consumer(KafkaConsumer)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了consumer(KafkaConsumer)相关的知识,希望对你有一定的参考价值。
参考技术A (一)消费者和消费者组1、消费者:订阅并消费kafka消息,从属于消费者组
2、消费者组:一个群组里的消费者订阅的是同一个主题,每个消费者接受主题一部分分区的消息。
注:同一个消费者可以消费不同的partition,但是同一个partition不能被不同消费者消费。
(二)消费者群组和分区再均衡
1、再均衡:分区的消费所有权从一个消费者转移到另一个消费者称为再均衡,为消费者组带来了高可用性和可伸缩性。
注:分区何时重新分配:加入消费者或者消费者崩溃等
2、如何判断消费者崩溃:消费者通过向群组协调器(某broker,不同群组可以有不同的群组协调器)发送心跳(一般在拉取消息或者提交偏移量的时候)表示自己仍旧存活,如果长时间不发送心跳则协调器认为期死亡并进行再均衡。
注:在0.10.1版本中,心跳行为不再和获取消息和提交偏移量绑定在一起,有一个单独的心跳线程。
3、分配分区:消费者加入消费者组是,会像群组协调器发送请求,第一个加入的成为“群主”。群主从协调器那里获取成员列表,并负责给每一个消费者分配分区。完毕之后,将分配结果发送给协调器,协调器再将消息发送给所有的消费者,每个消费者只能看到自己的分配信息。只有群主知道所有的消费信息。
(三)参数配置
1、bootstrap.server:host:port
2、key.serializer:键序列化器
3、value.serializer:值序列化器
注:以上为必须设置的
4、group.id:从属的消费者组
5、fetch.min.bytes:消费者从服务器获取记录的最小字节数。
6、fetch.max.wait.ms:消费者等待消费消息的最大时间
7、max.partition.fetch.bytes:服务器从每个分区返回给消费者的最大字节数(需要比broker的设置max.message.size属性配置大,否则有些消息无法消费)
8、session.timeout.ms:指定该消费者在被认为死亡之前可以与服务器断开连接的时间,默认3秒
9、heartbeat.interval.ms:制定了poll方法向协调器发送心跳的频率。
注:一般9是8的三分之一
10、auto.offset.reset:消费者在读取一个没有偏移量分区或者无效偏移量分区的情况下如何处理(latest:从最新记录开始读取,earliest:从最早的记录开始读取)
11.、enable.auth.commit:消费者是否自动提交偏移量,默认为true
12、auto.commit.interval.ms:自动提交偏移量的时间间隔
13、partition.assignment.strategy:分区分配给消费者的策略:
(1)range:会把主题若干个连续分区分配给消费者
(2)roundRobin:会把主题的所有分区逐个分配给消费者
14、client.id:任意字符串,broker用来区分客户端发来的消息
15:max.poll.records:控制poll方法返回的最大记录数
16:receive.buffer.bytes/send.buffer.bytes:tcp缓冲池读写大小
(四)订阅主题
consumer.subscribe(list)
(五)轮训(消费者API的核心)
1、轮训作用: 只要消费者订阅了主题,轮训就会处理所有的细节(群组协调、分区再均衡、发送心跳、获取数据)
(1)获取数据
(2)第一次执行poll时,负责查找协调器,然后加入群组,接受分配的分区
(3)心跳的发送
(4)再均衡也是在轮训期间进行的
2、方法:poll(),消费者缓冲区没有数据时会发生阻塞,可以传一个阻塞时间,避免无限等待。0表示立即返回。
3、关闭:close(),网络连接随之关闭,立即触发再均衡。
4、线程安全:无法让一个线程运行多个消费者,也无法让多个线程公用一个消费者。
(六)提交和偏移量
