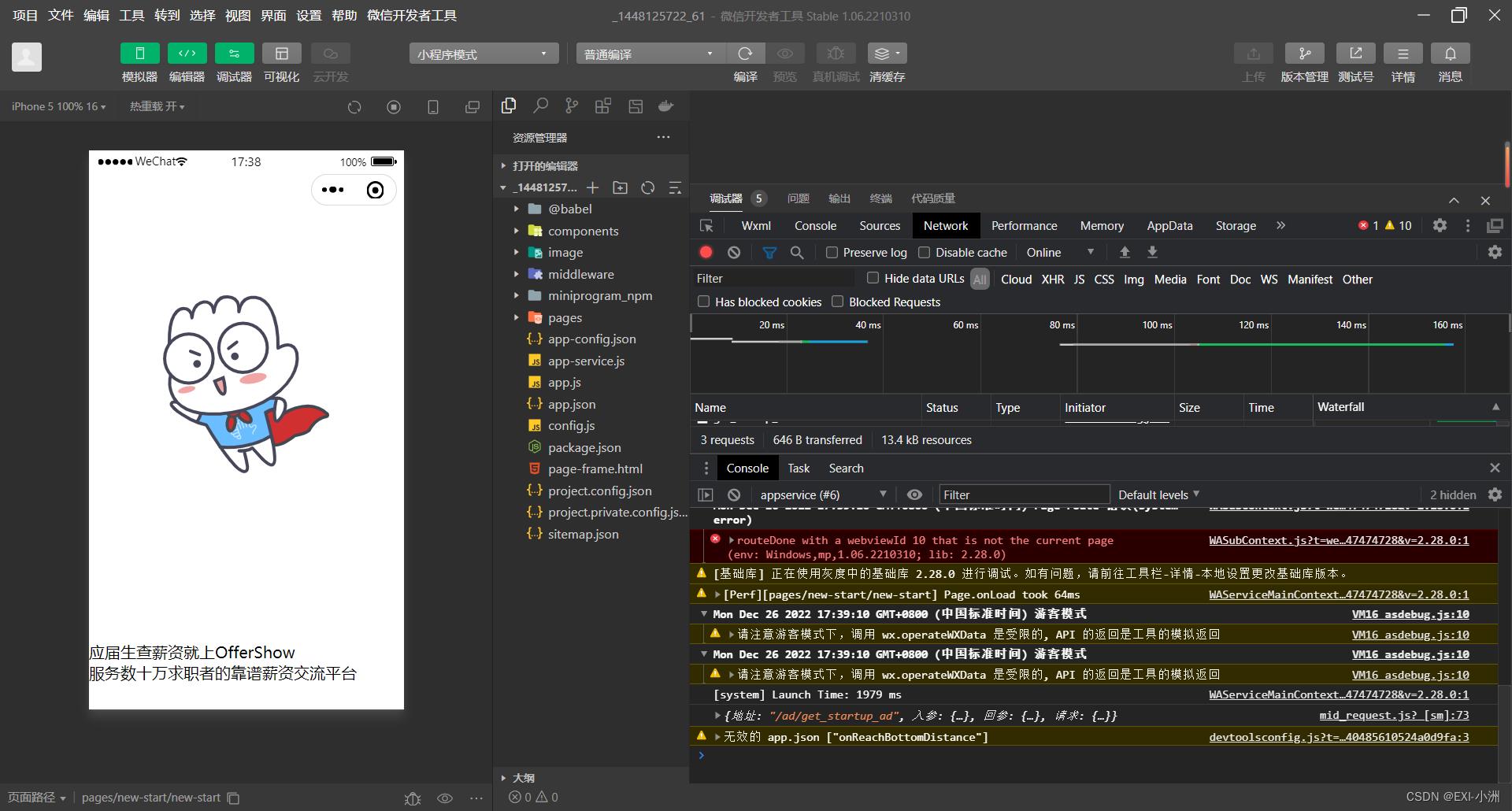
4.分析结果
我调试到最后,发现js_code的加密代码被隐藏了,到此结束,如果有大佬知道加密方式的话,欢迎在评论处指教,非常感谢;
我的做法是手动复制当天服务器返回的token去请求刷新token的接口,拿到最新的token去请求查询薪资的接口,最后将数据保存至xlsx;
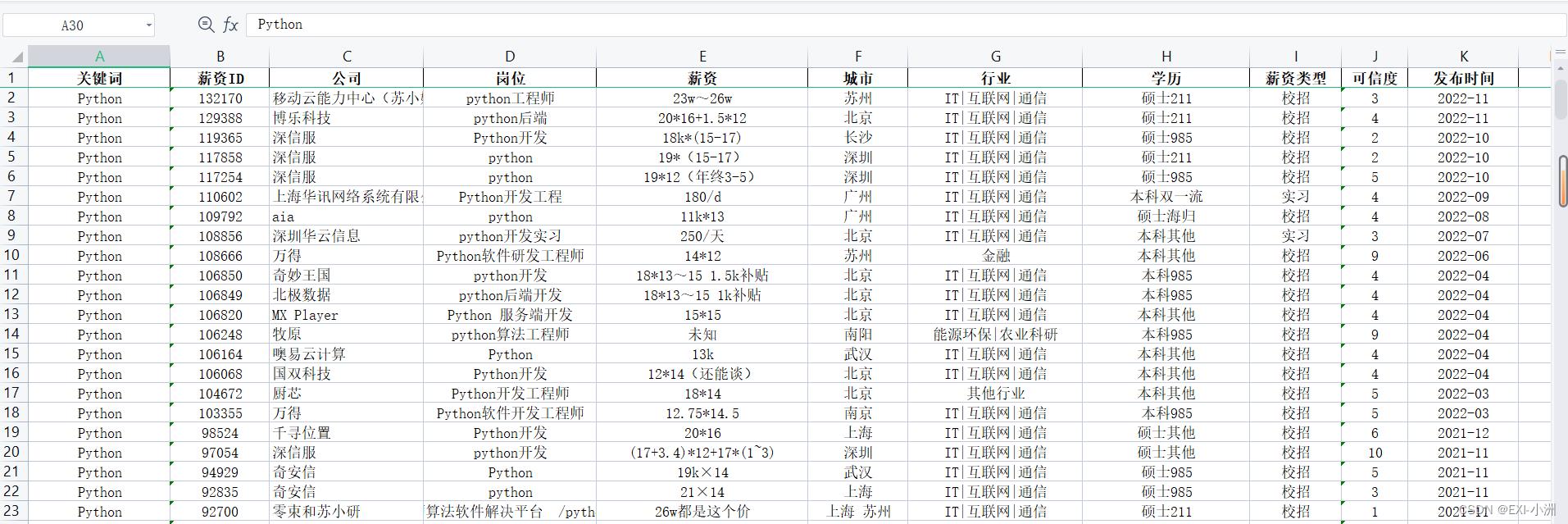
四、运行结果
输出xlsx文件
五、示例代码
import os
import time
import requests
import pandas as pd
class OfferShow(object):
def __init__(self):
# 当天的任意token
self.ord_token = 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpZCI6MTAwNDI2MSwibmlja25hbWUiOiJcdTcwZWRcdTVmYzNcdTc1MjhcdTYyMzciLCJleHAiOjE2Njk2NDY0OTEsIm9yaWdfaWF0IjoxNjY5NjQ1ODkxfQ.cWukvcTzgtQGyIVjzRT4Lr2Dcm1Y3Nnfov-bEX0QwfY'
self.headers =
'User-Agent': 'Mozilla/5.0 (Linux; Android 7.1.2; SM-G9810 Build/QP1A.190711.020; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/92.0.4515.131 Mobile Safari/537.36 MMWEBID/5551 MicroMessenger/8.0.30.2260(0x28001E3A) WeChat/arm32 Weixin NetType/WIFI Language/zh_CN ABI/arm32 MiniProgramEnv/androidUser-Agent Mozilla/5.0 (Linux; Android 7.1.2; SM-G9810 Build/QP1A.190711.020; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/92.0.4515.131 Mobile Safari/537.36 MMWEBID/5551 MicroMessenger/8.0.30.2260(0x28001E3A) WeChat/arm32 Weixin NetType/WIFI Language/zh_CN ABI/arm32 MiniProgramEnv/android',
'content-type': 'application/x-www-form-urlencoded',
'token': self.ord_token,
'Accept-Encoding': 'gzip,compress,br,deflate'
self.xueli = ''
self.result_file_path = 'OfferShow_salary.csv'
def get_token(self):
refresh_token_url = 'https://www.ioffershow.com/V4/refresh_token'
form_data =
'token': self.ord_token
token_response = requests.post(url=refresh_token_url, headers=self.headers, data=form_data)
token = token_response.json()['data']['token']
print("token获取成功:", token)
return token
def search_salary(self, keyword):
salary_url = 'https://www.ioffershow.com/V4/search_salary'
from_data =
'content': keyword,
'ordertype': 2,
