verilog HDL状态机 赋初值问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了verilog HDL状态机 赋初值问题相关的知识,希望对你有一定的参考价值。
最近要做数字时钟,要用LCD显示,参考的两个程序里面都有状态机,一个是调整时间用的,一个是LCD显示用的,现在被我放在一起了,该怎么处理才可以?可不可以在几个CASE后面分别赋值?
两个always可以独立写。也可以写在一起,只要触发条件相同。但是要注意一点,如果独立写,在2个alway结构中,不能对同一个变量赋值,不然就会出现错误。这就是verilog不能当做软件使用的一点体现,原因在于数字电路的输出不能随意连在一起。
欢迎追问~ 参考技术A 分成两个always模块就可以了。两个always分别写两个状态机。
当然,如果两个状态机是一样的,可以弄成一个追问
这样可以吗?reg[3:0] state1=4'b1001,state2=4'b0000;
parameter warmup=4'b0000,
...... countime=4'b1001;
两个状态机分开使用
1.建议不要reg直接赋初值,你可以全部用parameter来。也可以直接定义两个reg型的变量。状态变化就将这个reg型变量加1就行了。也可以全部用parameter,这样对状态的作用的分辨有帮助。
2.放在两个进程中,只要不在两个进程中驱动一个信号,对它赋值就可以了。如果要对同一个reg信号(作为模块的output)赋值,那么肯定需要设置两个中间寄存器来对数据进行选择。
其他应该没什么问题。其实就是把两个。v文件的输入输出结合到一起,然后把各自的除了IO以外的包括进程 reg wire声明以及其他assign赋值语句搬移到一个模块中就可以了。要注意的仅仅是没有重复的reg复制,没有重复的声明以及此模块可能需要的模块例化。
这样可以吗?reg[3:0] state1=4'b1001,state2=4'b0000;
parameter warmup=4'b0000,
...... countime=4'b1001;
两个状态机分开使用
parameter 放在always外就可以啦
HDL4SE:软件工程师学习Verilog语言
11 流水线
前面一节介绍了状态机的概念。状态机用于描述事务处理的一个程序性流程,可以组成顺序,分支,循环的事务处理流程。这些概念本来在verilog中的行为级描述中是有的,但是由于不是RTL描述,因此无法直接编译成电路,状态机则提供了顺序,分支,循环等控制结构的RTL描述。
状态机的特点是,整个处理流程任何时候只会在一个状态中,只处理一个事务。比如描述一个软件工程师的工作,可能是需求分析,概要设计,详细设计,编码,调试,测试,并在这几个状态之间来回切换,用状态机是比较恰当的。但是如果对一个分工比较明确的团队,上述几种工作可能是固定由相应的小组完成的,整个团队可以同时开展几个项目,项目在小组之间流转,特定的小组只完成针对项目的固定事务,这就是工厂的生产流水线的概念。
流水线由处理不同事务的节点组成,节点之间必须协同工作,这种协同有两种方式,一种是同步的,这种流水线每个节点事务处理的时间是固定的,事务进入节点后,会在某个固定的时钟周期后完成。此时节点之间只要在时钟同步下进行协同就行了。典型的实例是4个时钟周期完成一个32位的浮点乘法运算,其实是将浮点乘法分成四步,每一步都在一个时钟周期内完成,从前一步接收输入数据,处理后送到下一步继续处理。这样,虽然每个浮点都需要四个时钟周期才能完成,但是浮点乘法器采用流水线结构后,每个时钟周期都能够接收一个运算请求,并且输出一个结果,也就是平均每个周期能够完成一个浮点乘法运算。而且这种流水线组织各个部件之间不需要连接控制信号,它们各自按照事先规定好的时钟周期处理,就能够协同完成事务,这种协同称为同步协同。还有一种就是异步的了,由于各个节点完成事务的时钟周期不确定,可能与事务内容相关,也有可能跟外部环境(比如多节点共享的DDR读写)相关。此时节点之间就需要进行通信,来实现节点之间的协同。一般的通信手段就是用一个通知信号传递信息,比如允许信号,完成信号什么的,高级一点的用个比如FIFO之类进行缓冲,让节点之间的协同相对柔性一些,不至于造成大量的相互等待,这样有助于提高整个流水线的效率。
我们按惯例还是举个例子来说明流水线的做法,本节先讨论异步流水线,关于同步流水线后面实现RISC-V CPU时会有相应例子。
本节以流行的深度卷积神经网络推理的实现作为例子。先介绍深度卷积神经网络的基本概念,然后描述具体实现步骤,也会分多次逐步修改实现,一开始是用c语言实现各个单元,后面逐步把每个c语言描述的模型改写成verilog的实现。目标是,将一个训练好的网络模型转换为c语言代码,然后在基本库的支持下运行推理过程,在运行过程中将网络结构和系数转换为verilog语言表示,然后将verilog代码描述的卷积神经网络编译为目标代码,用HDL4SE系统运行。
11.1 深度卷积神经网络简介
深度卷积神经网络是进行数据分类的比较有效的算法,本节中主要介绍GoogLeNet网络,它的输入是固定的224x224像素大小的彩色图像数据,每个像素有三个分量,对应RGB分量。GoogLeNet网络将图像分为1000类,每一幅图像经过GoogLeNet计算后,输出一个1000x1的向量,表示这幅图像属于对应类的概率。注意其中的字母L用大写,据说是为了纪念深度神经网络的先驱LeNet。
