hadoop包安装
Posted kevin&learn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop包安装相关的知识,希望对你有一定的参考价值。
高可用集群搭建
创建hadoop账户
-
创建hadoop账户(#注意,接下来的操作均在hadoop账户下运行)
# useradd hadoop # passwd hadoop
su - hadoop
mkdir soft disk1 disk2
mkdir -p disk{1,2}/dfs/{dn,nn}
mkdir -p disk{1,2}/nodemgr/local - 将本地目录下的hadoop-2.6.0-cdh5.5.0.tar.gz,上传到虚拟机的/home/hadoop/soft目录下,并且更改名字。
1 tar -xzvf hadoop-2.6.0-cdh5.50 2 mv hadoop-2.6.0-cdh5.50 hadoop
- 配置hadoop的环境变量
1 vim ~/.bashrc 2 export HADOOP_HOME=/home/hadoop/soft/hadoop 3 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH 4 source ~/.bashrc
- 进入/home/hadoop/soft/hadoop/etc/hadoop修改配置文件
修改core-site.xml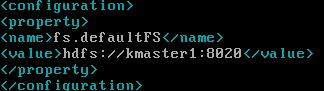
修改hdfs-site.xml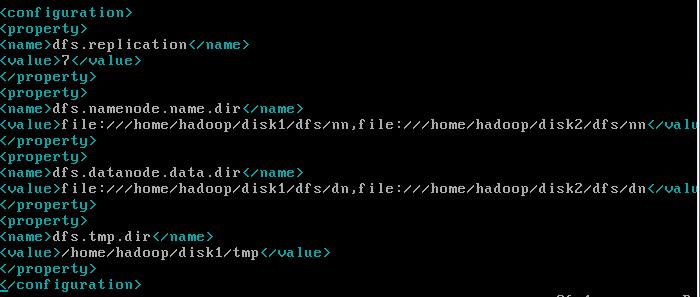
修改mapred-site.xml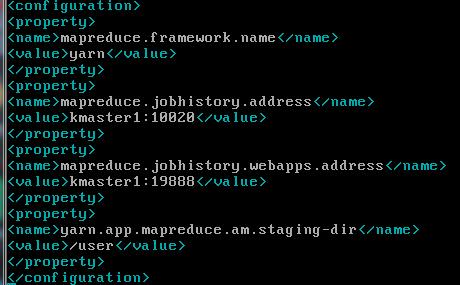
修改yarn-site.xml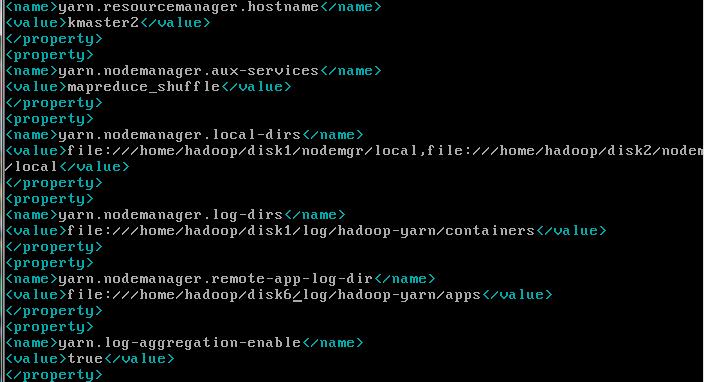
修改环境变量(下面有文字版)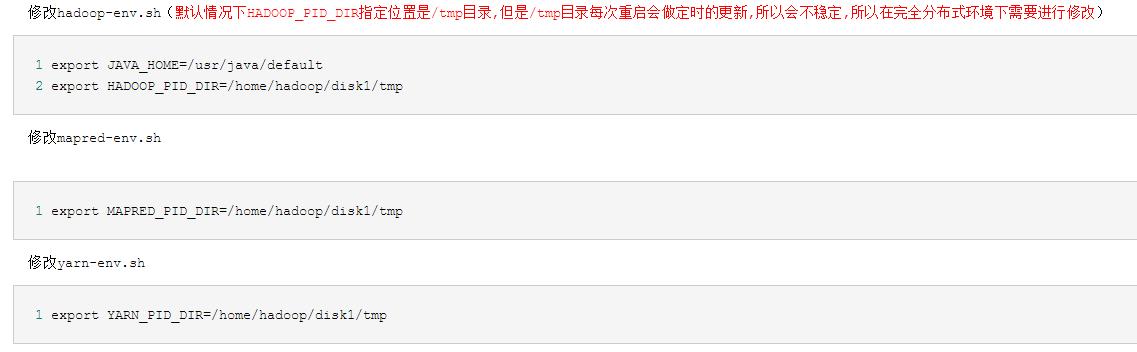
增加hadoop环境变量
vim ~/.bashrc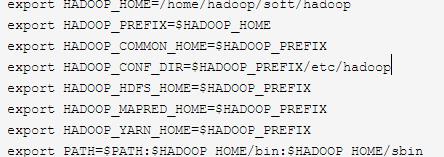
- 格式化namenode
hdfs namenode -format
- 启动start-all.sh启动全部服务,或者可以分别启动(start-dfs.sh,start-yarn.sh)/(hadoop-daemon.sh)
- 启动之后可以通过jps查看当前开启的服务以及netstat -tnlp查询端口信息(或者可以在windows下通过登录xxx:50070和xxx:8088查看)
高可用的搭建
- 将所有的服务全部关掉。
- 开启zookeeper(配置安装请参考zookeeper安装)
- 在kslave5,kslave6,kslave7上执行
cd mkdir disk1/dfs/jn -
进入/home/hadoop/soft/hadoop/etc/hadoop修改配置文件
修改core-site.xml
1 <configuration> 2 <property>
<!-- 1.HDFS的访问入口--> 3 <name>fs.defaultFS</name> 4 <value>hdfs://kcluster</value> 5 </property> 6 <property>
<!-- 2.zookeeper集群地址--> 7 <name>ha.zookeeper.quorum</name> 8 <value>kslave5:2181,kslave6:2181,kslave7:2181</value> 9 </property> 10 </configuration>修改hdfs-site.xml
1 <configuration> 2 <property> 3 <!-- 1.集群复制因子--> 4 <name>dfs.replication</name> 5 <value>7</value> 6 </property> 7 <property> 8 <!-- 2.namenode数据存放地址,两个地址是为了安全--> 9 <name>dfs.namenode.name.dir</name> 10 <value>file:///home/hadoop/disk1/dfs/nn,file:///home/hadoop/disk2/dfs/nn</value> 11 </property> 12 <property> 13 <!-- 3.datanode是数据块的存放地址,两个地址是为了传输数据的速度 --> 14 <name>dfs.datanode.data.dir</name> 15 <value>file:///home/hadoop/disk1/dfs/dn,file:///home/hadoop/disk2/dfs/dn</value> 16 </property> 17 <property> 18 <!-- 4.hdfs临时文件存放目录--> 19 <name>dfs.tmp.dir</name> 20 <value>/home/hadoop/disk1/tmp</value> 21 </property> 22 <property> 23 <!-- 5.集群名字--> 24 <name>dfs.nameservices</name> 25 <value>kcluster</value> 26 </property> 27 <property> 28 <!-- 6.namenode的列表成员别名--> 29 <name>dfs.ha.namenodes.kcluster</name> 30 <value>kma1,kma2</value> 31 </property> 32 <property> 33 <!