'search_priority': 3,
'part_school': '',
'xueli': self.xueli,
'year': ''
salary_response = requests.post(url=salary_url, headers=self.headers, data=from_data)
json_data = salary_response.json()['data']
for item in json_data:
content = f"keyword,item['id'],item['company'].replace(',', ','),item['position'].replace(',', ',')" \\
f",item['salary'].replace(',', ','),item['city'].replace(',', ',')," \\
f"item['hangye'].replace(',', ','),item['xueli'],item['salarytype'],item['score'],item['time']"
content = content.replace('\\n', '').replace('\\n', '') + '\\n'
self.csv_save(content=content)
print("写入成功:", content, end='')
def create_csv_file(self):
if os.path.exists(self.result_file_path) is False:
with open(file=self.result_file_path, mode='w', encoding='utf-8') as fis:
fis.write('关键词,薪资ID,公司,岗位,薪资,城市,行业,学历,薪资类型,可信度,发布时间\\n')
def csv_save(self, content):
with open(file=self.result_file_path, mode='a+', encoding='utf-8') as fis:
fis.write(content)
def csv_save_as_xlsx(self):
""" 读取csv文件将结果写入xlsx """
filename_prefix = os.path.splitext(self.result_file_path)[0] # 切割文件路径以及后缀
df = pd.read_csv(self.result_file_path, encoding='utf-8', dtype='object')
df.to_excel(f"filename_prefix.xlsx", index=False)
print("csv 转 xlsx 成功!\\n", end='')
def runs(self, keyword_list):
self.create_csv_file()
token = self.get_token()
self.headers['token'] = token
for keyword in keyword_list:
self.search_salary(keyword=keyword)
time.sleep(0.25)
self.csv_save_as_xlsx()
if __name__ == '__main__':
keywords_list = [
'Python', 'Java', 'Php', 'JavaScript', 'Go', 'R语言', 'MATLAB', 'C++', 'C#', '后端', '前端', '算法', '人工智能',
'软件测试', 'IT运维', '数据库', 'VisualBasic'
] # 需要搜索的关键词
obj = OfferShow()
obj.runs(keywords_list)
总结
以上就是今天要讲的内容,本文仅仅简单介绍了微信小程序Spider的基本流程,也留下了一些bug,不过最后是拿到了想要的数据,关于其他的微信小程序Spider案例,请来我的主页查看;
以上是关于微信小程序抓包与逆向+微信小程序反编译教程+解包教程+解包工具的主要内容,如果未能解决你的问题,请参考以下文章