1、提交:更新分区当前位置的操作
2、如何提交:消费者往一个特殊主题(_consumer_offset)发送消息,消息中包含每个分区中的偏移量。
3、偏移量:分区数据被消费的位置。
4、偏移量作用:当发生再均衡时,消费者可能会分配到不一样的分区,为了继续工作,消费者需要读取到每个分区最后一次提交的偏移量,然后从偏移量的地方继续处理。
5、提交偏移量的方式
(1)自动提交:经过一个时间间隔,提交上一次poll方法返回的偏移量。每次轮训都会检测是否应该提交偏移量。缺陷:可能导致重复消费
(2)手动提交:commitSysn()提交迁移量,最简单也最可靠,提交由poll方法返回的最新偏移量。缺点:忘了提交可能会丢数据,再均衡可能会重复消费
(3)异步提交:同步提交在提交过程中必须阻塞
(4)同步异步提交组合
(5)提交特定的偏移量
(七)再均衡监听器
(八)从特定偏移量读取数据(seek)
1、从分区开始:seekToBegining
2、从分区结束:seekToEnd
3、ConsumerRebalanceListener和seek结合使用
(九)如何退出
1、前言:wakeup方法是唯一安全退出轮训的方法,从poll方法中退出并抛出wakeupException异常。如果没有碰上轮训,则在下一次poll调用时抛出。
2、退出轮训
(1)另一个线程调用consumer.wakeup方法
(2)如果循环在主线程里可以在ShutdownHook里面调用该方法
3、退出之前调用close方法:告知协调器自己要离开,出发再均衡,不必等到超时。
(十)独立消费者(assign为自己分配分区)
聊聊 Kafka: Consumer 源码解析之 ConsumerNetworkClient
一、Consumer 的使用
Consumer 的源码解析主要来看 KafkaConsumer,KafkaConsumer 是 Consumer 接口的实现类。KafkaConsumer 提供了一套封装良好的 API,开发人员可以基于这套 API 轻松实现从 Kafka 服务端拉取消息的功能,这样开发人员根本不用关心与 Kafka 服务端之间网络连接的管理、心跳检测、请求超时重试等底层操作,也不必关心订阅 Topic 的分区数量、分区副本的网络拓扑以及 Consumer Group 的 Rebalance 等 Kafka 具体细节,KafkaConsumer 中还提供了自动提交 offset 的功能,使的开发人员更加关注业务逻辑,提高了开发效率。
下面我们来看一个 KafkaConsumer 的示例程序:
/**
* @author: 微信公众号【老周聊架构】
*/
public class KafkaConsumerTest
public static void main(String[] args)
Properties props = new Properties();
// kafka地址,列表格式为host1:port1,host2:port2,...,无需添加所有的集群地址,kafka会根据提供的地址发现其他的地址(建议多提供几个,以防提供的服务器关闭) 必须设置
props.put("bootstrap.servers", "localhost:9092");
// key序列化方式 必须设置
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化方式 必须设置
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("group.id", "consumer_riemann_test");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 可消费多个topic,组成一个list
String topic = "riemann_kafka_test";
consumer.subscribe(Arrays.asList(topic));
while (true)
