sqoop实现关系型数据库与hadoop之间的数据传递-import篇
Posted 我的旧博客地址:
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sqoop实现关系型数据库与hadoop之间的数据传递-import篇相关的知识,希望对你有一定的参考价值。
由于业务数据量日益增长,计算量非常庞大,传统的数仓已经无法满足计算需求了,所以现在基本上都是将数据放到hadoop平台去实现逻辑计算,那么就涉及到如何将oracle数仓的数据迁移到hadoop平台的问题。
这里就不得不提到一个很实用的工具——sqoop,它是一款开源的工具,主要用于实现关系型数据库与hadoop中hdfs之间的数据传递,其中用的最多的就是import,export了。
sqoop的安装配置也是非常简单的,这里就不说明了,本文主要针对如何使用sqoop实现oracle到hive(hdfs)的数据传递进行试验。
对于比较全的参数使用,可以到sqoop的官方文档http://sqoop.apache.org/docs/ 查看,以下是这次会用到的一些参数讲解:
-m N :开启N个map来导入数据
--query : 从查询结果导入数据,注意,如果使用了该参数,那么必须指定--target-dir参数,并且查询条件中要包含$CONDITIONS
--target-dir :指定数据在HDFS中的存放目录
--hive-table :导入到hive的目标表名
--fetch-size :一次从数据库中读取的记录数
--hive-drop-import-delims :将数据导入到hive时,去掉其中的\\n,\\r,\\001等特殊字符
--null-string <null-string> :对于string类型的字段,如果值为null,那么使用<null-string>替代
--non-null-string <non-null-string> :对于非string类型的字段,如果值为null,那么使用<null-non-string>替代
(通常我们使用的是
--null-string \'\\\\N\' \\
--null-non-string ‘\\\\N’ \\
Hive中null默认是使用\\N来表示的,如果想要替换成\\N,那么还要多加一个\\来转义)
--hive-partition-key :hive表的分区字段
--hive-partition-value :指定导入到hive表的分区对应的分区值
--hive-overwrite :覆盖重写(这里注意,如果说没有使用到--hive-partition-key,hive-partition-value,那么--hive-overwrite的使用会将整个表的数据都覆盖,反之,则只是覆盖对应的 某个分区的数据)
--verbose :打印出详细的信息
================================================================================================
这里要注意,如果你要导入的数据里面包含\\n,\\r,\\001之类的特殊字符,那么要使用--hive-drop-import-delims去掉这些特殊字符,否则,如果字符串中有换行,那么换行符之后的数据将会被识别为另一行,导致结果不正确。
另一个需要注意的地方,如果导入的数据有些字段值是null的,要加上--null-string,--null-non-string参数,否则,这些null值将会被错误的替换为\'null\'这个字符串。
为了更好的说明这几个参数的重要性,下面来做一下试验:
平台说明:
Oracle Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
Hadoop hadoop-2.7.2
