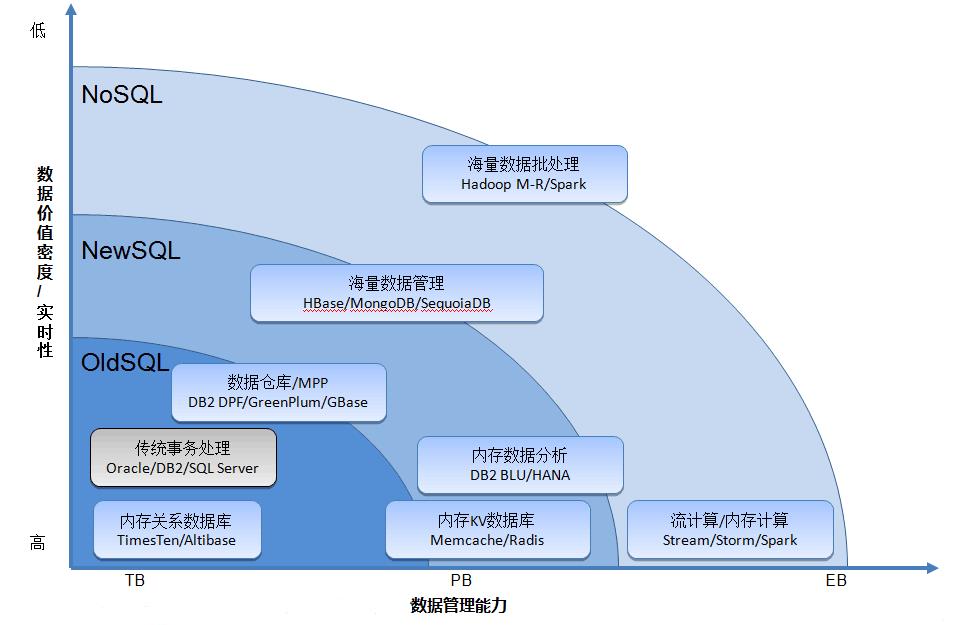
从NoSQL到NewSQL数据库
OldSql:传统关系型数据库
NewSql:也是关系型数据库,吸收了传统关系型数据库和NoSql数据库的优点。可实现强一致性(传统关系型DB优点),具有强的水平可扩展性(NoSql DB优点)
NoSql:面向互联网应用,如web2.0,半结构化,非结构化数据的存储
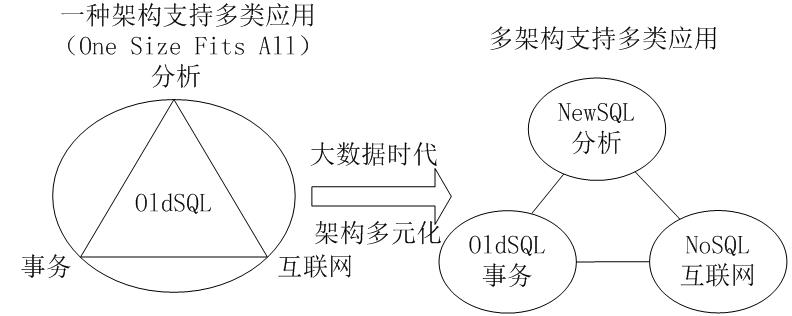
图5-6 大数据引发数据处理架构变革
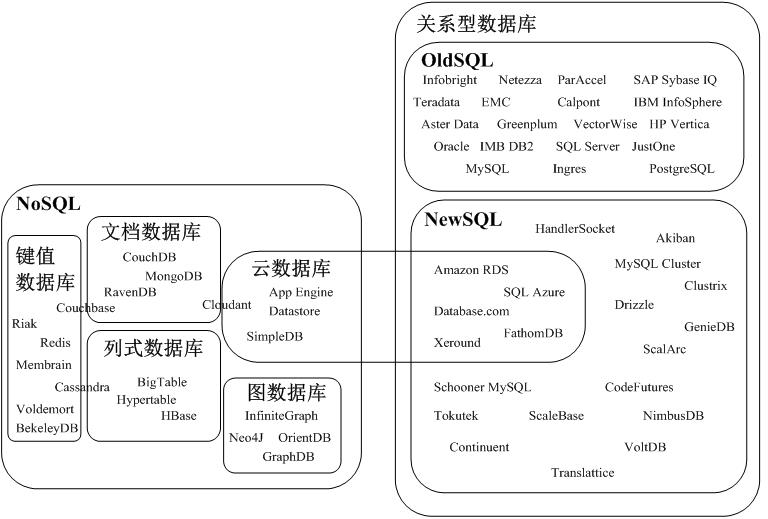
图5-7 关系数据库、NoSQL和NewSQL数据库产品分类图
SQL
SQL是关系型数据库管理系统(RDBMS),顾名思义,它是围绕关系代数和元组关系演算构建的。 70年代以来,它一直是主要的数据库解决方案,只是最近才有了其他产品的空间。 不管有些人说什么,这意味着它一直能出色地执行广泛的任务。 其主要优点如下:
- 不同的角色(开发者,用户,数据库管理员)使用相同的语言。
- 不同的RDBMS使用统一标准的语言。
- SQL使用一种高级的非结构化查询语言。.