-- 7.namenode的主机通信地址--> 34 <name>dfs.namenode.rpc-address.kcluster.kma1</name> 35 <value>kmaster1:8020</value> 36 </property> 37 <property> 38 <name>dfs.namenode.rpc-address.kcluster.kma2</name> 39 <value>kmaster2:8020</value> 40 </property> 41 <property> 42 <!-- 8.namenode的主机的http通信地址--> 43 <name>dfs.namenode.http-address.kcluster.kma1</name> 44 <value>kmaster1:50070</value> 45 </property> 46 <property> 47 <name>dfs.namenode.http-address.kcluster.kma2</name> 48 <value>kmaster2:50070</value> 49 </property> 50 <property> 51 <!-- 9.JournalNodes主机列表--> 52 <name>dfs.namenode.shared.edits.dir</name> 53 <value>qjournal://kslave5:8485;kslave6:8485;kslave7:8485/kcluster</value> 54 </property> 55 <property> 56 <!-- 10.JournalNodes保存日志和集群操作状态的目录--> 57 <name>dfs.journalnode.edits.dir</name> 58 <value>/home/hadoop/disk1/dfs/jn</value> 59 </property> 60 <property> 61 <!-- 11.java 的类名,用来激活namenode--> 62 <name>dfs.client.failover.proxy.provider.kcluster</name> 63 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> 64 </property> 65 <property> 66 <!-- 12.Namenode和Zookeeper用来隔离失效节点的方式--> 67 <name>dfs.ha.fencing.methods</name> 68 <value>shell(/bin/true)</value> 69 </property> 70 <property> 71 <!-- 13.是否激活namenode失效自动切换--> 72 <name>dfs.ha.automatic-failover.enabled</name> 73 <value>true</value> 74 </property> 75 </configuration>
修改mapred-site.xml
1 <configuration> 2 <property> 3 <!-- 1.分配 mapreduce 框架--> 4 <name>mapreduce.framework.name</name> 5 <value>yarn</value> 6 </property> 7 <property> 8 <!-- 2.historyserver 地址--> 9 <name>mapreduce.jobhistory.address</name> 10 <value>kmaster1:10020</value> 11 </property> 12 <property> 13 <!-- 3.historyserver Web端口--> 14 <name>mapreduce.jobhistory.webapps.address</name> 15 <value>kmaster1:19888</value> 16 </property> 17 <property> 18 <!-- 4.yarn任务的临时输出目录--> 19 <name>yarn.app.mapreduce.am.staging-dir</name> 20 <value>/user</value> 21 </property> 22 </configuration>
修改yarn-site.xml
<configuration> <property> <!-- 1.开始yarn的高可用--> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <!-- 2.指定RM的cluster id--> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-ha</value> </property> <property> <!-- 3.指定开启高可用的RM别名--> <name>yarn.resourcemanager.ha.rm-ids</name> <value>krm1,krm2</value> </property> <property> <!-- 4.分别指定RM的地址--> <name>yarn.resourcemanager.hostname.krm1</name> <value>kmaster1</value> </property> <property> <name>yarn.resourcemanager.hostname.krm2</name> <value>kmaster2</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <!