MapReduce工作流程最详细解释
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce工作流程最详细解释相关的知识,希望对你有一定的参考价值。
参考技术AMapreduce简介
Hadoop MapReduce 源于Google发表的 MapReduce论文。Hadoop MapReduce 其实就是Google MapReduce的一个克隆版本。Hadoop 2.0即第二代Hadoop系统,其框架最核心的设计是HDFS、MapReduce和YARN。其中,HDFS为海量数据提供存储,MapReduce用于分布式计算,YARN用于进行资源管理。
其实,一次mapreduce过程就包括上图的6个步骤,input、splitting、mapping、shuffling、redecing、final redult。
文件要存储在HDFS中,每个文件被切分成多个一定大小的块也就是Block,(Hadoop1.0默认为64M,Hadoop2.0默认为128M),并且默认3个备份存储在多个的节点中。
MR通过Inputformat将数据文件从HDFS中读入取,读取完后会对数据进行split切片,切片的数量根据Block的大小所决定,然后每一个split的个数又决定map的个数,即一个split会分配一个maptask并行实例处理。
如何确定切分的文件大小?
数据进入到map函数中,然后开始按照一定的规则切分。其实这就是我们自定义的计算逻辑,我们编写mr程序的map函数的逻辑一般就在这个阶段执行。企业应用为了追求开发效率,一般都使用hive sql代替繁琐的mr程序了,这里附上一个经典的wordcount的map函数重温一下吧。
Shuffle是我们不需要编写的模块,但却是十分关键的模块。
在map中,每个 map 函数会输出一组 key/value对, Shuffle 阶段需要从所有 map主机上把相同的 key 的 key value对组合在一起,(也就是这里省去的Combiner阶段)组合后传给 reduce主机, 作为输入进入 reduce函数里。
Partitioner组件 负责计算哪些 key 应当被放到同一个 reduce 里
HashPartitioner类,它会把 key 放进一个 hash函数里,然后得到结果。如果两个 key 的哈希值 一样,他们的 key/value对 就被放到同一个 reduce 函数里。我们也把分配到同一个 reduce函数里的 key /value对 叫做一个reduce partition.
我们看到 hash 函数最终产生多少不同的结果, 这个 Hadoop job 就会有多少个 reduce partition/reduce 函数,这些 reduce函数最终被JobTracker 分配到负责 reduce 的主机上,进行处理。
Map方法之后,数据首先进入到分区方法,把数据标记好分区,然后把数据发送到环形缓冲区;环形缓冲区默认大小100m,环形缓冲区达到80%时,进行溢写; 溢写前对数据进行排序 ,排序按照对key的索引进行字典顺序排序,排序的手段快排;溢写产生大量溢写文件,需要 对溢写文件进行归并排序 ;对溢写的文件也可以进行Combiner操作,前提是汇总操作,求平均值不行。最后将文件按照分区存储到磁盘,等待Reduce端拉取。每个Reduce拉取Map端对应分区的数据。拉取数据后先存储到内存中,内存不够了,再存储到磁盘。拉取完所有数据后, 采用归并排序将内存和磁盘中的数据都进行排序 。在进入Reduce方法前,可以对数据进行分组操作。值得注意的是, 整个shuffle操作是有3次排序的。
reduce() 函数以 key 及对应的 value 列表作为输入,按照用户自己的程序逻辑,经合并 key 相同的 value 值后,产 生另外一系列 key/value 对作为最终输出写入 HDFS。
mapreduce运行流程总结
先上图,下图描绘了一个mapreduce程序的的一般运行过程和需要经过的几个阶段
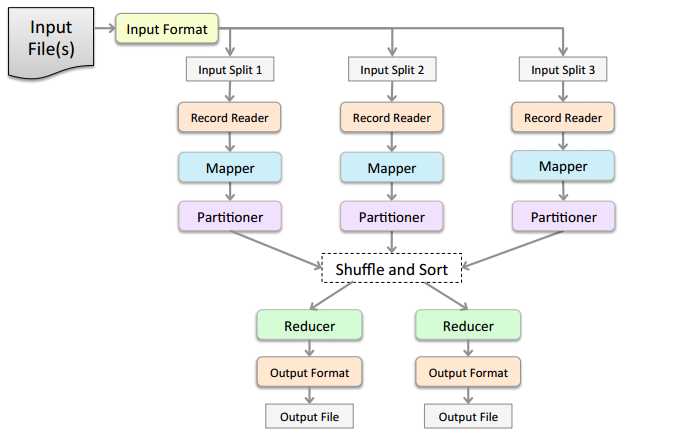
大体上我们可以将mapreduce程序划分为inputformat ,map ,shuffle,reduce,outputformat五个阶段,下面我们会详细介绍各个阶段的具体的运行细节
以最简单的wordcount程序为例,本例使用基于hadoop2.6的环境,一般的api都使用mapreudce下的,注意不要使用mapred下的api可能会引起未知错误
惯例hello word程序
driver类,负责构建mapredue任务,设置job的名称,指定任务的输入文件并设置相应的读取类,map处理类,reduce处理类,输出文件路径,mapreduce程序从driver类开始,程序运行时会根据Configuration读取到配置和yarn通信,申请运行任务的资源,申请资源之后就开始将jar包发送到yarn的各个节点执行map和reudce任务
1 package mapreduce.wordcount; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 9 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 10 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 11 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 12 13 import java.io.IOException; 14 15 /** 16 * Created by teaegg on 2016/11/21. 17 */ 18 public class WordcountDriver { 19 public static void main(String[] args) throws InterruptedException, IOException, ClassNotFoundException { 20 runjob(args); 21 } 22 23 24 public static void runjob(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 25 Configuration conf = new Configuration();//创建任务的配置对象,会自动加载hadoop的的配置文件 26 //Job job = new Job(conf);是废弃的写法,虽然依然可以使用 27 Job job = Job.getInstance(conf); 28 job.setJobName("wordcount");//设置任务的名称 29 30 //hadoop中对java一般的常用的数据类型做了封装形成了mapreduce专用的数据类型 31 job.setOutputKeyClass(Text.class);//Text.class对应了String类型 32 job.setOutputValueClass(IntWritable.class);//IntWritable.class对应了int类型 33 34 job.setMapperClass(WordcountMap.class);//设置任务的map类 35 job.setReducerClass(WordcountReduce.class);//设置任务的reduce类 36 37 job.setMapOutputKeyClass(Text.class);//设置map端输出数据类型 38 job.setMapOutputValueClass(IntWritable.class);//设置mapd端reduce的数据类型 39 //注意以上都要和map的write方法写出类型一致 40 41 42 //1. 