怎么排查这些内存泄漏
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎么排查这些内存泄漏相关的知识,希望对你有一定的参考价值。
最原始的内存泄露测试重复多次操作关键的可疑的路径,从内存监控工具中观察内存曲线,是否存在不断上升的趋势且不会在程序返回时明显回落。
这种方式可以发现最基本,也是最明显的内存泄露问题,对用户价值最大,操作难度小,性价比极高。
MAT内存分析工具
2.1 MAT分析heap的总内存占用大小来初步判断是否存在泄露
在Devices 中,点击要监控的程序。
点击Devices视图界面中最上方一排图标中的“Update Heap”
点击Heap视图
点击Heap视图中的“Cause GC”按钮
到此为止需检测的进程就可以被监视。Heap视图中部有一个Type叫做data object,即数据对象,也就是我们的程序中大量存在的类类型的对象。在data object一行中有一列是“Total Size”,其值就是当前进程中所有Java数据对象的内存总量,一般情况下,这个值的大小决定了是否会有内存泄漏。可以这样判断:
进入某应用,不断的操作该应用,同时注意观察data object的Total Size值,正常情况下Total Size值都会稳定在一个有限的范围内,也就是说由于程序中的的代码良好,没有造成对象不被垃圾回收的情况。
所以说虽然我们不断的操作会不断的生成很多对象,而在虚拟机不断的进行GC的过程中,这些对象都被回收了,内存占用量会会落到一个稳定的水平;反之如果代码中存在没有释放对象引用的情况,则data object的Total Size值在每次GC后不会有明显的回落。随着操作次数的增多Total Size的值会越来越大,直到到达一个上限后导致进程被杀掉。
2.2 MAT分析hprof来定位内存泄露的原因所在。
这是出现内存泄露后使用MAT进行问题定位的有效手段。
A)Dump出内存泄露当时的内存镜像hprof,分析怀疑泄露的类:
B)分析持有此类对象引用的外部对象
C)分析这些持有引用的对象的GC路径
D)逐个分析每个对象的GC路径是否正常
从这个路径可以看出是一个antiRadiationUtil工具类对象持有了MainActivity的引用导致MainActivity无法释放。此时就要进入代码分析此时antiRadiationUtil的引用持有是否合理(如果antiRadiationUtil持有了MainActivity的context导致节目退出后MainActivity无法销毁,那一般都属于内存泄露了)。
2.3 MAT对比操作前后的hprof来定位内存泄露的根因所在。
为查找内存泄漏,通常需要两个 Dump结果作对比,打开 Navigator History面板,将两个表的 Histogram结果都添加到 Compare Basket中去
A) 第一个HPROF 文件(usingFile > Open Heap Dump ).
B)打开Histogram view.
C)在NavigationHistory view里 (如果看不到就从Window >show view>MAT- Navigation History ), 右击histogram然后选择Add to Compare Basket .
D)打开第二个HPROF 文件然后重做步骤2和3.
E)切换到Compare Basket view, 然后点击Compare the Results (视图右上角的红色”!”图标)。
F)分析对比结果
可以看出两个hprof的数据对象对比结果。
通过这种方式可以快速定位到操作前后所持有的对象增量,从而进一步定位出当前操作导致内存泄露的具体原因是泄露了什么数据对象。
注意:
如果是用 MAT Eclipse 插件获取的 Dump文件,不需要经过转换则可在MAT中打开,Adt会自动进行转换。