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s \\n", record.offset(), record.key(), record.value());
try
Thread.sleep(100);
catch (InterruptedException e)
e.printStackTrace();
从示例中可以看出 KafkaConsumer 的核心方法是 poll(),它负责从 Kafka 服务端拉取消息。核心方法的具体细节我想放在下一篇再细讲,关乎消费侧的客户端与 Kafka 服务端的通信模型。这一篇我们主要从宏观的角度来剖析下 Consumer 消费端的源码。
二、KafkaConsumer 分析
我们先来看下 Consumer 接口,该接口定义了 KafkaConsumer 对外的 API,其核心方法可以分为以下六类:
- subscribe() 方法:订阅指定的 Topic,并为消费者自动分配分区。
- assign() 方法:用户手动订阅指定的 Topic,并且指定消费的分区,此方法 subscribe() 方法互斥。
- poll() 方法:负责从服务端获取消息。
- commit*() 方法:提交消费者已经消费完成的 offset。
- seek*() 方法:指定消费者起始消费的位置。
- pause()、resume() 方法:暂停、继续 Consumer,暂停后 poll() 方法会返回空。
我们先来看下 KafkaConsumer 的重要属性以及 UML 结构图。
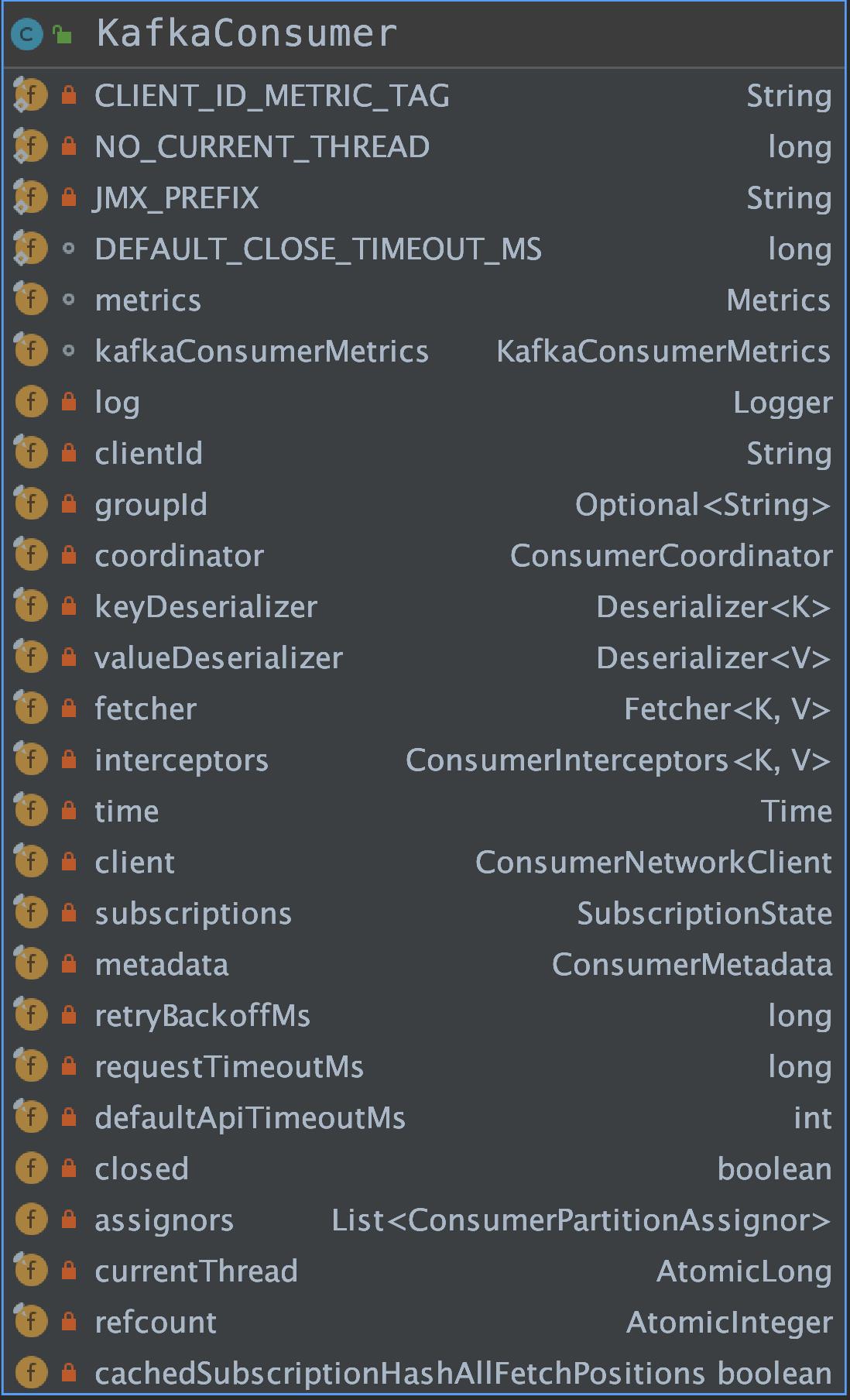
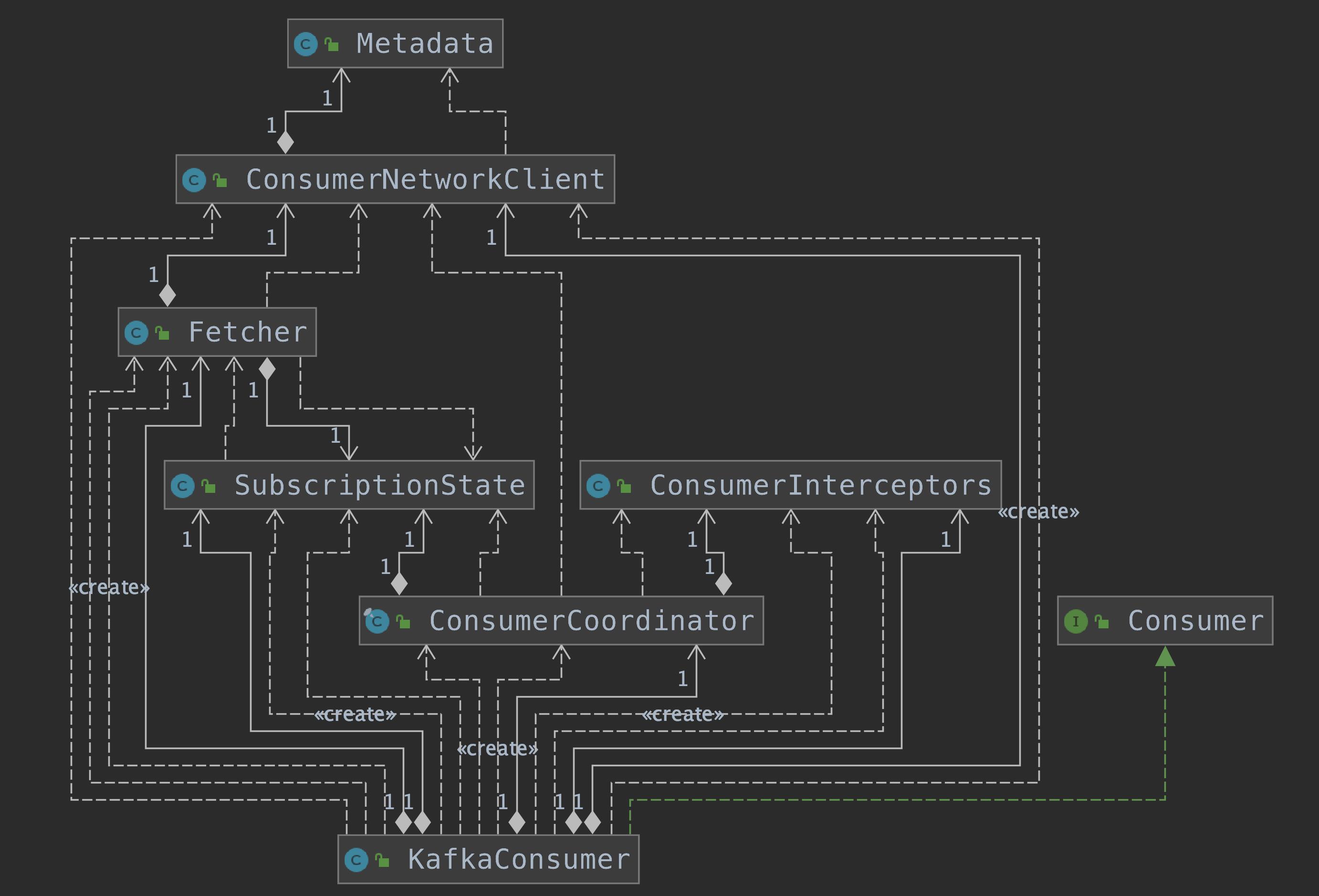
clientId:Consumer 的唯一标识。groupId:消费者组的唯一标识。coordinator:控制着 Consumer 与服务端 GroupCoordinator 之间的通信逻辑,读者可以理解为 Consumer 与服务端 GroupCoordinator 通信的门面。keyDeserializer、valueDeserializer:key 和 value 的反序列化器。fetcher:负责从服务端获取消息。interceptors:ConsumerInterceptors 集合,ConsumerInterceptors.onConsumer() 方法可以在消息通过 poll() 方法返回给用户之前对其进行拦截或修改;ConsumerInterceptors.onCommit() 方法也可以在服务端返回提交 offset 成功的响应进行拦截或修改。client:ConsumerNetworkClient 负责消费者与 Kafka 服务端的网络通信。subscriptions:SubscriptionState 维护了消费者的消费状态。metadata:ConsumerMetadata 记录了整个 Kafka 集群的元信息。currentThread、refcount:分别记录的 KafkaConsumer 的线程 id 和重入次数
三、ConsumerNetworkClient
ConsumerNetworkClient 在 NetworkClient 之上进行了封装,提供了更高级的功能和更易用的 API。
我们先来看下 ConsumerNetworkClient 的重要属性以及 UML 结构图。
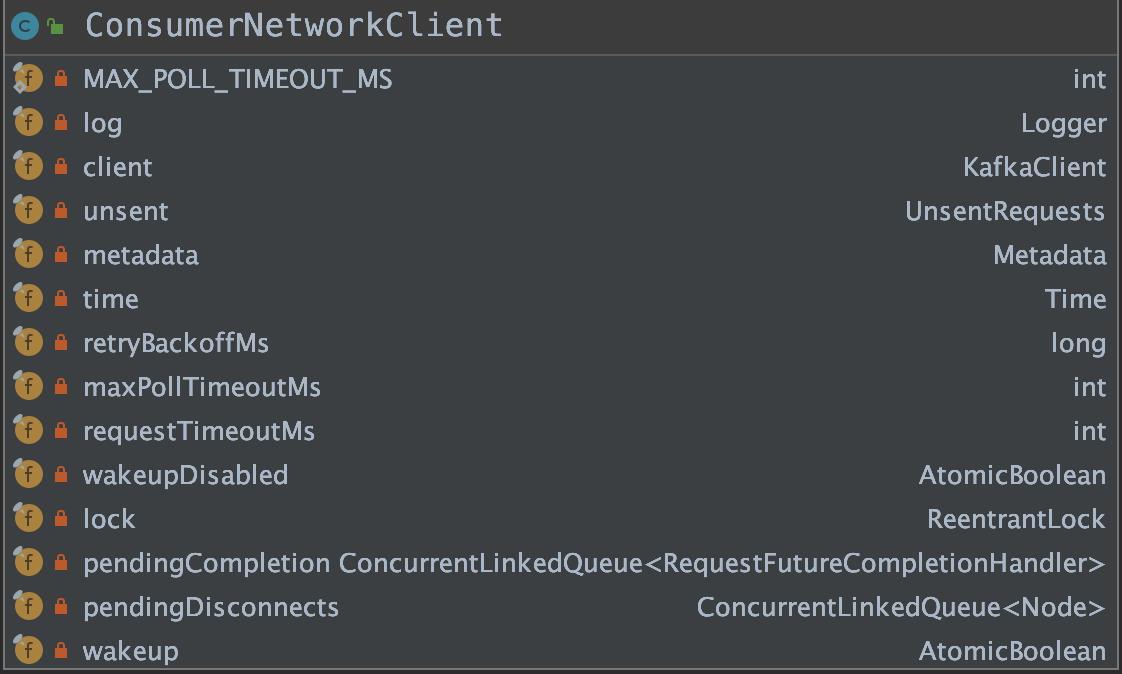

