数据挖掘的步骤有哪些?
Posted 我想去吃ya
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘的步骤有哪些?相关的知识,希望对你有一定的参考价值。
所谓数据挖掘就是从海量的数据中,找到隐藏在数据里有价值的信息。因为这个数据是隐式的,因此想要挖掘出来并不简单。那么,如何进行数据挖掘呢?数据挖掘的步骤有哪些呢?一般来讲,数据挖掘需要经历数据收集、数据可视化、数据预处理、准备模型输入以及训练模型五大步骤,下面让我们来详细分析一下吧!
第一步:数据收集
通俗来讲,我们把数据挖掘可以看作是想要炒一盘可口的菜肴。那么,首先第一步就是去菜市场买菜。同样的,我们要从数据中找到需要的信息,第一步就是收集数据。
第二步:数据可视化
就好比你去买菜的时候,肯定要好好挑选一下,争取买到比较新鲜的蔬菜。同样的,数据挖掘的第二个步骤,就是再有了数据之后,还要看看拿来的数据长啥样。因此,我们可以利用各种可视化库来观察一下数据的内容,比如matplotlib或seaborn。
第三步:数据预处理
买完菜回到家我们要做的就是洗菜,把附着的泥土和残枝烂叶去掉,不然会影响我们的口感。通过上一步的可视化,我们可以发现数据里面有没有“残枝烂叶”,也就是我们说的异常值。异常值包括格式有问题的数据,例如年龄信息填的不是数字,或者信息根本就不符合逻辑,比如年龄填的200岁。
大家填过各种调查问卷吧?很多人在填写的时候,遇到那些不是必须填的地方一般都会空着不填。这就导致数据集里除了异常值,还有一个经常会遇到的就是缺失值。我们也会通过一些手段来弥补一下这些空缺。就好比我们把蔬菜清洗干净之后,还要选择一下是不是所有的菜我们都需要呢?想吃蔬菜的可以多放蔬菜,想吃肉的就多放些肉。所以我们还需要在数据里选择出来跟我们的任务相关的特征,这个过程叫做特征选择。
第四步:准备模型输入
我们此时案板上放着我们洗干净和挑选出来的蔬菜,下一步就是切菜了。毕竟炒土豆丝也没有把一整个土豆直接放锅里的。所以我们要对这些蔬菜,也就是数据,进行一个转化。这个过程我们运用到独热编码和分桶,分别是对离散型数据和连续型数据的处理方式。
第五步:训练模型
最后一步就是炒菜啦。我们的模型就是不同种类的锅,在数据挖掘中常见的模型翻来覆去就那么几个,比如决策树,逻辑回归,梯度提升树,k-means等。一般来讲,比较有代表性的两个模型是逻辑回归和决策树,可以预测“是否会幸存”。其他的模型只是内部原理不同,但使用方法都是一样的。大家在进行数据挖掘的时候,也可以选择若干模型,最后看看结果分别都怎么样,对比一下谁比较强。
以上就是数据挖掘比较详细的步骤分析。目前,市面上已经有很多的数据挖掘软件可以供我们使用,几乎不需要写任何代码,例如Orange、Weka等。大家也可以多试用一下那些软件~
大数据遍地开花
如何抓住学习机会?
从《2022年中国大数据产业发展指数报告》中,我们可以看到,现在大数据相关的产业已经在各个城市发展起来,产业规模也不断在扩大,相关行业对人才的需求量也在不断增加!
据《新职业——大数据工程技术人员就业景气现状分析报告》显示,预计2025年前大数据人才需求仍保持 30%-40% 的增速,行业人才需求量达到 250 万 。
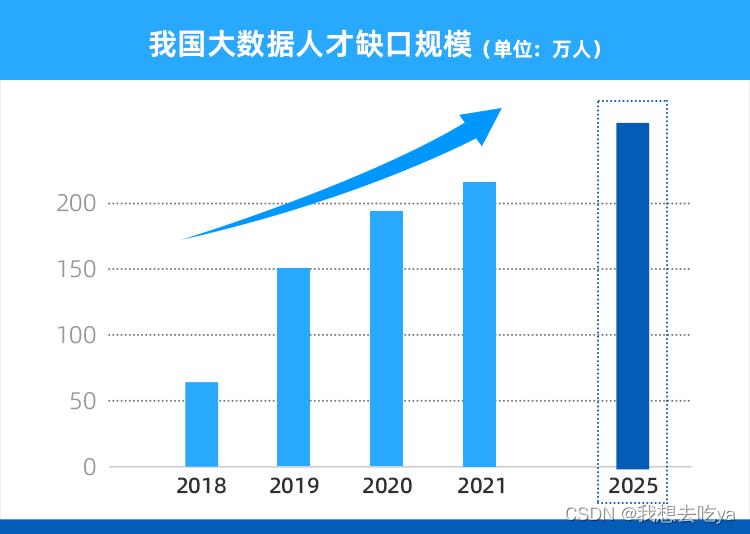
不仅招聘需求多,大数据开发人才在各大城市的就业薪资也非常可观。
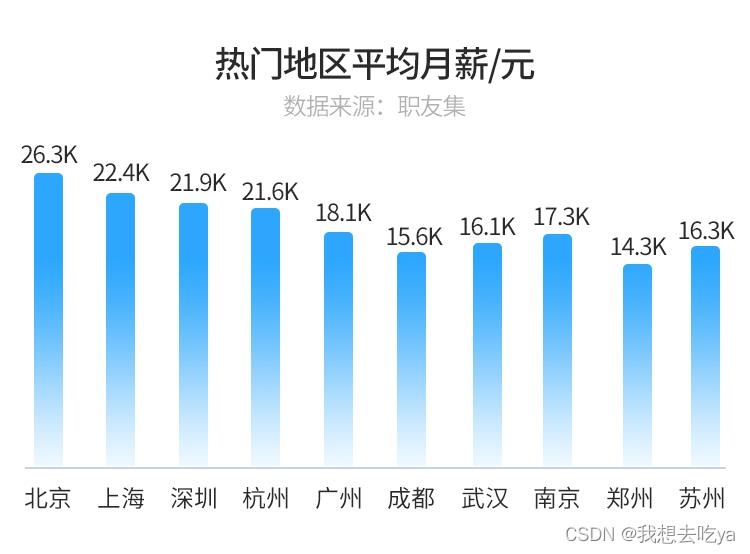
△数据来源职友集,如侵删
薪资高、缺口大,自然成为职场人的“薪”选择!
