SHELL中如何将txt文件导入到oracle中,在oracle中经过sql语句后如何将结果导出
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SHELL中如何将txt文件导入到oracle中,在oracle中经过sql语句后如何将结果导出相关的知识,希望对你有一定的参考价值。
请高手写一个实例或者找一个实例解释并注释一下
控制文件基本格式:LOAD DATA
INFILE 'T.DAT' // 要导入的数据文件(格式1)
INFILE 'TT.DAT' // 导入多个文件(可以和格式1并列使用)
APPEND INTO TABLE TABLE_NAME // 指定装入的表(这里有几种加载方式)
以下是4种装入表的方式
APPEND //原先的表有数据就加在后面
INSERT // 装载空表,如果原先的表有数据SQLLOADER会停止默认值
REPLACE // 原先的表有数据 原先的数据会全部删除
TRUNCATE // 指定的内容和REPLACE的相同 会用TRUNCATE语句删除
现存数据
BADFILE 'C:BAD.TXT' // 指定坏文件地址 ,也可不指定。
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
// 装载这种数据: "10","20","30","40","50"
TERMINATED BY X'09' // 以十六进制格式'09'表示文本文件用TAB键分隔
// 示例文本数据: "10" "20" "30" "40" "50"
TERMINATED BY WHITESPACE // 装载这种数据: "10" "lg" "lg"
TRAILING NULLCOLS //表的字段没有对应的值时允许为空
************* 下面是表的字段
(COL_1 , COL_2 ,COL_FILLER FILLER // FILLER 关键字 此列的数值不会被装载)
指定的TERMINATED可以在表的开头 也可在表的内部字段部分
当没声明FIELDS TERMINATED BY ',' 时也可以逐个字段来声明
(COL_1 [INTERGER EXTERNAL] TERMINATED BY ',' ,
COL_2 [DATE "DD-MON-YYY"] TERMINATED BY ',' ,
COL_3 [CHAR] TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' )
当没声明FIELDS TERMINATED BY ','用位置告诉字段装载数据
(COL_1 POSITION(1:2),
COL_2 POSITION(3:10),
COL_3 POSITION(*:16), // 这个字段的开始位置在前一字段的结束位置
COL_4 POSITION(3:10) CHAR(8), // 指定字段的类型
COL_5 POSITION(3:10) "TRIM(:COL_5)", // 挤压两端空格
COL_6 POSITION(3:10) "SEQ.NEXTVAL", // 取SEQUENCE值
BEGINDATA // 对应开始的 INFILE * 要导入的内容就在CONTROL文件里
10,20,30
20,30,40
//********************************************************************************//
CONTROL文件示例:
//注意BEGINDATA后的数值前面不能有空格
1 ***** 普通装载
LOAD DATA
INFILE *
REPLACE INTO TABLE DEPT
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
(DEPTNO,
DNAME,
LOC
)
BEGINDATA
10,SALES,"""USA"""
20,ACCOUNTING,"VIRGINIA,USA"
30,CONSULTING,VIRGINIA
40,FINANCE,VIRGINIA
50,"FINANCE","",VIRGINIA // LOC 列将为空
60,"FINANCE",,VIRGINIA // LOC 列将为空
2 ***** FIELDS TERMINATED BY WHITESPACE 和 FIELDS TERMINATED BY X'09' 的情况
LOAD DATA
INFILE *
REPLACE INTO TABLE DEPT
FIELDS TERMINATED BY WHITESPACE
-- FIELDS TERMINATED BY X'09'
(DEPTNO,
DNAME,
LOC
)
BEGINDATA
10 Sales Virginia
3 ***** 指定不装载那一列
LOAD DATA
INFILE *
REPLACE INTO TABLE DEPT
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
( DEPTNO,
FILLER_1 FILLER, // 下面的 "Something Not To Be Loaded" 将不会被装载
DNAME,
LOC
)
BEGINDATA
20,Something Not To Be Loaded,Accounting,"Virginia,USA"
4 ***** POSITION的列子
LOAD DATA
INFILE *
REPLACE INTO TABLE DEPT
( DEPTNO POSITION(1:2),
DNAME POSITION(*:16), // 这个字段的开始位置在前一字段的结束位置
LOC POSITION(*:29),
ENTIRE_LINE POSITION(1:29)
)
BEGINDATA
10ACCOUNTING VIRGINIA,USA