深度神经网络的基本算法是卷积。所谓卷积,可以理解为用一个模板,去与目标进行乘累加计算,得到的结果是目标与模板的相符程度。模板在宽度和高度上一般比较小,一般是1x1, 3x3, 5x5, 7x7 ,据说也有更大的。模板中每个位置对应图像每个分量也有一个值,这样对三个分量的原始图像, 一个7x7模板实际上由7x7x3个数字组成。一个1x1的模板,实际上是对分量之间的相关性进行计算,比如检验彩色图片中像素是否为红色,可能用个(1,-3,-3)的1x1x3模板去跟每个像素的RGB分量进行乘累加,后面抛掉小于零的结果,得到的数字基本上是像素偏红的程度。一般把模板称为卷积核,模板中的数字称为卷积核系数。用这个模板套在输入数据上,将7x7x3中的每个系数与对应的图像数据相乘后累加在一起,构成这次计算的一个输出值,可以理解为是图像这个位置与模板的相似程度。在水平方向和垂直方向上移动模板,每次移动的步长称为卷积的步长(Stride)。移动后再计算一次乘累加值,这样每移动到一个位置就得到一个的值,于是就构成了输出图像的一个分量。据说麻坛高手用拇指在牌面一划,就能通过卷积认出手上的牌是红中、发财、三万、九筒、七条等等中的哪一种,低手就只能区分白板和非白板,会不会跟他脑中的卷积核配置相关啊。用多个卷积核对图像进行计算,就可以得到一幅多分量图像,实际上已经不是通常意义下的图像了,姑且继续称之为图像吧。一般计算之前会在输入图像周边扩展几个像素行或列,保证图像边缘的数据信息不会丢失,这个称为边缘扩展(PAD)。
总结一下:对InWxInHxInC的输入图像,一个卷积操作就是用N个kWxkHxInC系数组成的卷积核,按照(sW,sH)的步长在图像上移动,移动到边缘时假定边上有pW, pH的扩展像素,扩展的图像像素分量全部假设为0。每个位置将kWxkHxInC个系数和图像数据对应相乘再累加在一起,生成一个输出图像的像素,这样输出的图像是OutWxOutHxN,其中
OutH = (InH + 2 * pH - kH) / sH + 1;
OutW = (InW + 2 * pW - kW) / sW + 1;
这个运算操作将一个InWxInHxInC的输入图像变换为一个OutWxOutHxOutC的图像。卷积核的参数包括卷积的大小kW, kH,卷积核的个数N也就是输出图像的分量数OutC,平移步长sW, sH,扩展宽度pW, pH,如下图所示。
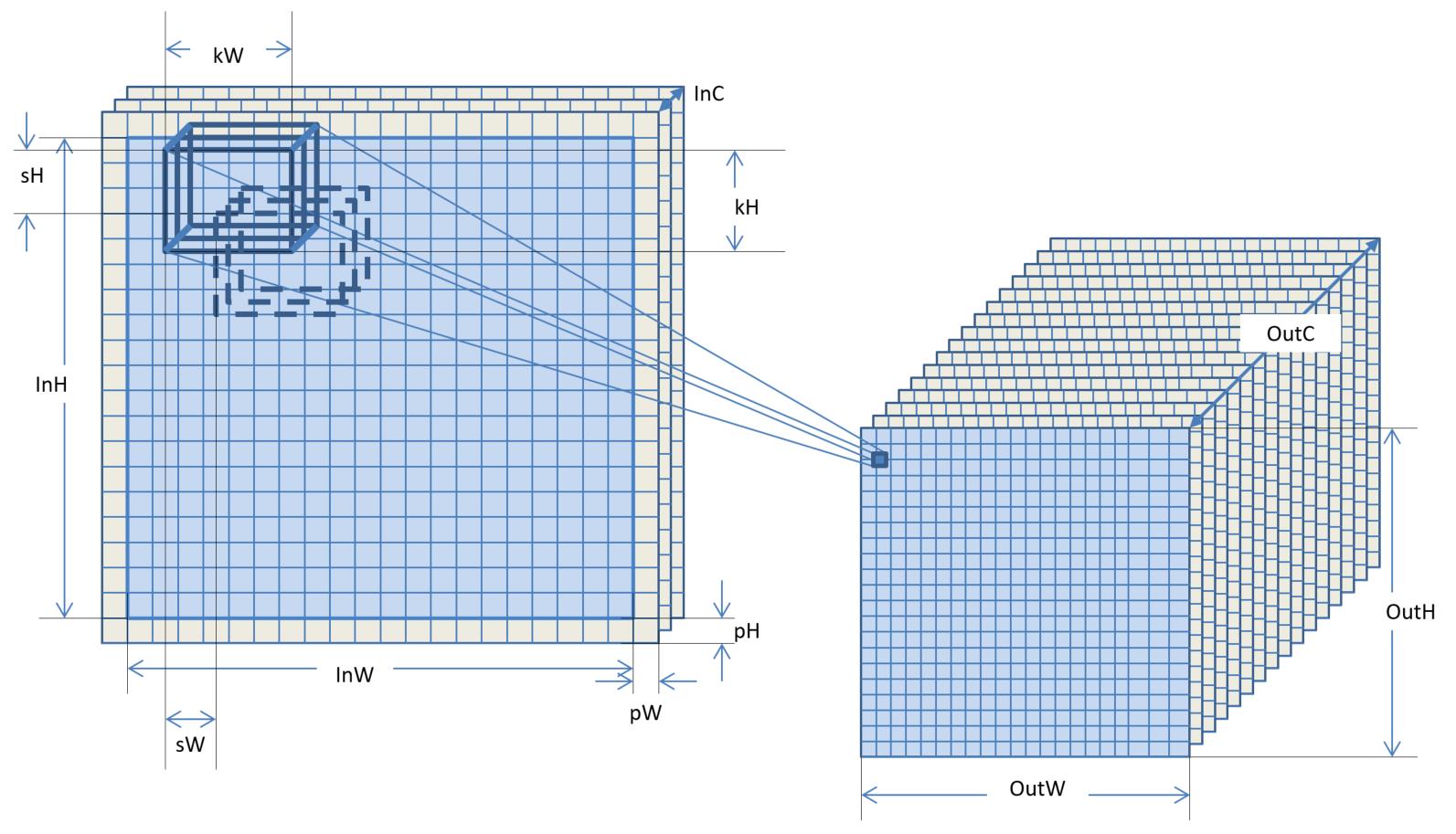
卷积计算的结果中,每个结果像素的分量与原始图像中的一个卷积核大小范围内的所有像素的所有分量都相关,因此卷积核的大小,其实是结果分量中信息来源范围。从原理上讲,卷积核大小大的,可以从原图像中较大范围内得到相关的信息,卷积核小的,相关的范围就小一些,不同大小的卷积核构成了不同尺度的相关信息。按说卷积核大的能够收集到的信息要更加全面一些,大不了把有些系数设置为0,效果就跟小的核一样了,然而卷积核大的计算量要大,3x3是1x1的九倍,5x5是3x3的将近三倍,7x7是5x5的将近两倍。更重要的原因是,较大的卷积核由于范围输入更大,得到的特征值反而更容易受到污染,需要经过更多的样本计算才能得到合适的系数,我们看东西时实在眼花缭乱,可以眯着眼睛看,让进来的图像信息少一些,反而更容易识别是什么场景。因此设计算法时需要考虑计算量的考虑还需要考虑用合适大小的卷积核,当然分量数直接跟计算量线性相关,因此控制分量数也是算法设计中的一个考虑因素。
除了卷积之外,还有全连接层也是线性操作,就是输出图像中的像素分量跟输入图像中的每个像素及分量都相关,有对应的系数,不是类似卷积的局部相关,可以看成是一个大小跟输入图像一样大而且无法移动的卷积核,当然结果也就是一个数。对图像的操作还有所谓Pooling,有点象卷积,只不过它不是通过系数乘累加,而是计算出局部范围内的最大值或平均值, LRN则是在分量内或者跨分量进行能量归一化操作,这些都是非线性操作,还有更多类型的操作,每个操作称为一个算子。类型众多的算子给网络设计带来了更多的可能。
一般卷积或者Pooling之后对生成的每个像素分量会有一个所谓的激活函数的概念,大概的意思是模拟人类神经元细胞的输出必须有个最低阈值才能激活的意思。激活函数一般是非线性的,比如常用的ReLU激活,就是将小于0的分量全部变成0,只有大于0的分量才有机会携带信息参与后面的计算。(理论上有说道吗?我也不大清楚)
从理论上可以证明,用单层的卷积计算或者全连接计算是无法完成复杂分类的,因此卷积神经网络一般是多层连接在一起的,前面的输出图像作为后面的输入图像,构成所谓的深度卷积神经网络。后面还出现了一个输出图像送到多个不同的算子,或者多个计算节点的输出汇总成一个输出,前者试图对一个输出图像进行不同(尺度或方法)的特征提取,后者试图将不同的方法提取出来的特征连接在一起,通过一个卷积或其他办法得到这些特征的之间相关性,获得新的特征。这样一来,深度神经网络的计算就构成了一个计算网络。
在卷积神经网络的发展中,对于如何设计计算网络,没有明确的理论或者方法做指导,也无法对一个网络的效果进行理论分析,似乎大家都是拼结果,由结果好坏来证明网络的好坏(当然,也许是孤陋寡闻了…)。然而有一种所谓的inception结构,在网络中作为基本的构成部件,得到了很多网络模型的认同。inception结构的的基本思路是对同一个输入图像进行1x1, 3x3, 5x5三个卷积计算和一个Pooling计算,注意设置参数让每个计算输出的w,h一致,但是输出的分量数可以不一样,每个卷积后面都用ReLU进行激活,最后把四个计算结果的每个像素的各个分量合并在一起(Concat),形成一个新的图像,这样就能够将输入图像的不同尺度卷积和Pool的结果相关在一起,得到更为本质的图像特征(为什么?理论上能说道么?)。inception结构已经发展了四个版本,基本思路是一样的,只是在3x3, 5x5和Pooling的卷积的处理不同,大部分是为了减少计算量,比如在3x3之前先做个1x1, 5x5之前也先做个1x1,缩减输入分量数,达到减少计算量的目的,再比如用1x3和3x3替代5x5,减少计算量等等。
在GoogLeNet中,inception的结构如下:
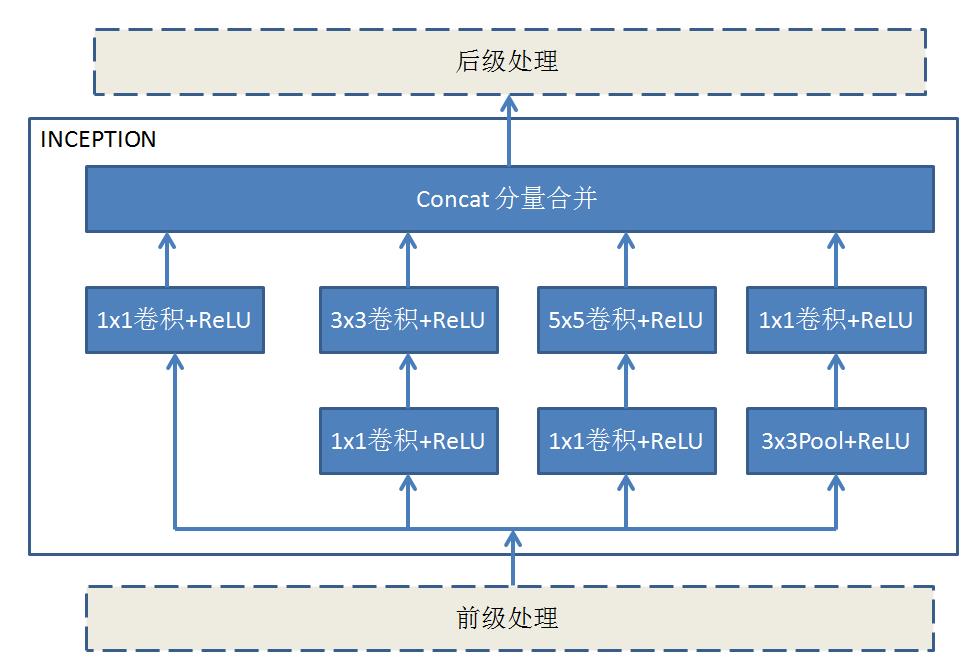
整个GoogLeNet网络中有9个Inception结构,每个结构中只是输出的分量数不同。这些inception结构再加上一些其他节点构成整个GoogLeNet网络结构如下:

这里看着似乎就是一条流水线,然而如果把其中的inception展开,那么这个网络还是挺复杂的。下面是这个网络的计算过程:
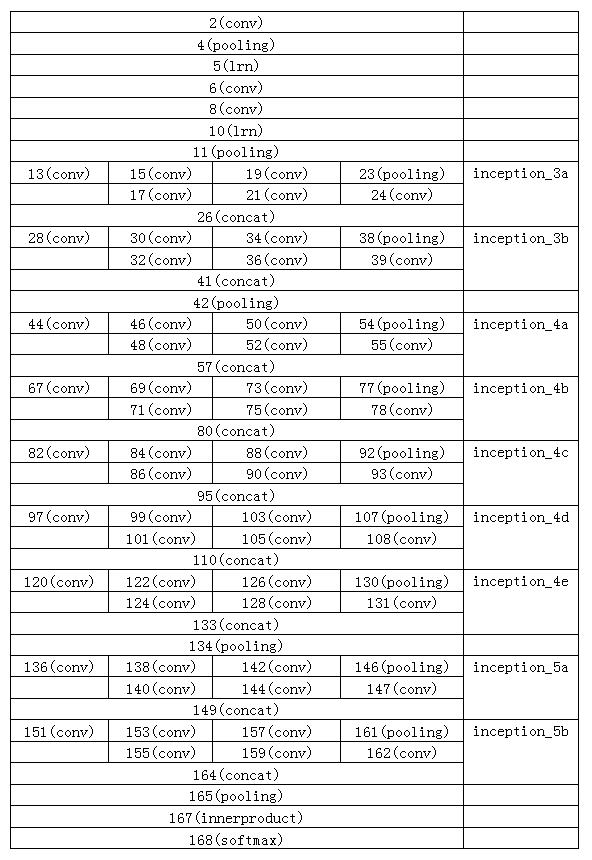
以下是各个节点的结构参数表,我们进行初步的统计,得到GoogLeNet对一幅图进行分类计算,需要的计算量是6390669848(乘累加),大概6.4G次左右,理论上1Tops的有效计算能力每秒能够分类156幅图像。