而手机SDk Dump 出的文件要经过转换才能被 MAT识别,android SDK提供了这个工具 hprof-conv (位于 sdk/tools下)
首先,要通过控制台进入到你的 android sdk tools 目录下执行以下命令:
./hprof-conv xxx-a.hprof xxx-b.hprof
例如 hprof-conv input.hprof out.hprof
此时才能将out.hprof放在eclipse的MAT中打开。
手机管家内存泄露每日监控方案
目前手机管家的内存泄露每日监控会自动运行并输出是否存在疑似泄露的报告邮件,不论泄露对象的大小。这其中涉及的核心技术主要是AspectJ,MLD自研工具(原理是虚引用)和UIAutomator。
3.1 AspectJ插桩监控代码
手机管家目前使用一个ant脚本加入MLD的监控代码,并通过AspectJ的语法实现插桩。
使用AspectJ的原因是可以灵活分离出项目源码与监控代码,通过不同的编译脚本打包出不同用途的安装测试包:如果测试包是经过Aspect插桩了MLD监控代码的话,那么运行完毕后会输出指定格式的日志文件,作为后续分析工作的数据基础。
3.2 MLD实现监控核心逻辑
这是手机管家内的一个工具工程,正式打包不会打入,BVT等每日监控测试包可以打入。打入后可以通过诸如addObject接口(通过反射去检查是否含有该工具并调用)来加入需要监控的检测对象,这个工具会自动在指定时机(如退出管家)去检测该对象是否发生泄漏。
这个内存泄露检测的基本原理是:
虚引用主要用来跟踪对象被垃圾回收器回收的活动。虚引用必须和引用队列(ReferenceQueue)联合使用(在虚引用函数就必须关联指定)。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,自动把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。
基于以上原理,MLD工具在调用接口addObject加入监控类型时,会为该类型对象增加一个虚引用,注意虚引用并不会影响该对象被正常回收。因此可以在ReferenceQueue引用队列中统计未被回收的监控对象是否超过指定阀值。
利用PhantomReferences(虚引用)和ReferenceQueue(引用队列),当PhantomReferences被加入到相关联的ReferenceQueue时,则视该对象已经或处于垃圾回收器回收阶段了。
MLD监控原理核心
目前手机管家已对大部分类完成内存泄露的监控,包括各种activity,service和view页面等,务求在技术上能带给用户最顺滑的产品体验。
接下来简单介绍下这个工具的判断核心。根据虚引用监控到的内存状态,需要通过多种策略来判断是否存在内存泄露。
(1)最简单的方式就是直接在加入监控时就为该类型设定最大存在个数,举个例子,各个DAO对象理论上只能存在最多一个,因此一旦出现两个相同的DAO,那一般都是泄露了;
(2)第二种情况是在页面退出程序退出时,检索gc后无法释放的对象列表,这些对象类型也会成为内存泄露的怀疑对象;
(3)最后一种情况比较复杂,基本原理是根据历史操作判断对象数量的增长幅度。根据对象的增长通过最小二乘法拟合出该对象类型的增长速度,如果超过经验值则会列入疑似泄露的对象列表。
3.3 UIAutomator完成重复操作的自动化
最后一步就很简单了。这么多反复的UI操作,让人工来点就太浪费人力了。我们使用UIAutomator来进行自动化操作测试。
目前手机管家的每日自动化测试已覆盖各个功能的主路径,并通过配置文件的方式来灵活驱动用例的增删改查,最大限度保证了随着版本推移用例的复用价值。
至此手机管家的内存泄露测试方案介绍完毕,也欢迎各路牛人交流沟通更多更强的内存泄露工具盒方案!
腾讯Bugly简介