5 ***** 使用函数日期的一种表达 TRAILING NULLCOLS的使用
LOAD DATA
INFILE *
REPLACE INTO TABLE DEPT
FIELDS TERMINATED BY ','
TRAILING NULLCOLS // 其实下面的ENTIRE_LINE在BEGINDATA后面的数据中是没有直接对应
// 的列的值 如果第一行改为 10,Sales,Virginia,1/5/2000,, 就不用TRAILING NULLCOLS了
(DEPTNO,
DNAME "UPPER(NAME)", // 使用函数
LOC "UPPER(:LOC)",
LAST_UPDATED DATE 'DD/MM/YYYY', // 日期的一种表达方式 还有'DD-MON-YYYY' 等
ENTIRE_LINE "EPTNO||NAME||:LOC||:LAST_UPDATED"
)
BEGINDATA
10,Sales,Virginia,1/5/2000
20,Accounting,Virginia,21/6/1999
30,Consulting,Virginia,5/1/2000
40,Finance,Virginia,15/3/2001
6 ***** 使用自定义的函数 // 解决的时间问题
CREATE OR REPLACE
FUNCTION MY_TO_DATE( P_STRING IN VARCHAR2 ) RETURN DATE
AS
TYPE FMTARRAY IS TABLE OF VARCHAR2(25);
L_FMTS FMTARRAY := FMTARRAY( 'DD-MON-YYYY', 'DD-MONTH-YYYY',
'DD/MM/YYYY',
'DD/MM/YYYY HH24:MI:SS' );
L_RETURN DATE;
BEGIN
FOR I IN 1 .. L_FMTS.COUNT
LOOP
BEGIN
L_RETURN := TO_DATE( P_STRING, L_FMTS(I) );
EXCEPTION
WHEN OTHERS THEN NULL;
END;
EXIT WHEN L_RETURN IS NOT NULL;
END LOOP;
IF ( L_RETURN IS NULL )
THEN
L_RETURN :=
NEW_TIME( TO_DATE('01011970','DDMMYYYY') + 1/24/60/60 *
P_STRING, 'GMT', 'EST' );
END IF;
RETURN L_RETURN;
END;
/
LOAD DATA
INFILE *
REPLACE INTO TABLE DEPT
FIELDS TERMINATED BY ','
TRAILING NULLCOLS
(DEPTNO,
DNAME "UPPER(NAME)",
LOC "UPPER(:LOC)",
LAST_UPDATED "MY_TO_DATE( :LAST_UPDATED )" // 使用自定义的函数
)
BEGINDATA
10,Sales,Virginia,01-april-2001
20,Accounting,Virginia,13/04/2001
30,Consulting,Virginia,14/04/2001 12:02:02
40,Finance,Virginia,987268297
50,Finance,Virginia,02-apr-2001
60,Finance,Virginia,Not a date
7 ***** 合并多行记录为一行记录
LOAD DATA
INFILE *
CONCATENATE 3 // 通过关键字CONCATENATE 把几行的记录看成一行记录
INTO TABLE DEPT
REPLACE //注意这个例子格式与前边有些不同
FIELDS TERMINATED BY ','
(DEPTNO,
DNAME "UPPER(NAME)",
LOC "UPPER(:LOC)",
LAST_UPDATED DATE 'DD/MM/YYYY'
)
BEGINDATA
10,Sales, // 其实这3行看成一行 10,Sales,Virginia,1/5/2000
Virginia,
1/5/2000
// 这列子用 CONTINUEIF LIST="," 也可以
告诉SQLLDR在每行的末尾找逗号 找到逗号就把下一行附加到上一行
LOAD DATA
INFILE *
CONTINUEIF THIS(1:1) = '-' // 找每行的开始是否有连接字符 - 有就把下一行连接为一行
// 如 -10,Sales,Virginia,
// 1/5/2000 就是一行 10,Sales,Virginia,1/5/2000
// 其中1:1 表示从第一行开始 并在第一行结束 还有CONTINUEIF NEXT 但CONTINUEIF LIST最理想
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ','
(DEPTNO,
DNAME "upper(:dname)",
LOC "upper(:loc)",
LAST_UPDATED date 'dd/mm/yyyy'
)
BEGINDATA // 但是好象不能象右面的那样使用
-10,Sales,Virginia, -10,Sales,Virginia,
1/5/2000 1/5/2000
-40, 40,Finance,Virginia,13/04/2001
Finance,Virginia,13/04/2001
8 ***** 载入每行的行号
LOAD DATA
INFILE *
INTO TABLE T
REPLACE
( SEQNO RECNUM //载入每行的行号
TEXT POSITION(1:1024))
BEGINDATA
fsdfasj //自动分配一行号给载入 表t 的seqno字段 此行为 1
fasdjfasdfl // 此行为 2 ...