| NO | 名称 | 类型 | INW | INH | INC | OUTW | OUTH | OUTC | W/C0 | H/C1 | SW/C2 | SH/C3 | PW | PH | N | ACT | 计算量 | 系数个数 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | data | Data | 224 | 224 | 3 | 224 | 224 | 3 | ||||||||||
| 2 | conv1/7x7_s2 | Convolution | 224 | 224 | 3 | 112 | 112 | 64 | 7 | 7 | 2 | 2 | 3 | 3 | 64 | ReLU | 118816768 | 9472 |
| 4 | pool1/3x3_s2 | Pooling | 112 | 112 | 64 | 56 | 56 | 64 | 3 | 3 | 2 | 2 | 0 | 0 | 115806208 | |||
| 5 | pool1/norm1 | LRN | 56 | 56 | 64 | 56 | 56 | 64 | 802816 | |||||||||
| 6 | conv2/3x3_reduce | Convolution | 56 | 56 | 64 | 56 | 56 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 13045760 | 4160 |
| 8 | conv2/3x3 | Convolution | 56 | 56 | 64 | 56 | 56 | 192 | 3 | 3 | 1 | 1 | 1 | 1 | 192 | ReLU | 347418624 | 110784 |
| 10 | conv2/norm2 | LRN | 56 | 56 | 192 | 56 | 56 | 192 | 2408448 | |||||||||
| 11 | pool2/3x3_s2 | Pooling | 56 | 56 | 192 | 28 | 28 | 192 | 3 | 3 | 2 | 2 | 0 | 0 | 260262912 | |||
| 13 | inception_3a/1x1 | Convolution | 28 | 28 | 192 | 28 | 28 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 9683968 | 12352 |
| 15 | inception_3a/3x3_reduce | Convolution | 28 | 28 | 192 | 28 | 28 | 96 | 1 | 1 | 1 | 1 | 0 | 0 | 96 | ReLU | 14525952 | 18528 |
| 17 | inception_3a/3x3 | Convolution | 28 | 28 | 96 | 28 | 28 | 128 | 3 | 3 | 1 | 1 | 1 | 1 | 128 | ReLU | 86804480 | 110720 |
| 19 | inception_3a/5x5_reduce | Convolution | 28 | 28 | 192 | 28 | 28 | 16 | 1 | 1 | 1 | 1 | 0 | 0 | 16 | ReLU | 2420992 | 3088 |
| 21 | inception_3a/5x5 | Convolution | 28 | 28 | 16 | 28 | 28 | 32 | 5 | 5 | 1 | 1 | 2 | 2 | 32 | ReLU | 10060288 | 12832 |
| 23 | inception_3a/pool | Pooling | 28 | 28 | 192 | 28 | 28 | 192 | 3 | 3 | 1 | 1 | 1 | 1 | 260262912 | |||
| 26 | inception_3a/output | Concat | 28 | 28 | 28 | 28 | 416 | 64 | 128 | 32 | 192 | |||||||
| 28 | inception_3b/1x1 | Convolution | 28 | 28 | 416 | 28 | 28 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 41846784 | 53376 |
| 30 | inception_3b/3x3_reduce | Convolution | 28 | 28 | 416 | 28 | 28 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 41846784 | 53376 |
| 32 | inception_3b/3x3 | Convolution | 28 | 28 | 128 | 28 | 28 | 192 | 3 | 3 | 1 | 1 | 1 | 1 | 192 | ReLU | 173558784 | 221376 |
| 34 | inception_3b/5x5_reduce | Convolution | 28 | 28 | 416 | 28 | 28 | 32 | 1 | 1 | 1 | 1 | 0 | 0 | 32 | ReLU | 10461696 | 13344 |
| 36 | inception_3b/5x5 | Convolution | 28 | 28 | 32 | 28 | 28 | 96 | 5 | 5 | 1 | 1 | 2 | 2 | 96 | ReLU | 60286464 | 76896 |
| 38 | inception_3b/pool | Pooling | 28 | 28 | 416 | 28 | 28 | 416 | 3 | 3 | 1 | 1 | 1 | 1 | 1221409280 | |||
| 39 | inception_3b/pool_proj | Convolution | 28 | 28 | 416 | 28 | 28 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 20923392 | 26688 |