client:NetworkClient 对象。unsent:缓冲队列。UnsentRequests 对象,该对象内部维护了一个 unsent 属性,该属性是ConcurrentMap<Node, ConcurrentLinkedQueue<ClientRequest>>,key 是 Node 节点,value 是ConcurrentLinkedQueue<ClientRequest>。metadata:用于管理 Kafka 集群元数据。retryBackoffMs:在尝试重试对给定主题分区的失败请求之前等待的时间量,这避免了在某些故障情况下在紧密循环中重复发送请求。对应 retry.backoff.ms 配置,默认 100 ms。maxPollTimeoutMs:使用 Kafka 的组管理工具时,消费者协调器的心跳之间的预期时间。心跳用于确保消费者的会话保持活跃,并在新消费者加入或离开组时促进重新平衡。该值必须设置为低于 session.timeout.ms,但通常不应设置为高于该值的 1/3。它可以调整得更低,以控制正常重新平衡的预期时间。对应 heartbeat.interval.ms 配置,默认 3000 ms。构造函数中,maxPollTimeoutMs 取的是 maxPollTimeoutMs 与 MAX_POLL_TIMEOUT_MS 的最小值,MAX_POLL_TIMEOUT_MS 默认为 5000 ms。requestTimeoutMs:配置控制客户端等待请求响应的最长时间。如果在超时之前没有收到响应,客户端将在必要时重新发送请求,或者如果重试用尽,则请求失败。对应 request.timeout.ms 配置,默认 305000 ms。wakeupDisabled:由调用 KafkaConsumer 对象的消费者线程之外的其它线程设置,表示要中断 KafkaConsumer 线程。lock:我们不需要高吞吐量,所以使用公平锁来尽量避免饥饿。pendingCompletion:当请求完成时,它们在调用之前被转移到这个队列。目的是避免在持有此对象的监视器时调用它们,这可能会为死锁打开门。pendingDisconnects:断开与协调器连接节点的队列。wakeup:这个标志允许客户端被安全唤醒而无需等待上面的锁。为了同时启用它,避免需要获取上面的锁是原子的。
ConsumerNetworkClient 的核心方法是 poll() 方法,poll() 方法有很多重载方法,最终会调用 poll(Timer timer, PollCondition pollCondition, boolean disableWakeup) 方法,这三个参数含义是:timer 表示定时器限制此方法可以阻塞多长时间;pollCondition 表示可空阻塞条件;disableWakeup 表示如果 true 禁用触发唤醒。
我们来简单回顾下 ConsumerNetworkClient 的功能:
3.1 org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient#trySend
循环处理 unsent 中缓存的请求,对每个 Node 节点,循环遍历其 ClientRequest 链表,每次循环都调用 NetworkClient.ready() 方法检测消费者与此节点之间的连接,以及发送请求的条件。若符合条件,则调用 NetworkClient.send() 方法将请求放入 InFlightRequest 中等待响应,也放入 KafkaChannel 中的 send 字段等待发送,并将消息从列表中删除。代码如下:
long trySend(long now)
long pollDelayMs = maxPollTimeoutMs;
// send any requests that can be sent now
// 遍历 unsent 集合
for (Node node : unsent.nodes())
Iterator<ClientRequest> iterator = unsent.requestIterator(node);
if (iterator.hasNext())
pollDelayMs = Math.min(pollDelayMs, client.pollDelayMs(node, now));
while (iterator.hasNext())
ClientRequest request = iterator.next();
// 调用 NetworkClient.ready()检查是否可以发送请求
if (client.ready(node, now))
// 调用 NetworkClient.send()方法,等待发送请求。