9 ***** 载入有换行符的数据
注意: UNIX 和 WINDOWS 不同 n & /n
< 1 > 使用一个非换行符的字符
LOAD DATA
INFILE *
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ','
TRAILING NULLCOLS
(DEPTNO,
DNAME "UPPER(NAME)",
LOC "UPPER(:LOC)",
LAST_UPDATED "MY_TO_DATE( :LAST_UPDATED )",
COMMENTS "REPLACE(:COMMENTS,'N',CHR(10))" // REPLACE 的使用帮助转换换行符
)
BEGINDATA
10,Sales,Virginia,01-april-2001,This is the SalesnOffice in Virginia
20,Accounting,Virginia,13/04/2001,This is the AccountingnOffice in Virginia
30,Consulting,Virginia,14/04/2001 12:02:02,This is the ConsultingnOffice in Virginia
40,Finance,Virginia,987268297,This is the FinancenOffice in Virginia
< 2 > 使用fix属性
LOAD DATA
INFILE DEMO17.DAT "FIX 101"
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ','
TRAILING NULLCOLS
(DEPTNO,
DNAME "UPPER(NAME)",
LOC "UPPER(:LOC)",
LAST_UPDATED "MY_TO_DATE( :LAST_UPDATED )",
COMMENTS
)
BEGINDATA
10,Sales,Virginia,01-april-2001,This is the Sales
Office in Virginia
20,Accounting,Virginia,13/04/2001,This is the Accounting
Office in Virginia
30,Consulting,Virginia,14/04/2001 12:02:02,This is the Consulting
Office in Virginia
40,Finance,Virginia,987268297,This is the Finance
Office in Virginia
// 这样装载会把换行符装入数据库,下面的方法就不会,但要求数据的格式不同
LOAD DATA
INFILE DEMO18.DAT "FIX 101"
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
TRAILING NULLCOLS
(DEPTNO,
DNAME "UPPER(NAME)",
LOC "UPPER(:LOC)",
LAST_UPDATED "MY_TO_DATE( :LAST_UPDATED )",
COMMENTS
)
BEGINDATA
10,Sales,Virginia,01-april-2001,"This is the Sales
Office in Virginia"
20,Accounting,Virginia,13/04/2001,"This is the Accounting
Office in Virginia"
30,Consulting,Virginia,14/04/2001 12:02:02,"This is the Consulting
Office in Virginia"
40,Finance,Virginia,987268297,"This is the Finance
Office in Virginia"
< 3 > 使用var属性
LOAD DATA
INFILE DEMO19.DAT "VAR 3"
// 3 告诉每个记录的前3个字节表示记录的长度 如第一个记录的 071 表示此记录有 71 个字节
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ','
TRAILING NULLCOLS
(DEPTNO,
DNAME "UPPER(NAME)",
LOC "UPPER(:LOC)",
LAST_UPDATED "MY_TO_DATE( :LAST_UPDATED )",
COMMENTS
)
BEGINDATA
07110,Sales,Virginia,01-april-2001,This is the Sales
Office in Virginia
07820,Accounting,Virginia,13/04/2001,This is the Accounting
Office in Virginia
08730,Consulting,Virginia,14/04/2001 12:02:02,This is the Consulting
Office in Virginia
07140,Finance,Virginia,987268297,This is the Finance
Office in Virginia
< 4 > 使用STR属性
// 最灵活的一中 可定义一个新的行结尾符 WIN 回车换行 : CHR(13)||CHR(10)
此列中记录是以 A|RN 结束的
SELECT UTL_RAW.CAST_TO_RAW('|'||CHR(13)||CHR(10)) FROM DUAL;
结果 7C0D0A
LOAD DATA
INFILE DEMO20.DAT "STR X'7C0D0A'"
INTO TABLE DEPT
REPLACE
FIELDS TERMINATED BY ','
TRAILING NULLCOLS
(DEPTNO,
DNAME "UPPER(NAME)",
LOC "UPPER(:LOC)",
LAST_UPDATED "MY_TO_DATE( :LAST_UPDATED )",
COMMENTS
)
BEGINDATA
10,Sales,Virginia,01-april-2001,This is the Sales
Office in Virginia|
20,Accounting,Virginia,13/04/2001,This is the Accounting
Office in Virginia|
30,Consulting,Virginia,14/04/2001 12:02:02,This is the Consulting
Office in Virginia|
40,Finance,Virginia,987268297,This is the Finance
Office in Virginia|
10 *****象这样的数据 用 nullif 子句
10-jan-200002350Flipper seemed unusually hungry today.