Bugly是腾讯内部产品质量监控平台的外发版本,其主要功能是App发布以后,对用户侧发生的Crash以及卡顿现象进行监控并上报,让开发同学可以第一时间了解到App的质量情况,及时机型修改。目前腾讯内部所有的产品,均在使用其进行线上产品的崩溃监控。 参考技术A (1) 操作Bitmap对象,一定要注意,在不使用的时候 recycle
(2) 访问数据库,一定要记得关闭游标
(3) 涉及JNI层的代码,由于JNI层是采用C/C++编写,需要自己管理内存的分配/回收,所以要慎重小心。
那么,Android开发中,有什么有效的方法可以检测内存使用情况以及内存泄漏呢看
这里主要介绍三种方法:
1. 程序的Log信息
程序在进行垃圾回收的时候,会打印一条Log信息(logcat窗口),例如:
D/dalvikvm( 9050): GC_CONCURRENT freed 2049K, 65% free 3571K/9991K, external 4703K/5261K, paused 2ms+2ms
注意这条信息中的 逗 3571K/9991K地 值,这代表着程序使用的heap大小,如果这个值一直在增加,而从来不减小,那么就代表着你的程序存在着内存泄漏。
2. DDMS的Heap信息
Eclipse开发环境还提供了一种更加直观的方法来查看App的Heap信息,操作方式如下:
(1) 连接手机,运行程序,假设是 com.ticktick.test 程序
(2) 点击DDMS按钮,在左侧的Device窗口选中你要检测的程序(com.ticktick.test )
(3) 点击Device窗口工具栏的第二个图标(Update Heap),
(4) 点击右边的窗口的Cause GC按钮,即可得到当前程序的Heap信息
同样,随着程序的运行,多次点击得到的Heap大小,如果只增不减的话,也昭示着你的程序有内存泄漏。
3. adb命令查看内存信息
其实,最全面最简单的方式还是用adb命令来查看程序的内存占用和内存泄漏情况,打开命令行窗口,adb命令的格式如下:
adb shell dumpsys meminfo <package_name>
其中,package_name 也可以换成程序的pid,pid可以通过 adb shell top | grep app_name 来查找,在命令行窗口运行上述命令,得到的我的 com.ticktick.test 程序的内存情况如下所示:
这里得到的信息非常多,重点关注如下几个字段:
(1) Native/Dalvik 的 Heap 信息
具体在上面的第一行和第二行,它分别给出的是JNI层和Java层的内存分配情况,如果发现这个值一直增长,则代表程序可能出现了内存泄漏。
(2) Total 的 PSS 信息
这个值就是你的应用真正占据的内存大小,通过这个信息,你可以轻松判别手机中哪些程序占内存比较大了。
4. 总结
关于Android开发中内存的使用情况和内存泄漏的检测就简单介绍到这里,基本上用以上三种方式都能够定位内存泄漏问题,平时在使用Bitmap,数据库和JNI层C/C++编程的时候,注意一点就行。另外,如果想深入了解文中的一些详细内容,可以参考Google官方提供的两篇文章,它们有着更详细的论述《Investigating Your RAM Usage》,《Managing Your App Memory》,有任何疑问或者不清楚的地方,欢迎留言或者来信lujun.hust@gmail.com交流。
Java 内存泄漏了,怎么排查?
点击关注公众号,Java干货及时送达
来源:zhenbianshu.github.io/
晚上七点多开始,我就开始不停地收到报警邮件,邮件显示探测的几个接口有超时情况。多数执行栈都在:
java.io.BufferedReader.readLine(BufferedReader.java:371)