client.send(request, now);
// 从 unsent 集合中删除此请求
iterator.remove();
else
// try next node when current node is not ready
break;
return pollDelayMs;
3.2 计算超时时间
如果没有请求在进行中,则阻塞时间不要超过重试退避时间。
3.3 org.apache.kafka.clients.NetworkClient#poll
- 判断是否需要更新 metadata 元数据
- 调用 Selector.poll() 进行 socket 相关的 IO 操作
- 处理完成后的操作(处理一系列 handle*() 方法处理请求响应、连接断开、超时等情况,并调用每个请求的回调函数)
3.4 调用 checkDisconnects() 方法检测连接状态
调用 checkDisconnects() 方法检测连接状态。检测消费者与每个 Node 之间的连接状态,当检测到连接断开的 Node 时,会将其在 unsent 集合中对应的全部 ClientRequest 对象清除掉,之后调用这些ClientRequest 的回调函数。
private void checkDisconnects(long now)
// any disconnects affecting requests that have already been transmitted will be handled
// by NetworkClient, so we just need to check whether connections for any of the unsent
// requests have been disconnected; if they have, then we complete the corresponding future
// and set the disconnect flag in the ClientResponse
for (Node node : unsent.nodes())
// 检测消费者与每个 Node 之间的连接状态
if (client.connectionFailed(node))
// Remove entry before invoking request callback to avoid callbacks handling
// coordinator failures traversing the unsent list again.
// 在调用请求回调之前删除条目以避免回调处理再次遍历未发送列表的协调器故障。
Collection<ClientRequest> requests = unsent.remove(node);
for (ClientRequest request : requests)
RequestFutureCompletionHandler handler = (RequestFutureCompletionHandler) request.callback();
AuthenticationException authenticationException = client.authenticationException(node);
// 调用 ClientRequest 的回调函数
handler.onComplete(new ClientResponse(request.makeHeader(request.requestBuilder().latestAllowedVersion()),
request.callback(), request.destination(), request.createdTimeMs(), now, true,
null, authenticationException, null));
3.5 org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient#maybeTriggerWakeup