| 41 | inception_3b/output | Concat | 28 | 28 | 28 | 28 | 480 | 128 | 192 | 96 | 64 | |||||||
| 42 | pool3/3x3_s2 | Pooling | 28 | 28 | 480 | 14 | 14 | 480 | 3 | 3 | 2 | 2 | 0 | 0 | 406519680 | |||
| 44 | inception_4a/1x1 | Convolution | 14 | 14 | 480 | 14 | 14 | 192 | 1 | 1 | 1 | 1 | 0 | 0 | 192 | ReLU | 18100992 | 92352 |
| 46 | inception_4a/3x3_reduce | Convolution | 14 | 14 | 480 | 14 | 14 | 96 | 1 | 1 | 1 | 1 | 0 | 0 | 96 | ReLU | 9050496 | 46176 |
| 48 | inception_4a/3x3 | Convolution | 14 | 14 | 96 | 14 | 14 | 208 | 3 | 3 | 1 | 1 | 1 | 1 | 208 | ReLU | 35264320 | 179920 |
| 50 | inception_4a/5x5_reduce | Convolution | 14 | 14 | 480 | 14 | 14 | 16 | 1 | 1 | 1 | 1 | 0 | 0 | 16 | ReLU | 1508416 | 7696 |
| 52 | inception_4a/5x5 | Convolution | 14 | 14 | 16 | 14 | 14 | 48 | 5 | 5 | 1 | 1 | 2 | 2 | 48 | ReLU | 3772608 | 19248 |
| 54 | inception_4a/pool | Pooling | 14 | 14 | 480 | 14 | 14 | 480 | 3 | 3 | 1 | 1 | 1 | 1 | 406519680 | |||
| 55 | inception_4a/pool_proj | Convolution | 14 | 14 | 480 | 14 | 14 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 6033664 | 30784 |
| 57 | inception_4a/output | Concat | 14 | 14 | 14 | 14 | 512 | 192 | 208 | 48 | 64 | |||||||
| 59 | loss1/ave_pool | Pooling | 14 | 14 | 512 | 4 | 4 | 512 | 5 | 5 | 3 | 3 | 0 | 0 | 104865792 | |||
| 67 | inception_4b/1x1 | Convolution | 14 | 14 | 512 | 14 | 14 | 160 | 1 | 1 | 1 | 1 | 0 | 0 | 160 | ReLU | 16087680 | 82080 |
| 69 | inception_4b/3x3_reduce | Convolution | 14 | 14 | 512 | 14 | 14 | 112 | 1 | 1 | 1 | 1 | 0 | 0 | 112 | ReLU | 11261376 | 57456 |
| 71 | inception_4b/3x3 | Convolution | 14 | 14 | 112 | 14 | 14 | 224 | 3 | 3 | 1 | 1 | 1 | 1 | 224 | ReLU | 44299136 | 226016 |
| 73 | inception_4b/5x5_reduce | Convolution | 14 | 14 | 512 | 14 | 14 | 24 | 1 | 1 | 1 | 1 | 0 | 0 | 24 | ReLU | 2413152 | 12312 |
| 75 | inception_4b/5x5 | Convolution | 14 | 14 | 24 | 14 | 14 | 64 | 5 | 5 | 1 | 1 | 2 | 2 | 64 | ReLU | 7538944 | 38464 |
| 77 | inception_4b/pool | Pooling | 14 | 14 | 512 | 14 | 14 | 512 | 3 | 3 | 1 | 1 | 1 | 1 | 462522368 | |||
| 78 | inception_4b/pool_proj | Convolution | 14 | 14 | 512 | 14 | 14 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 6435072 | 32832 |
| 80 | inception_4b/output | Concat | 14 | 14 | 14 | 14 | 512 | 160 | 224 | 64 | 64 | |||||||
| 82 | inception_4c/1x1 | Convolution | 14 | 14 | 64 | 14 | 14 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 1630720 | 8320 |
| 84 | inception_4c/3x3_reduce | Convolution | 14 | 14 | 64 | 14 | 14 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 1630720 | 8320 |