10510-jan-200009945Spread over three meals.
ID POSITION(1:3) NULLIF ID=BLANKS // 这里可以是BLANKS 或者别的表达式
// 下面是另一个列子 第一行的 1 在数据库中将成为 NULL
LOAD DATA
INFILE *
INTO TABLE T
REPLACE
(N POSITION(1:2) INTEGER EXTERNAL NULLIF N='1',
V POSITION(3:8)
)
BEGINDATA
1 10
20lg
//********************************************************************************//
SQLLOADER的命令:
SQLLDR USERID=SYS/SYS@DB_SERVICE CONTROL=XXXX.CTL LOG=XXXX.LOG BINDSIZE=1048576 ROWS=100
ERRORS=10000 READSIZE=2097152 SILENT=(HEADER,FEEDBACK)
关于这些参数的帮助在命令行直接执行SQLLDR可以得到,这里指出BINDSIZE不应该大于READSIZE的值。
关于SPOOL导出文本数据的一些格式建议:
SQL*PLUS环境设置SET NEWPAGE NONE HEADING OFF SPACE 0 PAGESIZE 0 TRIMOUT ON TRIMSPOOL ON LINESIZE 2500
注:LINESIZE要稍微设置大些,免得数据被截断,它应和相应的TRIMSPOOL结合使用防止导出的文本有太多的尾部空格。
但是如果LINESIZE设置太大,会大大降低导出的速度,另外在WINDOWS下导出最好不要用PLSQL导出,速度比较慢,
直接用COMMEND下的SQLPLUS命令最小化窗口执行。
对于SPOOL数据的SQL,最好要自己定义格式,以方便我们的导入,如例子如下:
SELECT
JBSJ.JSJDM||CHR(9)||
JBSJ.ZZJGDM||CHR(9)||
JBSJ.YYZZH||CHR(9)||
REPLACE(REPLACE(JBSJ.NSRMC,CHR(10)),CHR(13))||CHR(9)||
QYRY.ZJLXDM||CHR(9)||
REPLACE(REPLACE(QYRY.ZJHM,CHR(10)),CHR(13))||CHR(9)||
REPLACE(REPLACE(QYRY.XM,CHR(10)),CHR(13))||CHR(9)||
REPLACE(REPLACE(JBSJ.ZCDZ,CHR(10)),CHR(13))||CHR(9)||
REPLACE(REPLACE(JBSJ.JYDZ,CHR(10)),CHR(13))||CHR(9)||
REPLACE(REPLACE(JBSJ.JYFW,CHR(10)),CHR(13))||CHR(9)||
REPLACE(REPLACE(JBSJ.JYDZYB,CHR(10)),CHR(13))||CHR(9)||
ZCLX.DJZCLXDM||CHR(9)||
TO_CHAR(JBSJ.KYDJRQ,'YYYY-MM-DD')||CHR(9)||
JBSJ.SWJGZZJGDM||CHR(9)||
REPLACE(REPLACE(SWJGZZJG.SWJGZZJGMC,CHR(10)),CHR(13))||CHR(9)||
JBSJ.ZCZBJE||CHR(9)||
JBSJ.NSRZT||CHR(9)||
NSRZT.NSRZTMC
FROM DJDB.DJ_JL_JBSJ JBSJ,
DJDB.DJ_JL_QYRY QYRY,
DMDB.GY_DM_SWJGZZJG SWJGZZJG,
DMDB.DJ_DM_DJZCLX ZCLX,
DMDB.DJ_DM_NSRZT NSRZT
WHERE JBSJ.DJZCLXDM=ZCLX.DJZCLXDM
AND JBSJ.JSJDM=QYRY.JSJDM
AND QYRY.ZWDM='01'
AND JBSJ.SWJGZZJGDM=SWJGZZJG.SWJGZZJGDM
AND JBSJ.NSRZT=NSRZT.NSRZTDM
AND JBSJ.NSRZT!=90
AND JBSJ.KYDJRQ < TO_DATE('20040701','YYYYMMDD')