java.io.BufferedReader.readLine(BufferReader.java:389)
java_io_BufferedReader$readLine.call(Unknown Source)
com.domain.detect.http.HttpClient.getResponse(HttpClient.groovy:122)
com.domain.detect.http.HttpClient.this$2$getResponse(HttpClient.groovy)根据这个猜想,群登上服务器,使用请求的 request_id 在近期服务日志中搜索一下,果不其然,就是网络丢包问题导致的接口超时了。
问题爆发
本以为这次值班就起这么一个小波浪,结果在晚上八点多,各种接口的报警邮件蜂拥而至,打得准备收拾东西过周日单休的我措手不及。
这次几乎所有的接口都在超时,而我们那个大量网络 I/O 的接口则是每次探测必超时,难道是整个机房故障了么。
我再次通过服务器和监控看到各个接口的指标都很正常,自己测试了下接口也完全 OK,既然不影响线上服务,我准备先通过探测服务的接口把探测任务停掉再慢慢排查。
结果给暂停探测任务的接口发请求好久也没有响应,这时候我才知道没这么简单。另外,如果你近期准备面试跳槽,建议在Java面试库小程序在线刷题,涵盖 2000+ 道 Java 面试题,几乎覆盖了所有主流技术面试题。
解决
内存泄漏
于是赶快登陆探测服务器,首先是 top free df 三连,结果还真发现了些异常。

我们的探测进程 CPU 占用率特别高,达到了 900%。另外,JVM 系列面试题和答案全部整理好了,微信搜索Java技术栈,在后台发送:面试,可以在线阅读。
我们的 Java 进程,并不做大量 CPU 运算,正常情况下,CPU 应该在 100~200% 之间,出现这种 CPU 飙升的情况,要么走到了死循环,要么就是在做大量的 GC。
使用 jstat -gc pid [interval] 命令查看了 java 进程的 GC 状态,果然,FULL GC 达到了每秒一次。
最新 Java 教程和示例代码:https://github.com/javastacks/javastack

这么多的 FULL GC,应该是内存泄漏没跑了,于是 使用 jstack pid > jstack.log 保存了线程栈的现场,使用 jmap -dump:format=b,file=heap.log pid 保存了堆现场,然后重启了探测服务,报警邮件终于停止了。
jstat
jstat 是一个非常强大的 JVM 监控工具,一般用法是:jstat [-options] pid interval
它支持的查看项有:
-class 查看类加载信息
-compile 编译统计信息
-gc 垃圾回收信息
-gcXXX 各区域 GC 的详细信息 如 -gcold
使用它,对定位 JVM 的内存问题很有帮助。
排查
问题虽然解决了,但为了防止它再次发生,还是要把根源揪出来。点击关注公众号,Java干货及时送达
分析栈
栈的分析很简单,看一下线程数是不是过多,多数栈都在干嘛。
> grep 'java.lang.Thread.State' jstack.log | wc -l
> 464才四百多线程,并无异常。
> grep -A 1 'java.lang.Thread.State' jstack.log | grep -v 'java.lang.Thread.State' | sort | uniq -c |sort -n
10 at java.lang.Class.forName0(Native Method)
10 at java.lang.Object.wait(Native Method)
16 at java.lang.ClassLoader.loadClass(ClassLoader.java:404)