检查 wakeupDisabled 和 wakeup,查看是否有其它线程中断。如果有中断请求,则抛出 WakeupException 异常,中断当前 ConsumerNetworkClient.poll() 方法。
public void maybeTriggerWakeup()
// 通过 wakeupDisabled 检测是否在执行不可中断的方法,通过 wakeup 检测是否有中断请求。
if (!wakeupDisabled.get() && wakeup.get())
log.debug("Raising WakeupException in response to user wakeup");
// 重置中断标志
wakeup.set(false);
throw new WakeupException();
3.6 再次调用 trySend() 方法
再次调用 trySend() 方法。在步骤 2.1.3 中调用了 NetworkClient.poll() 方法,在其中可能已经将 KafkaChannel.send 字段上的请求发送出去了,也可能已经新建了与某些 Node 的网络连接,所以这里再次尝试调用 trySend() 方法。
3.7 org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient#failExpiredRequests
处理 unsent 中超时请求。它会循环遍历整个 unsent 集合,检测每个 ClientRequest 是否超时,将过期请求加入到 expiredRequests 集合,并将其从 unsent 集合中删除。调用超时 ClientRequest 的回调函数 onFailure()。
private void failExpiredRequests(long now)
// clear all expired unsent requests and fail their corresponding futures
// 清除所有过期的未发送请求并使其相应的 futures 失败
Collection<ClientRequest> expiredRequests = unsent.removeExpiredRequests(now);
for (ClientRequest request : expiredRequests)
RequestFutureCompletionHandler handler = (RequestFutureCompletionHandler) request.callback();
// 调用回调函数
handler.onFailure(new TimeoutException("Failed to send request after " + request.requestTimeoutMs() + " ms."));
private Collection<ClientRequest> removeExpiredRequests(long now)
List<ClientRequest> expiredRequests = new ArrayList<>();
for (ConcurrentLinkedQueue<ClientRequest> requests : unsent.values())
Iterator<ClientRequest> requestIterator = requests.iterator();
while (requestIterator.hasNext())
ClientRequest request = requestIterator.next();
// 检查是否超时
long elapsedMs = Math.max(0, now - request.createdTimeMs());
if (elapsedMs > request.requestTimeoutMs())
// 将过期请求加入到 expiredRequests 集合
