如何获得map的key值
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何获得map的key值相关的知识,希望对你有一定的参考价值。
参考技术A方法1:keySet()
HashMap hashmp = ne HashMap();
hashmp.put("aa", "111");
Set set = hashmp.keySet();
Iterator iter = set.iterator();
while (iter.hasNext())
String key = (String) iter.next();
// printkey
// traverse
for (String key : list.get(pos).keySet() )
myKey = key;
方法2:entrySet()
HashMap map;
Iterator i = map.entrySet().iterator();
while (i.hasNext())
Object obj = i.next();
String key = obj.toString();
// or
while (i.hasNext())
Entry entry = (java.util.Map.Entry)it.next();
entry.getkey();
entry.getValue();
扩展资料:
JavaMap集合
1.Map集合没有继承Collection接口,其提供的是key到value的映射,Map中不能包含相同的key值,每个key只能影射一个相同的value.key值还决定了存储对象在映射中的存储位置。
但不是key对象本身决定的,而是通过散列技术进行处理,可产生一个散列码的整数值,散列码通常用作一个偏移量,该偏移量对应分配给映射的内存区域的起始位置,从而确定存储对象在映射中的存储位置.Map集合包括Map接口以及Map接口所实现的类。
2.Map集合没有继承Collection接口,其提供的是key到value的映射,Map中不能包含相同的key值,每个key只能影射一个相同的value.key值还决定了存储对象在映射中的存储位置。
但不是key对象本身决定的,而是通过散列技术进行处理,可产生一个散列码的整数值,散列码通常用作一个偏移量,该偏移量对应分配给映射的内存区域的起始位置,从而确定存储对象在映射中的存储位置.Map集合包括Map接口以及Map接口所实现的类。
参考资料:博客园-Map / HashMap 获取Key值的方法
如何通过获取map中的key来获得与key对应的value值,进行运算
获取map的key和value的方法分为以下两种形式:
1、map.keySet():先获取map的key,然后根据key获取对应的value;
2、map.entrySet():同时查询map的key和value,只需要查询一次;
注意:当map的value值相等时,根据key值进行排序
很多人都推荐使用entrySet,认为其比keySet的效率高很多。理由是:entrySet方法一次拿到所有key和value的集合;而keySet拿到的只是key的集合,针对每个key,都要去Map中额外查找一次value,从而降低了总体效率。
两种方法对比测试如下:
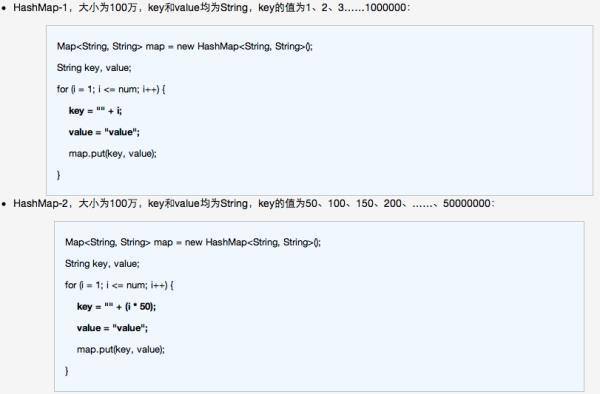
HashMap测试数据:
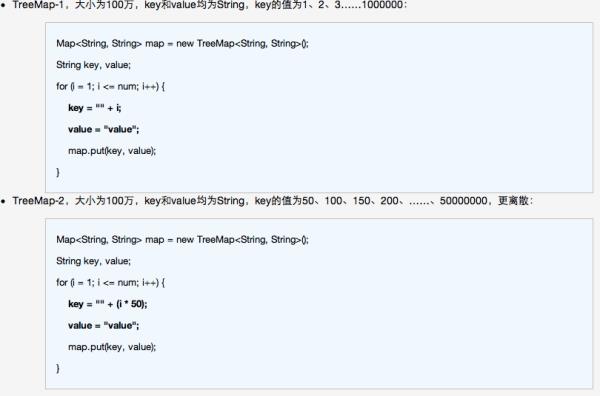
TreeMap测试数据:
扩展资料:
map.keySet()和map.EntrySet()的比较:
一、如果使用HashMap
1、同时遍历key和value时,keySet与entrySet方法的性能差异取决于key的具体情况,如复杂度(复杂对象)、离散度、冲突率等。换言之,取决于HashMap查找value的开销。
