大数据系列hadoop上传文件报错_COPYING_ could only be replicated to 0 nodes
Posted 霓裳梦竹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据系列hadoop上传文件报错_COPYING_ could only be replicated to 0 nodes相关的知识,希望对你有一定的参考价值。
使用hadoop上传文件 hdfs dfs -put XXX
17/12/08 17:00:39 WARN hdfs.DFSClient: DataStreamer Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/sanglp/hadoop-2.7.4.tar.gz._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1628)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getNewBlockTargets(FSNamesystem.java:3121)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3045)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:725)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB .java:493)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtoco lProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2217)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2213)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1746)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2213)
at org.apache.hadoop.ipc.Client.call(Client.java:1476)
at org.apache.hadoop.ipc.Client.call(Client.java:1413)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy10.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:418)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy11.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:1588)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1373)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:554)
put: File /user/sanglp/hadoop-2.7.4.tar.gz._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode( s) running and no node(s) are excluded in this operation.
查看hadoop是否正常,进程是否完整
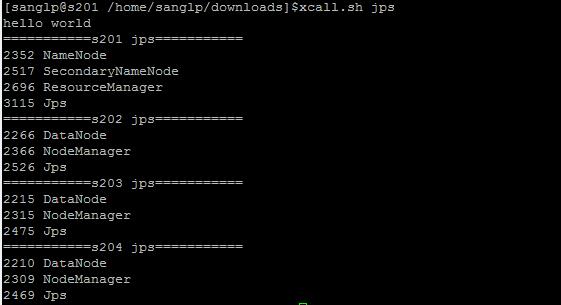
查看磁盘使用情况
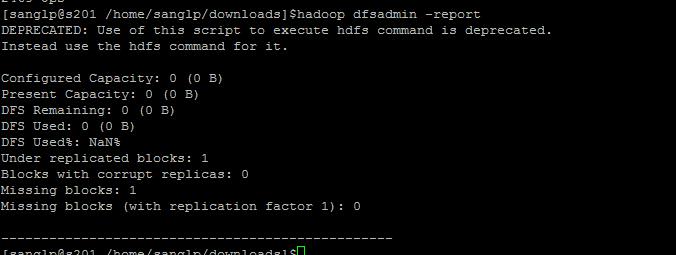
从这里可以看出操盘的空间都是空的
原因可能是hadoop格式化的时候出现了问题
然后将logs和tmp中的文件全部删除,重新格式化也没成功,后来看到clusterId不一致的问题
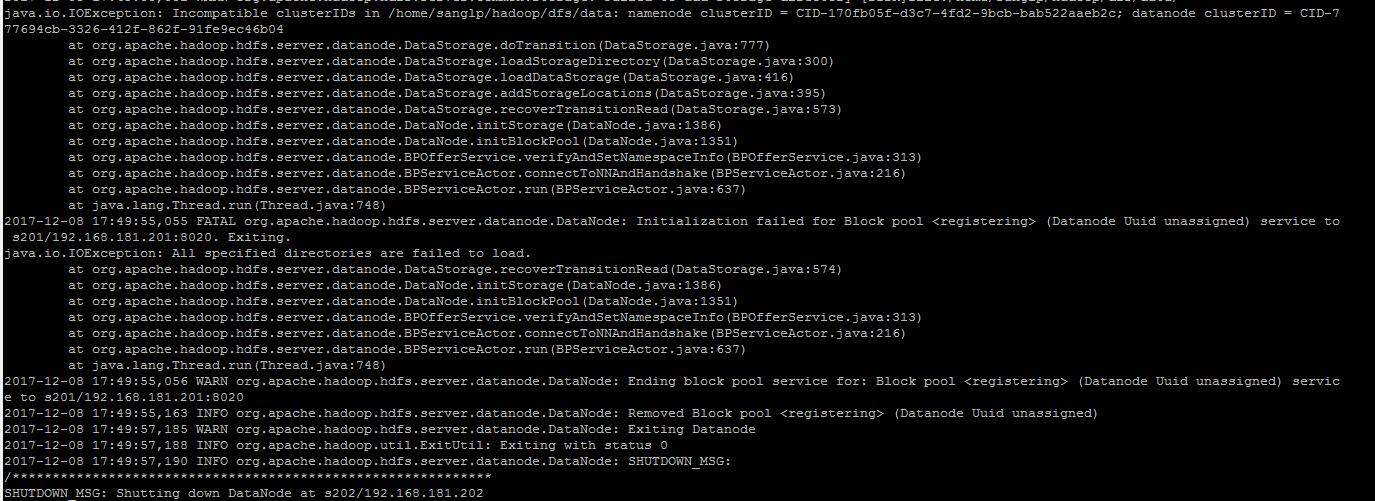
修改了VERSION文件中的clusterId随着又出现了 is in an inconsistent state的问题,
在hadoop-hdfs.xml中增加了
<property> <name>dfs.name.dir</name> <value>/soft/hadoop/name</value> #hadoop的name目录路径 </property> <property> <name>dfs.data.dir</name> <value>/soft/hadoop/data</value> #hadoop的data目录路径 </property>
重新格式化然后启动就可以了。
陆陆续续折腾了一上午、、、
以上是关于大数据系列hadoop上传文件报错_COPYING_ could only be replicated to 0 nodes的主要内容,如果未能解决你的问题,请参考以下文章