expiredRequests.add(request);
requestIterator.remove();
else
break;
return expiredRequests;
四、RequestFutureCompletionHandler
说 RequestFutureCompletionHandler 之前,我们先来看下 ConsumerNetworkClient.send() 方法。里面的逻辑会将待发送的请求封装成 ClientRequest,然后保存到 unsent 集合中等待发送,代码如下:
public RequestFuture<ClientResponse> send(Node node,
AbstractRequest.Builder<?> requestBuilder,
int requestTimeoutMs)
long now = time.milliseconds();
RequestFutureCompletionHandler completionHandler = new RequestFutureCompletionHandler();
ClientRequest clientRequest = client.newClientRequest(node.idString(), requestBuilder, now, true,
requestTimeoutMs, completionHandler);
// 创建 clientRequest 对象,并保存到 unsent 集合中。
unsent.put(node, clientRequest);
// wakeup the client in case it is blocking in poll so that we can send the queued request
// 唤醒客户端以防它在轮询中阻塞,以便我们可以发送排队的请求。
client.wakeup();
return completionHandler.future;
我们重点来关注一下 ConsumerNetworkClient 中使用的回调对象——RequestFutureCompletionHandler。其继承关系如下:
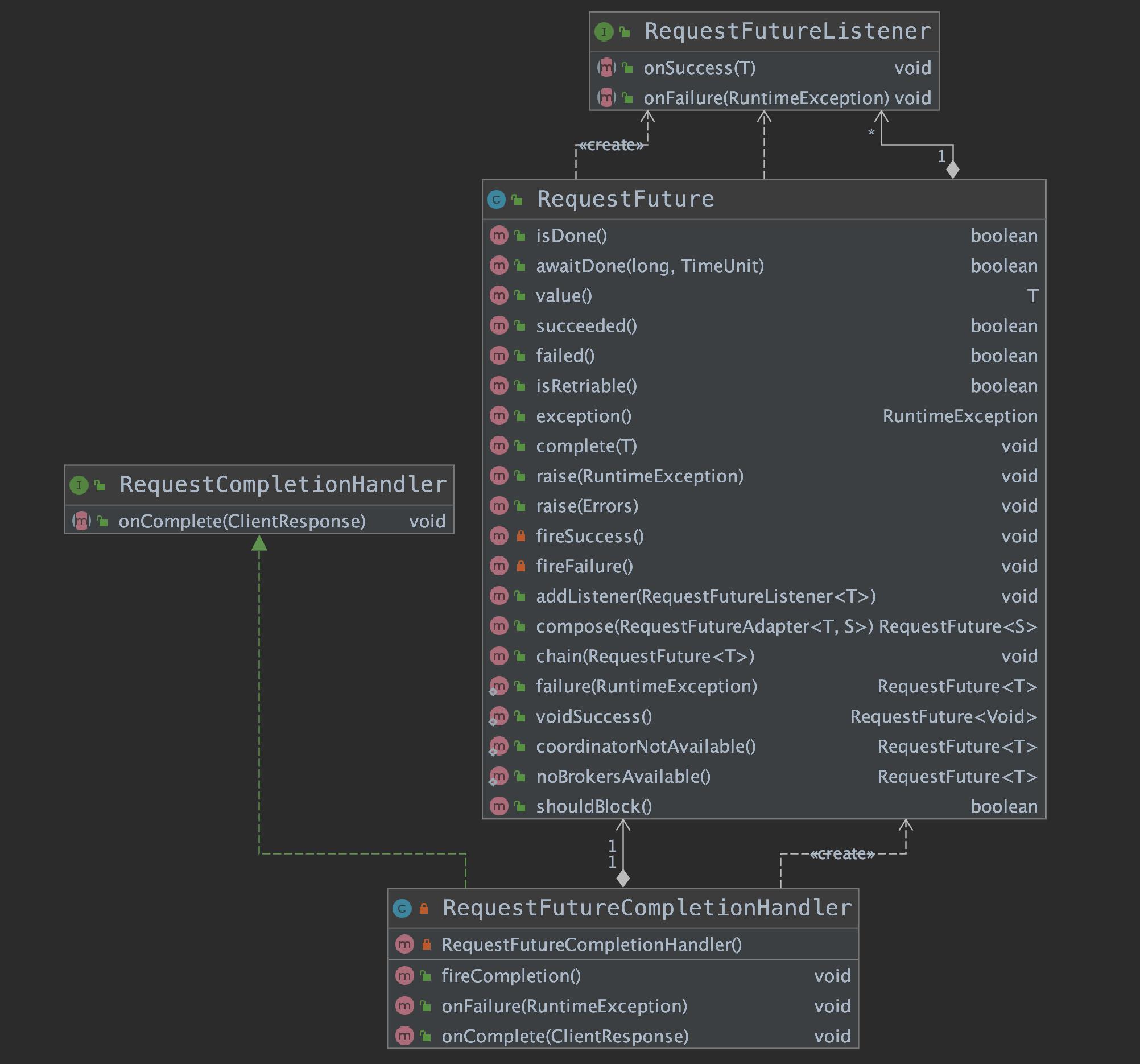
从 RequestFutureCompletionHandler 继承关系图我们可以知道,它不仅实现了 RequestCompletionHandler 接口,还组合了 RequestFuture 类,RequestFuture 是一个泛型类,其核心字段与方法如下:
listeners:RequestFutureListener 队列,用来监听请求完成的情况。RequestFutureListener 接口有 onSuccess() 和 onFailure () 两个方法,对应于请求正常完成和出现异常两种情况。isDone():表示当前请求是否已经完成,不管正常完成还是出现异常,此字段都会被设置为 true。value():记录请求正常完成时收到的响应,与 exception() 方法互斥。此字段非空表示正常完成,反之表示出现异常。exception():记录导致请求异常完成的异常类,与 value() 互斥。此字段非空则表示出现异常,反之则表示正常完成。
我们之所以要分析源码,是因为源码中有很多设计模式可以借鉴,应用到你自己的工作中。RequestFuture 中有两处典型的设计模式的使用,我们来看一下:
compose()方法:使用了适配器模式。chain()方法:使用了责任链模式。
4.1 RequestFuture.compose()
/**
* 适配器
* Adapt from a request future of one type to another.
*
* @param <F> Type to adapt from
* @param <T> Type to adapt to
*/
public abstract class RequestFutureAdapter<F, T>