| 86 | inception_4c/3x3 | Convolution | 14 | 14 | 128 | 14 | 14 | 256 | 3 | 3 | 1 | 1 | 1 | 1 | 256 | ReLU | 57852928 | 295168 |
| 88 | inception_4c/5x5_reduce | Convolution | 14 | 14 | 64 | 14 | 14 | 24 | 1 | 1 | 1 | 1 | 0 | 0 | 24 | ReLU | 305760 | 1560 |
| 90 | inception_4c/5x5 | Convolution | 14 | 14 | 24 | 14 | 14 | 64 | 5 | 5 | 1 | 1 | 2 | 2 | 64 | ReLU | 7538944 | 38464 |
| 92 | inception_4c/pool | Pooling | 14 | 14 | 64 | 14 | 14 | 64 | 3 | 3 | 1 | 1 | 1 | 1 | 7237888 | |||
| 93 | inception_4c/pool_proj | Convolution | 14 | 14 | 64 | 14 | 14 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 815360 | 4160 |
| 95 | inception_4c/output | Concat | 14 | 14 | 14 | 14 | 512 | 128 | 256 | 64 | 64 | |||||||
| 97 | inception_4d/1x1 | Convolution | 14 | 14 | 64 | 14 | 14 | 112 | 1 | 1 | 1 | 1 | 0 | 0 | 112 | ReLU | 1426880 | 7280 |
| 99 | inception_4d/3x3_reduce | Convolution | 14 | 14 | 64 | 14 | 14 | 144 | 1 | 1 | 1 | 1 | 0 | 0 | 144 | ReLU | 1834560 | 9360 |
| 101 | inception_4d/3x3 | Convolution | 14 | 14 | 144 | 14 | 14 | 288 | 3 | 3 | 1 | 1 | 1 | 1 | 288 | ReLU | 73213056 | 373536 |
| 103 | inception_4d/5x5_reduce | Convolution | 14 | 14 | 64 | 14 | 14 | 32 | 1 | 1 | 1 | 1 | 0 | 0 | 32 | ReLU | 407680 | 2080 |
| 105 | inception_4d/5x5 | Convolution | 14 | 14 | 32 | 14 | 14 | 64 | 5 | 5 | 1 | 1 | 2 | 2 | 64 | ReLU | 10047744 | 51264 |
| 107 | inception_4d/pool | Pooling | 14 | 14 | 64 | 14 | 14 | 64 | 3 | 3 | 1 | 1 | 1 | 1 | 7237888 | |||
| 108 | inception_4d/pool_proj | Convolution | 14 | 14 | 64 | 14 | 14 | 64 | 1 | 1 | 1 | 1 | 0 | 0 | 64 | ReLU | 815360 | 4160 |
| 110 | inception_4d/output | Concat | 14 | 14 | 14 | 14 | 528 | 112 | 288 | 64 | 64 | |||||||
| 112 | loss2/ave_pool | Pooling | 14 | 14 | 528 | 4 | 4 | 528 | 5 | 5 | 3 | 3 | 0 | 0 | 111522048 | |||
| 120 | inception_4e/1x1 | Convolution | 14 | 14 | 528 | 14 | 14 | 256 | 1 | 1 | 1 | 1 | 0 | 0 | 256 | ReLU | 26543104 | 135424 |
| 122 | inception_4e/3x3_reduce | Convolution | 14 | 14 | 528 | 14 | 14 | 160 | 1 | 1 | 1 | 1 | 0 | 0 | 160 | ReLU | 16589440 | 84640 |
| 124 | inception_4e/3x3 | Convolution | 14 | 14 | 160 | 14 | 14 | 320 | 3 | 3 | 1 | 1 | 1 | 1 | 320 | ReLU | 90379520 | 461120 |
| 126 | inception_4e/5x5_reduce | Convolution | 14 | 14 | 528 | 14 | 14 | 32 | 1 | 1 | 1 | 1 | 0 | 0 | 32 | ReLU | 3317888 | 16928 |
| 128 | inception_4e/5x5 | Convolution | 14 | 14 | 32 | 14 | 14 | 128 | 5 | 5 | 1 | 1 | 2 | 2 | 128 | ReLU | 20095488 | 102528 |
| 130 | inception_4e/pool | Pooling | 14 | 14 | 528 | 14 | 14 | 528 | 3 | 3 | 1 | 1 | 1 | 1 | 491878464 | |||
| 131 | inception_4e/pool_proj | Convolution | 14 | 14 | 528 | 14 | 14 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 13271552 | 67712 |