entrySet一次性取出所有key和value的操作是有性能开销的,当这个损失小于HashMap查找value的开销时,entrySet的性能优势就会体现出来。
在比测试中,当key是最简单的数值字符串时,keySet可能反而会更高效,耗时比entrySet少10%。总体来说还是推荐使用entrySet。
因为当key很简单时,其性能或许会略低于keySet,但却是可控的;而随着key的复杂化,entrySet的优势将会明显体现出来。当然,我们可以根据实际情况进行选择
2、只遍历key时,keySet方法更为合适,因为entrySet将无用的value也给取出来了,浪费了性能和空间。在上述测试结果中,keySet比entrySet方法耗时少23%。
3、只遍历value时,使用vlaues方法是最佳选择,entrySet会略好于keySet方法。
二、如果使用TreeMap
1、同时遍历key和value时,与HashMap不同,entrySet的性能远远高于keySet。这是由TreeMap的查询效率决定的,也就是说,TreeMap查找value的开销较大,明显高于entrySet一次性取出所有key和value的开销。因此,遍历TreeMap时强烈推荐使用entrySet方法。
2、只遍历key时,keySet方法更为合适,因为entrySet将无用的value也给取出来了,浪费了性能和空间。在上述测试结果中,keySet比entrySet方法耗时少24%。
3、只遍历value时,使用vlaues方法是最佳选择,entrySet也明显优于keySet方法。
参考资料:
百度百科——Map
参考技术A 获取map的key和value的方法分为两种形式:map.keySet():先获取map的key,然后根据key获取对应的value;
map..entrySet():同时查询map的key和value,只需要查询一次;
以下是获取map的key和value,以及map里面的元素通过key或者value来比较大小并排序;
注意:当map的value值相等时,根据key值进行排序
java根据Map的值62616964757a686964616fe59b9ee7ad9431333366303861(value)取键(key) 的实现方法有4种,分别为:
(1)使用for循环遍历
(2)使用Iterator迭代器
(3)使用KeySet迭代
(4)使用EnterySet迭代
下面为以上4种方法具体实现的代码:
1、使用for循环遍历
public static Object getKey(HashMap map, String v)
String key = "";
for (Map.Entry m :map.entrySet())
if (m.getValue().equals(v))
key = m.getKey();
return key;
2.1 循环法
循环法就是通过遍历Map里的Entry,一个个比较,把符合条件的找出来。会有三种情况:
(1)找到一个值
(2)找到多个值
(3)找不到
具体代码如下:
想特别说的一点是,在对比是否相等的时候,使用了Objects.equals(a, b)方法,而不是用a.equals(b)方法。这样可以避免空指针异常。
2.2 Stream方法
Stream总是在多种集合操作上都能提供优雅直观的方法,易写易理解。通过一个过滤器,即可把满足相等条件的值取出来,代码如下:
2.3 Guava的BiMap
Google的Guava提供了BiMap这样一个双向Map,调用inverse()方法会返回一个反向的关联的BiMap,然后便可以通过get()方法获取key值了。
代码如下:
需要注意的是,BiMap作为一个双向的Map,它不能存储多对一的关系;而HashMap是可以的。其实很好理解,因为是双向的,所以即要满足Key值的唯一性,也要满足Value值的唯一性。如果往里存放同样的Value,会抛异常
以上是关于如何获得map的key值的主要内容,如果未能解决你的问题,请参考以下文章