这里不设置TextInputFormat.class也没有关系,hadoop默认调用TextInputFormat类处理, 43 //2. 注意TextInputFormat类不能用来读取Sequncefile类型文件 44 job.setInputFormatClass(TextInputFormat.class);//设置输入文件读取的类,可以hdfs上处理一般的文本文件 45 job.setOutputFormatClass(TextOutputFormat.class);//设置输出的文件类型 46 47 FileInputFormat.addInputPath(job, new Path(args[0]));//设置hdfs上输入文件路径,这里可以传入多个文件路径 48 // 可以再添加一个输入文件路径 49 //如 FileInputFormat.addInputPath(job, new Path(" ")); 50 FileOutputFormat.setOutputPath(job, new Path(args[1]));//设置hdfs上的输出文件路径, 51 52 job.waitForCompletion(true); 53 } 54 55 }
map类,其实再map类执行之前还有一个过程inputformat,这里没有详细介绍,inputformat过程负责将输入路径传入的文件做分片,每一个分片会生成一个map任务,并且会读取输入的文件分片,并返回一行记录recordreader对象交给map方法执行,就这样不断的生成recordreader对象交给map去执行,recordreader对应的就是map方法中解析的kv键值对
1 package mapreduce.wordcount; 2 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.LongWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Mapper; 7 8 import java.io.IOException; 9 10 /** 11 * Created by teaegg on 2016/11/21. 12 */ 13 public class WordcountMap extends Mapper<LongWritable, Text, Text, IntWritable> { 14 15 private Text outkey; 16 17 private IntWritable outvalue = new IntWritable(1); 18 19 public void map(LongWritable key, Text value, Context context) 20 throws IOException, InterruptedException { 21 22 //LongWritable key是这一行记录相对文件的偏移量,一般情况用不上,可以忽视 23 //inputformat过程默认采用Textinputformat类来读取hdfs上一般的文本文件,并将每一行记录转化成Text对象 24 //这是inputformat过程的一个主要职责,读取数据并交给map来处理, 25 26 String line = value.toString();//toString方法可以将Text类型的数据转换成String 27 String[] item = line.split(" ");//采用空格分隔每行数据 28 for (String str: item) { 29 outkey = new Text(str); //将每一个word再转化成Text类型 30 31 //1. 这一步是关键一步,无论是inputformat还是map或者reduce,其处理的数据都是键值对类型 32 //2. 这里调用context.write方法,将map处理好的结果写出到磁盘上,然后数据会根据key做排序,shuffle并最终 33 //到达reduce端交给reduce方法继续处理 34 //3. map端可以多次调用write方法,每次调用都是一个写出的键值对结果, 35 context.write(outkey, outvalue); 36 } 37 } 38 39 }
reduce类,reduce方法每次调用的时候会处理一个map输出的key和这个key下所有的输出的value值,
1 package mapreduce.wordcount; 2 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Reducer; 6 7 import java.io.IOException; 8 9 /** 10 * Created by teaegg on 2016/11/21. 11 * <p> 12 * 1. map端传入的是“一行”数据,而在reduce中,输入的key 即Text key是map端输出的context.write(outkey, outvalue)中设置的key 13 * 2. 而reduce方法中输入参数Iterable<IntWritable> values 是map端输出键值对相同的key下所有的value的集合 14 */ 15 public class WordcountReduce extends Reducer<Text, IntWritable, Text, IntWritable> { 16 17 public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 18 int sum = 0; 19 for (IntWritable val : values) { 20 sum += val.get(); 21 } 22 context.write(key, new IntWritable(sum)); 23 } 24 }
以上是关于MapReduce工作流程最详细解释的主要内容,如果未能解决你的问题,请参考以下文章