对于字段内包含很多回车换行符的应该给与过滤,形成比较规矩的文本文件。
通常情况下,我们使用SPOOL方法,将数据库中的表导出为文本文件的时候会采用两种方法,如下述:
方法一:采用以下格式脚本
set colsep '' ------设置列分隔符
set trimspool on
set linesize 120
set pagesize 2000
set newpage 1
set heading off
set term off
spool 路径+文件名
select * from tablename;
spool off
方法二:采用以下脚本
set trimspool on
set linesize 120
set pagesize 2000
set newpage 1
set heading off
set term off
spool 路径+文件名
select col1||','||col2||','||col3||','||col4||'..' from tablename;
spool off
比较以上方法,即方法一采用设定分隔符然后由sqlplus自己使用设定的分隔符对字段进行分割,方法二将分隔符拼接在SELECT语句中,即手工控制输出格式。
在实践中,我发现通过方法一导出来的数据具有很大的不确定性,这种方法导出来的数据再由sql ldr导入的时候出错的可能性在95%以上,尤其对大批量的数据表,如100万条记录的表更是如此,而且导出的数据文件狂大。
而方法二导出的数据文件格式很规整,数据文件的大小可能是方法一的1/4左右。经这种方法导出来的数据文件再由sqlldr导入时,出错的可能性很小,基本都可以导入成功。
因此,实践中我建议大家使用方法二手工去控制spool文件的格式,这样可以减小出错的可能性,避免走很多弯路。 参考技术A Oracle 通过运行 sqlldr 程序来完成大容量导入操作。
Oracle 大容量导入操作
http://hi.baidu.com/wangzhiqing999/blog/item/1f65dbff3c734070024f5646.html
Oracle 大容量导入操作 II
http://hi.baidu.com/wangzhiqing999/blog/item/224f2c3533c3dfbc5fdf0e43.html
Oracle 大容量导入操作 III - 使用外部表
http://hi.baidu.com/wangzhiqing999/blog/item/2879207af090892c0cd7daf0.html追问
问下*.ctl文件是系统自带的还是需要自己去建立一个稳定以ctl结尾
追答*.ctl文件 是你自己创建的啊.
一个文本格式的文件.
用来 告诉 Oracle , 我这个 txt 数据文件里面。 数据是如何组织的。
也就是你的 txt 文件的格式信息。
如何将xls的资料导入到oracle数据库中
参考技术A操作步骤如下:
准备数据:在excel中构造出需要的数据

2.将excel中的数据另存为文本文件(有制表符分隔的)

3.将新保存到文本文件中的数据导入到pl*sql中
在pl*sql中选择tools-->text importer,在出现的窗口中选择"Data from Textfile",然后再选择"Open data file",

在弹出的文件选择框中选中保存有数据的文本文件,此时将会看到data from textfile中显示将要导入的数据

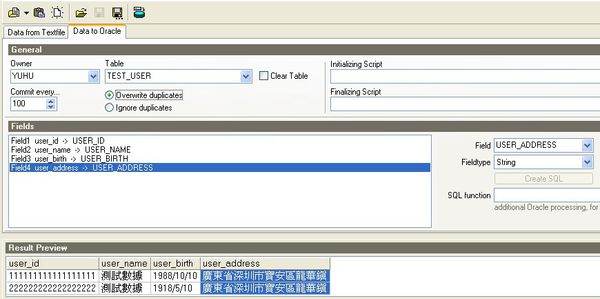
4.在configuration中进行如下配置

注:如果不将"Name in header"勾选上会导致字段名也当做记录被导入到数据库中,从而导致数据错误
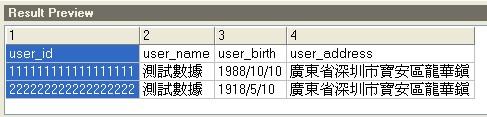
5.点击data to oracle,选择将要导入数据的表,并在fields中将文本中的字段与表中的字段进行关联
6.点击import按钮进行导入

7.查看导入的数据
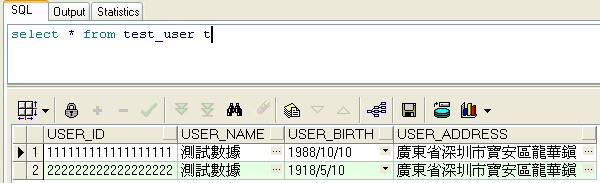
OK,至此数据导入成功。
以上是关于SHELL中如何将txt文件导入到oracle中,在oracle中经过sql语句后如何将结果导出的主要内容,如果未能解决你的问题,请参考以下文章
关于shell脚本如何批量将一个文件夹下面的所有文件都更改为.TXT后缀