-- 5.指定zookeeper的地址--> <name>yarn.resourcemanager.zk-address</name> <value>kslave5:2181,kslave6:2181,kslave7:2181</value> </property> <property> <!-- 6.为 mapreduce 分配 yarn 服务--> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <!-- 7.nodemanager 本机计算任务的临时文件--> <name>yarn.nodemanager.local-dirs</name> <value>file:///home/hadoop/disk1/nodemgr/local,file:///home/hadoop/disk2/nodemgr/local</value> </property> <property> <!-- 8.nodemanager 日志输出--> <name>yarn.nodemanager.log-dirs</name> <value>file:///home/hadoop/disk1/log/hadoop-yarn/containers</value> </property> <property> <!-- 9.远程任务的输出--> <name>yarn.nodemanager.remote-app-log-dir</name> <value>file:///home/hadoop/disk1/log/hadoop-yarn/apps</value> </property> <property> <!-- 10.日志汇集--> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> </configuration>
修改hadoop-env.sh(默认情况下HADOOP_PID_DIR指定位置是/tmp目录,但是/tmp目录每次重启会做定时的更新,所以会不稳定,所以在完全分布式环境下需要进行修改)1 export JAVA_HOME=/usr/java/default 2 export HADOOP_PID_DIR=/home/hadoop/disk1/tmp
修改mapred-env.sh
1 export MAPRED_PID_DIR=/home/hadoop/disk1/tmp修改yarn-env.sh
1 export YARN_PID_DIR=/home/hadoop/disk1/tmp配置hadoop环境变量(将接下来集群需要的zookeeper和hbase的环境变量都加好了)
1 vim ~/.bashrc 2 export HADOOP_HOME=/home/hadoop/soft/hadoop 3 export HADOOP_PREFIX=$HADOOP_HOME 4 export HADOOP_COMMON_HOME=$HADOOP_PREFIX 5 export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop 6 export HADOOP_HDFS_HOME=$HADOOP_PREFIX 7 export HADOOP_MAPRED_HOME=$HADOOP_PREFIX 8 export HADOOP_YARN_HOME=$HADOOP_PREFIX 9 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin 10 export ZOOKEEPER_HOME=/home/hadoop/soft/zk 11 export PATH=$PATH:$ZOOKEEPER_HOME/bin 12 export HBASE_HOME=/home/hadoop/soft/hbase 13 export PATH=$PATH:$HBASE_HOME/bin
- 开启journalnode(日志服务器)
1 hadoop-daemon.sh start journalnode - 初始化原来的namenode:
1 # 初始化edits目录 2 hdfs namenode -initializeSharedEdits 3 # 重新启动namenode 4 hadoop-daemon.sh start namenode 5 # 查看namenode状态 6 hdfs haadmin -getServiceState kma1
- 初始化现在的namenode:
1 hdfs namenode -bootstrapStandby 2 # 启动第二台 namenode 3hadoop-daemon.sh start namenode
4 # 查看状态
5 hdfs haadmin -getServiceState kma2 - 格式化zookeeper控制器,选择一台namenode格式操作:
1 hdfs zkfc -formatZK再次查看namenode状态
hdfs haadmin -getServiceState kma1
active
hdfs haadmin -getServiceState kma2
standby
查看到一个namenode(active),另一个namenode(standby)。接下来,开启其余节点上的服务,均正常运行。至此,HA集群搭建完毕。
以上是关于hadoop包安装的主要内容,如果未能解决你的问题,请参考以下文章