44 at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
344 at sun.misc.Unsafe.park(Native Method)线程状态好像也无异常,接下来分析堆文件。46 张 PPT 弄懂 JVM 性能调优分享给你学习下。
下载堆 dump 文件
堆文件都是一些二进制数据,在命令行查看非常麻烦,Java 为我们提供的工具都是可视化的,Linux 服务器上又没法查看,那么首先要把文件下载到本地。
由于我们设置的堆内存为 4G,所以 dump 出来的堆文件也很大,下载它确实非常费事,不过我们可以先对它进行一次压缩。
gzip 是个功能很强大的压缩命令,特别是我们可以设置 -1 ~ -9 来指定它的压缩级别,数据越大压缩比率越大,耗时也就越长,推荐使用 -6~7, -9 实在是太慢了,且收益不大,有这个压缩的时间,多出来的文件也下载好了。
使用 MAT 分析 jvm heap
MAT 是分析 Java 堆内存的利器,使用它打开我们的堆文件(将文件后缀改为 .hprof), 它会提示我们要分析的种类,对于这次分析,果断选择 memory leak suspect。
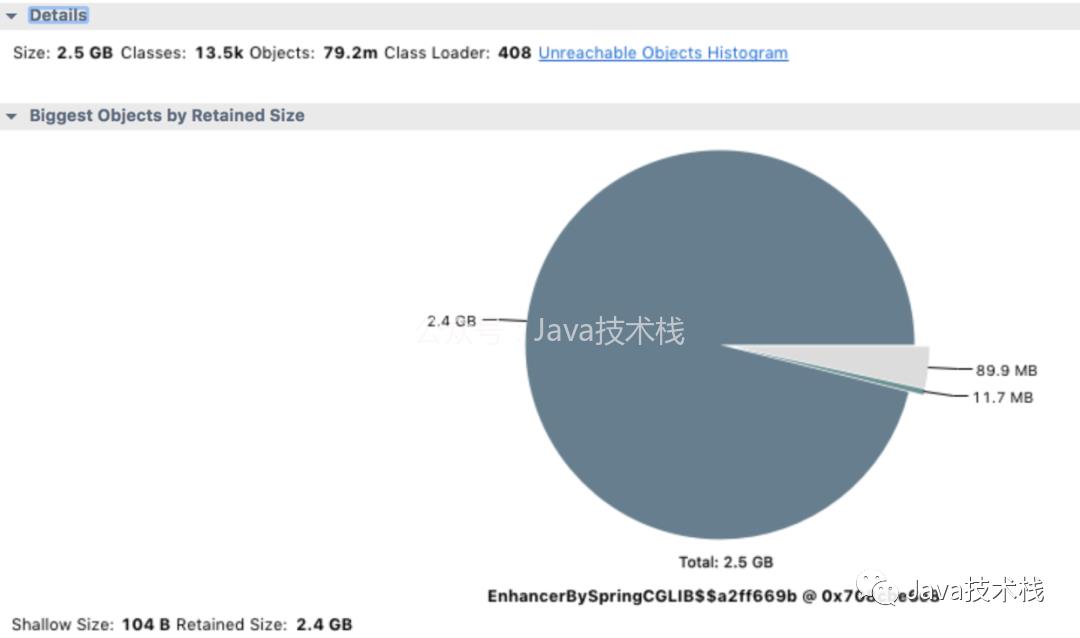
从上面的饼图中可以看出,绝大多数堆内存都被同一个内存占用了,再查看堆内存详情,向上层追溯,很快就发现了罪魁祸首。
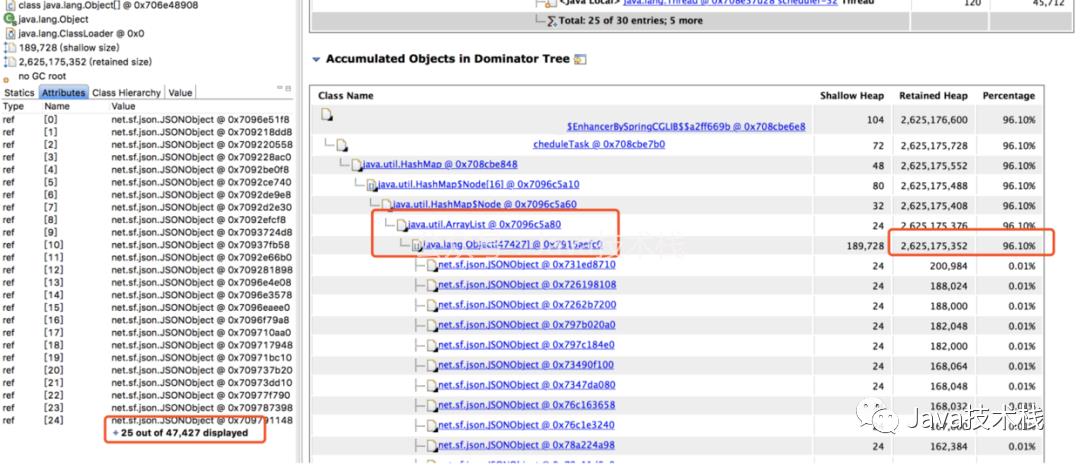
分析代码
找到内存泄漏的对象了,在项目里全局搜索对象名,它是一个 Bean 对象,然后定位到它的一个类型为 Map 的属性。
这个 Map 根据类型用 ArrayList 存储了每次探测接口响应的结果,每次探测完都塞到 ArrayList 里去分析,由于 Bean 对象不会被回收,这个属性又没有清除逻辑,所以在服务十来天没有上线重启的情况下,这个 Map 越来越大,直至将内存占满。
内存满了之后,无法再给 HTTP 响应结果分配内存了,所以一直卡在 readLine 那。而我们那个大量 I/O 的接口报警次数特别多,估计跟响应太大需要更多内存有关。
给代码 owner 提了 PR,问题圆满解决。
小结
其实还是要反省一下自己的,一开始报警邮件里还有这样的线程栈:
groovy.json.internal.JsonParserCharArray.decodeValueInternal(JsonParserCharArray.java:166)
groovy.json.internal.JsonParserCharArray.decodeJsonObject(JsonParserCharArray.java:132)
groovy.json.internal.JsonParserCharArray.decodeValueInternal(JsonParserCharArray.java:186)
groovy.json.internal.JsonParserCharArray.decodeJsonObject(JsonParserCharArray.java:132)
groovy.json.internal.JsonParserCharArray.decodeValueInternal(JsonParserCharArray.java:186)看到这种报错线程栈却没有细想,要知道 TCP 是能保证消息完整性的,况且消息没有接收完也不会把值赋给变量,这种很明显的是内部错误,如果留意后细查是能提前查出问题所在的,查问题真是差了哪一环都不行啊。
End
Stream 中的 map、peek、foreach 方法的区别?


Spring Cloud 微服务最新课程!
以上是关于怎么排查这些内存泄漏的主要内容,如果未能解决你的问题,请参考以下文章