任何学习过程都需要一个科学合理的学习路线,才能够有条不紊的完成我们的学习目标。Python+大数据所需学习的内容纷繁复杂,难度较大,为大家整理了一个全面的Python+大数据学习路线图,帮大家理清思路,攻破难关!
Python+大数据学习路线图详细介绍(均为免费视频教程哈)
第一阶段 大数据开发入门
学前导读:从传统关系型数据库入手,掌握数据迁移工具、BI数据可视化工具、SQL,对后续学习打下坚实基础。
1.大数据数据开发基础MySQL8.0从入门到精通
mysql是整个IT基础课程,SQL贯穿整个IT人生,俗话说,SQL写的好,工作随便找。本课程从零到高阶全面讲解MySQL8.0,学习本课程之后可以具备基本开发所需的SQL水平。
2022最新MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程
第二阶段 大数据核心基础
学前导读:学习Linux、Hadoop、Hive,掌握大数据基础技术。
2022版大数据Hadoop入门教程
Hadoop离线是大数据生态圈的核心与基石,是整个大数据开发的入门,是为后期的Spark、Flink打下坚实基础的课程。掌握课程三部分内容:Linux、Hadoop、Hive,就可以独立的基于数据仓库实现离线数据分析的可视化报表开发。
2022最新大数据Hadoop入门视频教程,最适合零基础自学的大数据Hadoop教程
第三阶段 千亿级数仓技术
学前导读:本阶段课程以真实项目为驱动,学习离线数仓技术。
数据离线数据仓库,企业级在线教育项目实战(Hive数仓项目完整流程)
本课程会、建立集团数据仓库,统一集团数据中心,把分散的业务数据集中存储和处理 ;目从需求调研、设计、版本控制、研发、测试到落地上线,涵盖了项目的完整工序 ;掘分析海量用户行为数据,定制多维数据集合,形成数据集市,供各个场景主题使用。
大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(Hive数仓项目完整流程)
第四阶段 PB内存计算
学前导读:Spark官方已经在自己首页中将Python作为第一语言,在3.2版本的更新中,高亮提示内置捆绑Pandas;课程完全顺应技术社区和招聘岗位需求的趋势,全网首家加入Python on Spark的内容。
1.python入门到精通(19天全)
python基础学习课程,从搭建环境。判断语句,再到基础的数据类型,之后对函数进行学习掌握,熟悉文件操作,初步构建面向对象的编程思想,最后以一个案例带领同学进入python的编程殿堂。
全套Python教程_Python基础入门视频教程,零基础小白自学Python必备教程
2.python编程进阶从零到搭建网站
学完本课程会掌握Python高级语法、多任务编程以及网络编程。
Python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程
3.spark3.2从基础到精通
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。本课程基于Python语言学习Spark3.2开发,课程的讲解注重理论联系实际,高效快捷,深入浅出,让初学者也能快速掌握。让有经验的工程师也能有所收获。
Spark全套视频教程,大数据spark3.2从基础到精通,全网首套基于Python语言的spark教程
4.大数据Hive+Spark离线数仓工业项目实战
通过大数据技术架构,解决工业物联网制造行业的数据存储和分析、可视化、个性化推荐问题。一站制造项目主要基于Hive数仓分层来存储各个业务指标数据,基于sparkSQL做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料。
全网首次披露大数据Spark离线数仓工业项目实战,Hive+Spark构建企业级大数据平台
如果维度/事实表中的数据未正确加载,我需要执行哪些步骤来清理数据
【中文标题】如果维度/事实表中的数据未正确加载,我需要执行哪些步骤来清理数据【英文标题】:what are the steps I need to perform to clean the data if data into the dimension/fact table improperly loaded 【发布时间】:2020-11-07 14:18:29 【问题描述】:假设有一个场景,有一个数据加载到事实表\维表的过程,经过分析发现有1亿条记录不正确 加载后,我需要执行哪些步骤才能正确清理数据。
【问题讨论】:
你的问题太笼统,不了解细节无法回答。 【参考方案1】:这里有两种在这种情况下有帮助的做法:
在每批之前进行备份或快照。如果出现此类重大错误,您可以回滚到快照,重新加载并处理正确的数据。
在 DW 中维护一个仅插入的持久暂存区域,例如数据保险库,每行都标记有批次 ID 和时间戳。删除错误的行,并重建您的事实和维度。
如果这代表真实情况,您唯一的机会是 #1。
如果您没有可靠的备份,并且在 ETL/ELT 过程中更新和/或删除了行,则您没有任何失败前状态的记录,并且可能无法返回.
【讨论】:
以上是关于数据挖掘的步骤有哪些?的主要内容,如果未能解决你的问题,请参考以下文章