| 133 | inception_4e/output | Concat | 14 | 14 | 14 | 14 | 832 | 256 | 320 | 128 | 128 | |||||||
| 134 | pool4/3x3_s2 | Pooling | 14 | 14 | 832 | 7 | 7 | 832 | 3 | 3 | 2 | 2 | 0 | 0 | 305311552 | |||
| 136 | inception_5a/1x1 | Convolution | 7 | 7 | 832 | 7 | 7 | 256 | 1 | 1 | 1 | 1 | 0 | 0 | 256 | ReLU | 10449152 | 213248 |
| 138 | inception_5a/3x3_reduce | Convolution | 7 | 7 | 832 | 7 | 7 | 160 | 1 | 1 | 1 | 1 | 0 | 0 | 160 | ReLU | 6530720 | 133280 |
| 140 | inception_5a/3x3 | Convolution | 7 | 7 | 160 | 7 | 7 | 320 | 3 | 3 | 1 | 1 | 1 | 1 | 320 | ReLU | 22594880 | 461120 |
| 142 | inception_5a/5x5_reduce | Convolution | 7 | 7 | 832 | 7 | 7 | 32 | 1 | 1 | 1 | 1 | 0 | 0 | 32 | ReLU | 1306144 | 26656 |
| 144 | inception_5a/5x5 | Convolution | 7 | 7 | 32 | 7 | 7 | 128 | 5 | 5 | 1 | 1 | 2 | 2 | 128 | ReLU | 5023872 | 102528 |
| 146 | inception_5a/pool | Pooling | 7 | 7 | 832 | 7 | 7 | 832 | 3 | 3 | 1 | 1 | 1 | 1 | 305311552 | |||
| 147 | inception_5a/pool_proj | Convolution | 7 | 7 | 832 | 7 | 7 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 5224576 | 106624 |
| 149 | inception_5a/output | Concat | 7 | 7 | 7 | 7 | 832 | 256 | 320 | 128 | 128 | |||||||
| 151 | inception_5b/1x1 | Convolution | 7 | 7 | 832 | 7 | 7 | 384 | 1 | 1 | 1 | 1 | 0 | 0 | 384 | ReLU | 15673728 | 319872 |
| 153 | inception_5b/3x3_reduce | Convolution | 7 | 7 | 832 | 7 | 7 | 192 | 1 | 1 | 1 | 1 | 0 | 0 | 192 | ReLU | 7836864 | 159936 |
| 155 | inception_5b/3x3 | Convolution | 7 | 7 | 192 | 7 | 7 | 384 | 3 | 3 | 1 | 1 | 1 | 1 | 384 | ReLU | 32532864 | 663936 |
| 157 | inception_5b/5x5_reduce | Convolution | 7 | 7 | 832 | 7 | 7 | 48 | 1 | 1 | 1 | 1 | 0 | 0 | 48 | ReLU | 1959216 | 39984 |
| 159 | inception_5b/5x5 | Convolution | 7 | 7 | 48 | 7 | 7 | 128 | 5 | 5 | 1 | 1 | 2 | 2 | 128 | ReLU | 7532672 | 153728 |
| 161 | inception_5b/pool | Pooling | 7 | 7 | 832 | 7 | 7 | 832 | 3 | 3 | 1 | 1 | 1 | 1 | 305311552 | |||
| 162 | inception_5b/pool_proj | Convolution | 7 | 7 | 832 | 7 | 7 | 128 | 1 | 1 | 1 | 1 | 0 | 0 | 128 | ReLU | 5224576 | 106624 |
| 164 | inception_5b/output | Concat | 7 | 7 | 7 | 7 | 1024 | 384 | 384 | 128 | 128 | |||||||
| 165 | pool5/7x7_s1 | Pooling | 7 | 7 | 1024 | 1 | 1 | 1024 | 7 | 7 | 1 | 1 | 0 | 0 | 51381248 | |||
| 167 | loss3/classifier | InnerProduct | 1 | 1 | 1024 | 1 | 1 | 1000 | 1000 | 1024000 | 1024000 | |||||||
| 168 | loss3/loss3 | SoftmaxWithLoss | 1 | 1 | 1000 | 1 | 1 | 1000 | 1000 | |||||||||
| 合计 | 6390669848 | 6735888 |
总共有85个不同类型的节点,注意中间有inception结构,ReLU已经跟卷积层节点合在一起。
每个节点我们统一看成是一个数据处理单元,输入来自于上一节点的输出,每个节点包括一个处理单元,数据缓冲区,如果是卷积节点和全连接节点还包括系数缓冲区。我们用数据缓冲区来协同上下游节点的处理过程。具体过程是,数据缓冲区先允许上游节点写,上游节点写完成后,通知数据缓冲区,数据缓冲区于是禁止上游节点写入,并允许下游节点读,下游节点读完后通知数据缓冲区,数据缓冲区又开放上游节点的写允许,这样就可以形成一个前后协同的流水线结构。这个结构可以让多幅图在流水线中同时进行分类。下面是计算节点的示意图:
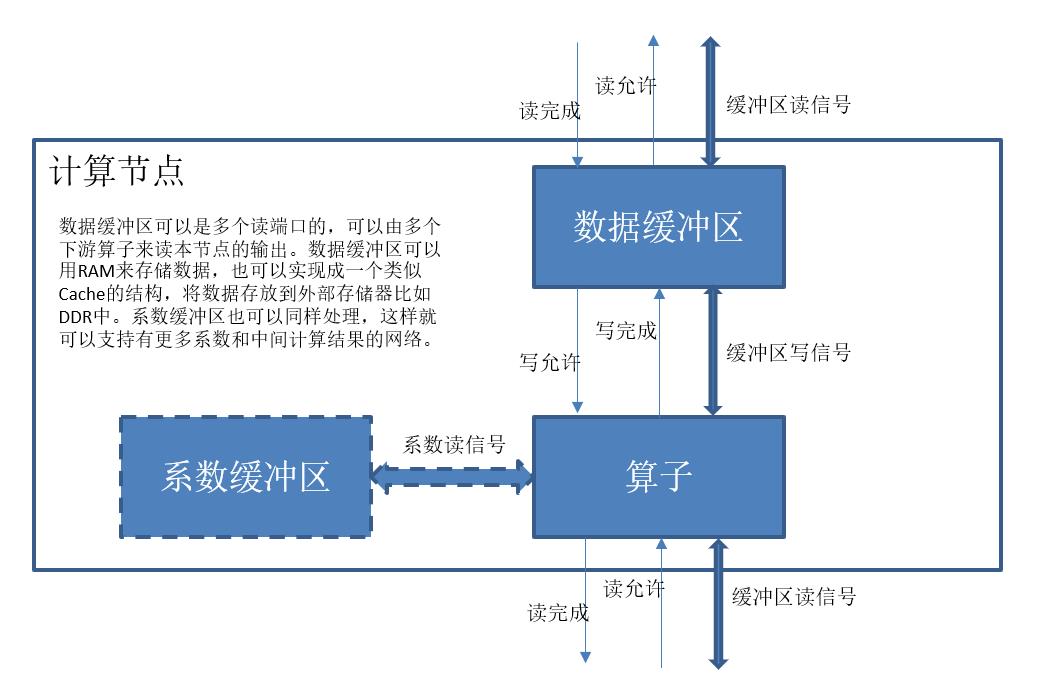
具体配置时,可以根据每个节点生成的数据大小来配置存储器,每个缓冲区用内部的RAM实现,系数缓冲区也如此处理。这样处理对内部存储器的大小要求比较高,很多FPGA都无法满足要求,此时可以用一个cache结构来实现缓冲区,数据统一存放在DDR等外存中。另外,对计算量比较大的节点,比如卷积或者池化节点,还可以分成若干个并发的子节点,每个负责计算其中的一部分。
我们目前的实现方案,采用最简单的方案,每个缓冲区用RAM实现FIFO方式提供流水线控制,参数也放在RAM中,每个节点不进行分割,作为一个单一节点处理。
11.2 深度卷积神经网络基本单元
我们来定义每个节点可能的类型,也就是深度卷积神经网络的基本单元。从11.1中的分析可以看出,我们需要如下的基本单元:
| 单元名称 | 模块名 | 功能 |
|---|---|---|
| 卷积 | Convolution | 读入上游的图像数据和卷积系数数据,进行卷积计算和激活函数计算 |
| 池化 | Pooling | 读入上游的图像数据,完成池化计算 |
| 汇合 | Concat | 将多个上游输出汇合成一个 |
| 局部归一化 | LRN | 对输入图像进行局部响应归一化处理 |
| 全连接点积 | InnerProduct | 对输入数据进行全连接点积计算 |
| 归一化 | Softmax | 对输入数据进行归一化,输出分类结果概率值 |
| 数据缓冲区 | buffer | 保存节点生成的数据,供下游节点读,输出读写允许信号, 协同上下游的工作流程数据缓冲区根据读写节点数量不同分别有一读一写, 一读四写,四读一写,四读四写等类型,缓冲区在处理多个读写节点的信号时, 可以考虑用分时复用的方式提供服务,也可以设计一个命令FIFO,放松节点和 缓冲区之间的耦合,提高处理效率 |
| 数据源 | datasource | 提供输入数据,先可以提供一个简单的固定输入数据,将来可以考虑从目录中读 一系列图片进行分类,也可以直接从摄像头获得数据。 |
| 结果输出 | dataoutput | 读出分类结果,输出Top 5的类型名称和对应的概率值 |
事实上,caffe支持的算子类型很多,这里只给出了我们关心的几个,能够支持GoogLeNet的运行。如果运行其他网络,可能需要新的算子支持,需要重新定义和实现新的基本单元。
我们给出基本单元的verilog描述如下,目前基本单元正在用c语言实现,后面先验证c语言实现的版本,然后在逐个改写成verilog语言实现,这样我们就有了一个全部由verilog代码实现的深度卷积神经网络的推理系统了。
/*
* cnncell.v
202107030835: rxh, initial version
*/
(*
HDL4SE="LCOM",
CLSID="C72D0D42-2D4D-4DC3-9DDA-4F58CE7569BC",
softmodule="hdl4se"
*)
module hdl4se_cnn_coeffbuf
#(parameter filename="test.coeff")
(
input wClk,
input nwReset,
input wCoeffRead,
output wCoeffReadValid,
input [31:0] bCoeffReadAddr,
output[31:0] bCoeffReadData,
output[31:0] bCoeffOffset,
output[31:0] bCoeffScale,
output[15:0] bCoeff_N,
output[15:0] bCoeff_C,
output[15:0] bCoeff_H,
output[15:0] bCoeff_W,
output[31:0] bCoeffBiasOffset,
output[31:0] bCoeffBiasScale,
output[15:0] bCoeffBias_N,
output[15:0] bCoeffBias_C,
output[15:0] bCoeffBias_H,
output[15:0] bCoeffBias_W
);
endmodule
(*
HDL4SE="LCOM",
CLSID="230946EF-3EC1-43EC-A841-CDE8A9E97314",
softmodule="hdl4se"
*)
module hdl4se_fifo
#(parameter WIDTH=16, DEPTH=128)
(
input wClk,
input nwReset,
input wRead,
output wDataValid,
output[WIDTH-1:0] bReadData,
output wWriteEnable,
input wWrite,
input [WIDTH-1:0] bWriteData
);
endmodule
(*
HDL4SE="LCOM",
CLSID="9AA0D743-5FFB-4649-ACEC-4B4675AE2A57",
softmodule="hdl4se"
*)
module hdl4se_cnn_buf_r4
#(parameter wordsize=32, wordcount=1024)
(
input wClk,
input nwReset,
input wDataRead_0,
output wDataReadValid_0,
output [31:0]bDataReadData_0,
input wDataRead_1,
output wDataReadValid_1,
output [31:0]bDataReadData_1,
input wDataRead_2,
output wDataReadValid_2,
output [31:0]bDataReadData_2,
input wDataRead_3,
output wDataReadValid_3,