public abstract void onSuccess(F value, RequestFuture<T> future);
public void onFailure(RuntimeException e, RequestFuture<T> future)
future.raise(e);
/**
* RequestFuture<T> 适配成 RequestFuture<S>
* Convert from a request future of one type to another type
* @param adapter The adapter which does the conversion
* @param <S> The type of the future adapted to
* @return The new future
*/
public <S> RequestFuture<S> compose(final RequestFutureAdapter<T, S> adapter)
// 适配之后的结果
final RequestFuture<S> adapted = new RequestFuture<>();
// 在当前 RequestFuture 上添加监听器
addListener(new RequestFutureListener<T>()
@Override
public void onSuccess(T value)
adapter.onSuccess(value, adapted);
@Override
public void onFailure(RuntimeException e)
adapter.onFailure(e, adapted);
);
return adapted;
使用 compose() 方法进行适配后,回调时的调用过程,也可以认为是请求完成的事件传播流程。当调用 RequestFuture<T> 对象的 complete() 或 raise() 方法时,会调用 RequestFutureListener<T> 的 onSuccess() 或 onFailure() 方法,然后调用 RequestFutureAdapter<T, S> 的对应方法,最终调用RequestFuture<S> 对象的对应方法。

4.2 RequestFuture.chain()
chain() 方法与 compose() 方法类似,也是通过 RequestFutureListener 在多个 RequestFuture 之间传递事件。代码如下:
public void chain(final RequestFuture<T> future)
// 添加监听器
addListener(new RequestFutureListener<T>()
@Override
public void onSuccess(T value)
// 通过监听器将 value 传递给下一个 RequestFuture 对象
future.complete(value);
@Override
public void onFailure(RuntimeException e)
// 通过监听器将异常传递给下一个 RequestFuture 对象
future.raise(e);
);
好了,ConsumerNetworkClient 的源码分析告一段落了,希望文章对你有帮助,我们下期再见。
以上是关于consumer(KafkaConsumer)的主要内容,如果未能解决你的问题,请参考以下文章
如何摆脱 NoSuchMethodError:Spark Streaming + Kafka 中的 org.apache.kafka.clients.consumer.KafkaConsumer.su
聊聊 Kafka: Consumer 源码解析之 ConsumerNetworkClient
聊聊 Kafka: Consumer 源码解析之 ConsumerNetworkClient
学习笔记Kafka—— Kafka Consumer API及开发实例