- 它坚持 ACID 准则 (原子性,一致性,隔离性,持久性),,这些准则保证了数据库尤其是每个事务的稳定性,安全性和可预测性。
如你所见,许多SQL的好处来源于它的统一性,舒适性和易用性。 即使你只有非常有限的SQL知识(或完全没有,如果需要),你可以在像 online SQL Query Builder 这样的特殊工具帮助下使用它。
然而,它的缺点使得它非常不适合某些类型的项目。 SQL的主要问题是它难以扩展,因为它的性能随着数据库的变大而快速下降。 分布式也是有问题的。
NoSQL和NewSQL出现的原因之一是,以前的RDBMS的设计不能满足现代数据库每秒处理的事务数量。 像亚马逊或阿里巴巴等需要处理惊人数据量的巨头,以前的RDBMS会在几分钟内出现问题。
NoSQL (Not Only SQL)
NoSQL越来越受欢迎,其中最重要的实现是Apache Cassandra,MongoDB等产品。 它主要用于解决SQL的可扩展性问题。 因此,它是没有架构的并且建立在分布式系统上,这使得它易于扩展和分片。
然而,这些好处是以放宽ACID原则为代价的:NoSQL采取最终一致性原则,而不是所有四个参数在每个事务中保持一致。 这意味着如果在特定时间段内没有特定数据项的更新,则最终对其所有的访问都将返回最后更新的值。 这就是这样的系统通常被描述为提供基本保证的原因(基本可用,软状态,最终一致性) — 而不是ACID。
虽然这个方案极大地增加了可用时间和伸缩性,它也会导致数据丢失----这个问题的严重程度取决于数据库服务器的支持情况和应用代码质量.在某些情况下,这个问题十分严重.
另一个NoSQL出现的问题是现在有很多类型的NoSQL系统,但它们之间却几乎没有一致性.诸如灵活性,性能,复杂性,伸缩性等等特性在不同系统间差别巨大,这使得甚至是专家在他们之间都很难选择.不过,当你根据项目特点作出了合适的选择,NoSQL可以在不显著丢失稳定性的情况下提供一个远比SQL系统更高效的解决方案.
NewSQL
NewSQL是一种相对较新的形式,旨在使用现有的编程语言和以前不可用的技术来结合SQL和NoSQL中最好的部分。 NewSQL目标是将SQL的ACID保证与NoSQL的可扩展性和高性能相结合。
显然,因为结合了过去仅单独存在的优点,NewSQL看起来很有前途; 或许,在未来的某个时候,它将成为大多数人使用的标准。 不幸的是,目前大多数NewSQL数据库都是专有软件或仅适用于特定场景,这显然限制了新技术的普及和应用。
除此之外,NewSQL在每个方面比较均匀,每个解决方案都有自己的缺点和优势。 例如,SAP HANA可以轻松处理低到中等的事务性工作负载,但不使用本机集群,MemSQL对于集群分析很有用,但在ACID事务上表现出较差的一致性,等等。 因此,在这些解决方案变得真正普及之前,可能还需要一段时间。