Hive hive-2.1.0
Sqoop sqoop-1.4.6
oracle中scott用户下的数据:
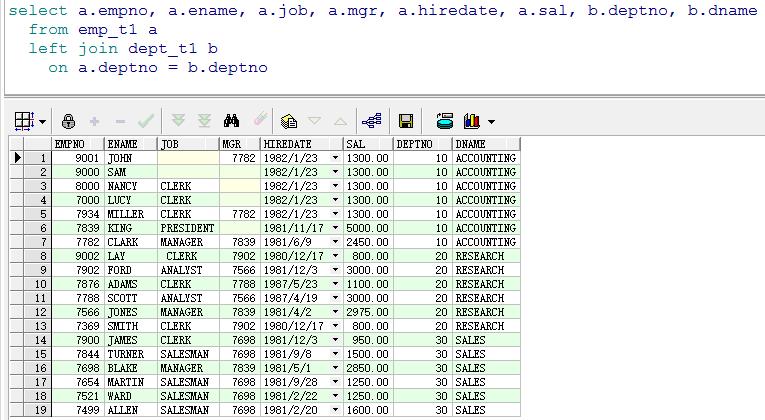
说明:empno为7000,8000,9000,9001的记录中,有的是JOB这个varchar2类型的值为null,有的是MGR这个number类型的值为null,而empno为9002的记录中,JOB为\\nClERK\\n(前后都有换行符)。
(1)不使用sqoop的相关参数进行处理:
1 sqoop import --query "select a.empno, 2 a.ename, 3 a.job, 4 a.mgr, 5 a.hiredate, 6 a.sal, 7 b.deptno, 8 b.dname 9 from emp_t1 a 10 left join dept_t1 b 11 on a.deptno = b.deptno 12 where /$CONDITIONS" \\ 13 --connect jdbc:oracle:thin:@192.168.134.200:1521/orclwin \\ 14 --username scott \\ 15 --password tiger \\ 16 -m 1 \\ 17 --hive-table test_db.emp_t1 \\ 18 --hive-overwrite \\ 19 --target-dir /sqoop/emp_t1 \\ 20 --hive-import
到hive中查看数据:
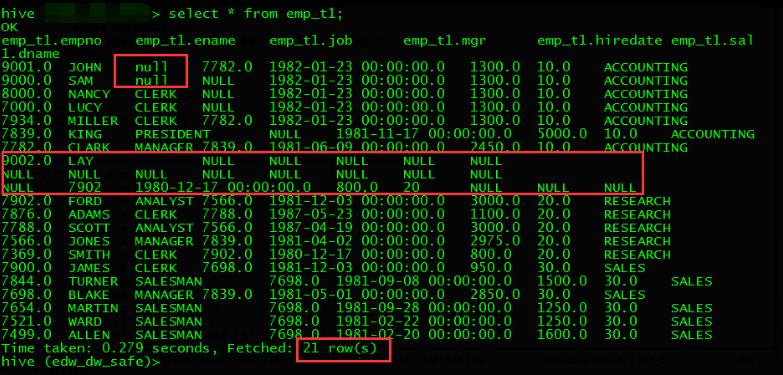
可见,原来的19条数据导入到hive中之后变成了21条,有两条是因为empno为9002没有正确处理其中的换行符导致的一条数据被分割成多条。
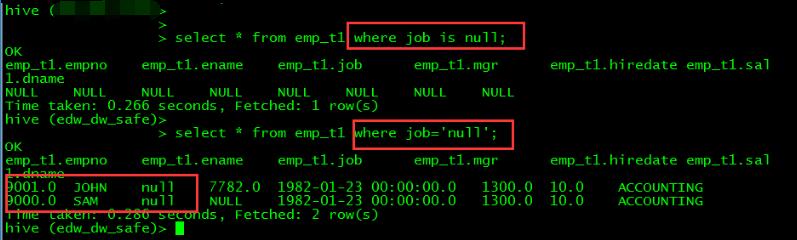
而9000和9001这两条数据的job字段值也不是NULL,而是\'null\'字符串:
(2)使用--hive-drop-import-delims参数处理导入数据的特殊符号,--null-string,--null-non-string处理导入数据字段值为空的情况
1 sqoop import --query "select a.empno, 2 a.ename, 3 a.job, 4 a.mgr, 5 a.hiredate, 6 a.sal, 7 b.deptno, 8 b.dname 9 from emp_t1 a 10 left join dept_t1 b 11 on a.deptno = b.deptno 12 where /$CONDITIONS" \\ 13 --connect \\ jdbc:oracle:thin:@192.168.134.200:1521/orclwin \\ 14 --username scott \\ 15 --password tiger \\ 16 -m 1 \\ 17 --hive-drop-import-delims \\ 18 --null-string \'\\\\N\' \\ 19 --null-non-string \'\\\\N\' \\ 20 --hive-table test_db.emp_t1 \\ 21 --hive-overwrite \\ 22 --target-dir /sqoop/emp_t1 \\ 23 --hive-import
到hive中查看数据:
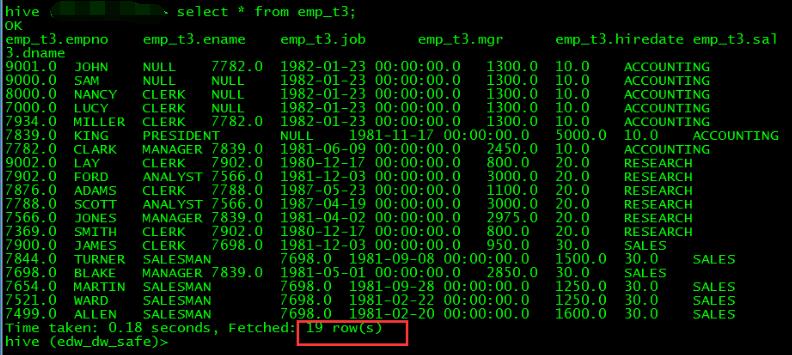
数据导入正常。
好啦,这个import的功能就说到这了,下一篇再说export
以上是关于sqoop实现关系型数据库与hadoop之间的数据传递-import篇的主要内容,如果未能解决你的问题,请参考以下文章