output [31:0]bDataReadData_3,
output wDataWriteEnable,
input wDataWrite,
input [31:0] bDataWriteData
);
endmodule
`define ACTIVATION_NONE 0
`define ACTIVATION_RELU 1
`define ACTIVATION_TANH 2
`define ACTIVATION_SIGMOID 3
`define ACTIVATION_RELUNEG 4
(*
HDL4SE="LCOM",
CLSID="FB3D226E-D508-476B-81E1-F3B22CCF8F11",
softmodule="hdl4se"
*)
module hdl4se_cnn_convolution
#(parameter
INW=224, INH=224, INC=3,
OUTW=112, OUTH=112, OUTC=64,
W=7, H=7,
SW=2, SH=2,
PW=3, PH=3,
ACT_FUNC=`ACTIVATION_NONE)
(
/*
inputsize[0] = INH;
inputsize[1] = INW;
inputsize[2] = INC;
outputsize[0] = (INH + 2 * PH - H) / SH + 1;
outputsize[1] = (INW + 2 * PW - W) / SW + 1;
outputsize[2] = OUTC;
*/
input wClk,
input nwReset,
output wCoeffRead, /*系数读接口*/
input wCoeffReadValid,
output [31:0] bCoeffReadAddr,
input [31:0] bCoeffReadData,
input [31:0] bCoeffOffset,
input [31:0] bCoeffScale,
input [15:0] bCoeff_N,
input [15:0] bCoeff_C,
input [15:0] bCoeff_H,
input [15:0] bCoeff_W,
input [31:0] bCoeffBiasOffset,
input [31:0] bCoeffBiasScale,
input [15:0] bCoeffBias_N,
input [15:0] bCoeffBias_C,
input [15:0] bCoeffBias_H,
input [15:0] bCoeffBias_W,
output wDataRead,
input wDataReadValid,
input [31:0] bDataReadData,
input wDataWriteEnable, /*写下游数据接口*/
output wDataWrite,
output [31:0] bDataWriteData
);
endmodule
/*
// 78B9BEC2-3DF7-4421-9274-645BFB60320B
DEFINE_GUID(<<name>>,
0x78b9bec2, 0x3df7, 0x4421, 0x92, 0x74, 0x64, 0x5b, 0xfb, 0x60, 0x32, 0xb);
*/
(*
HDL4SE="LCOM",
CLSID="78B9BEC2-3DF7-4421-9274-645BFB60320B",
softmodule="hdl4se"
*)
module hdl4se_cnn_innerproduct
#(parameter
INW=1, INH=1, INC=1024,
OUTW=1, OUTH=1, OUTC=1000
)
(
/*
inputsize[0] = HEIGHT;
inputsize[1] = WIDTH;
inputsize[2] = COMPONENT;
outputsize[0] = 1;
outputsize[1] = 1;
outputsize[2] = N;
*/
input wClk,
input nwReset,
output wCoeffRead, /* 系数读接口 */
input wCoeffReadValid,
output [31:0] bCoeffReadAddr,
input [31:0] bCoeffReadData,
input [31:0] bCoeffOffset,
input [31:0] bCoeffScale,
input [15:0] bCoeff_N,
input [15:0] bCoeff_C,
input [15:0] bCoeff_H,
input [15:0] bCoeff_W,
input [31:0] bCoeffBiasOffset,
input [31:0] bCoeffBiasScale,
input [15:0] bCoeffBias_N,
input [15:0] bCoeffBias_C,
input [15:0] bCoeffBias_H,
input [15:0] bCoeffBias_W,
output wDataRead,
input wDataReadValid,
input [31:0] bDataReadData,
input wDataWriteEnable, /* 写下游数据接口 */
output wDataWrite,
output [31:0] bDataWriteData
);
endmodule
/*
DEFINE_GUID(<<name>>,
0x8ec66cdf, 0xc750, 0x46a1, 0xaa, 0x1f, 0xc4, 0x43, 0x8, 0xe1, 0xf0, 0x1);
*/
(*
HDL4SE="LCOM",
CLSID="8EC66CDF-C750-46A1-AA1F-C44308E1F001",
softmodule="hdl4se"
*)
module hdl4se_cnn_concat4
#(parameter
INW0=128, INH0=64, INC0=1,
INW1=128, INH1=64, INC1=1,
INW2=128