Redis持久化之RDB
Posted QIANQIANCHEN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis持久化之RDB相关的知识,希望对你有一定的参考价值。
一、 RDB Redis DataBase
The RDB persistence performs point-in-time snapshots of your dataset at specified intervals.
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
二、备份是如何执行的?
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件,不是在原来的文件上做增量,而是全部备份。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
- RDB的缺点是最后一次持久化后的数据可能丢失。 有时间间隔,服务器down了,有可能丢失,单机down了一定会丢失数据
三、 关于fork (分叉;分歧)
在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,Linux中引入了“写时复制技术”,一般情况父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进写磁盘、fork时对内存的压力很大,性能杀器。
联系gitHub中的fork
Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
四、配置文件snapshotting看rdb设置
rdb的保存策略
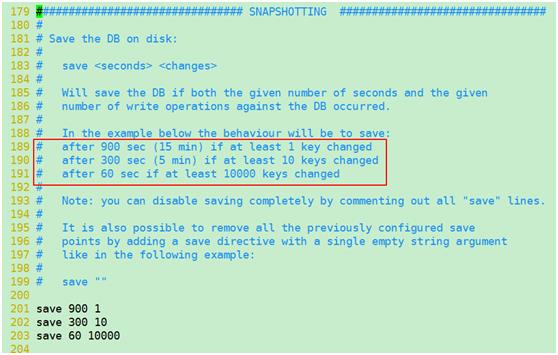
RDB是整个内存的压缩过的Snapshot,RDB的数据结构,可以配置复合的快照触发条件,默认
是1分钟内改了1万次,
或5分钟内改了10次,
或15分钟内改了1次
禁用:如果想禁用RDB持久化的策略,只要不设置任何save指令,或者给save传入一个空字符串参数也可以
动态所有停止RDB保存规则的方法:redis-cli config set save ""
四、 如何触发RDB快照
1、 配置文件中默认的快照配置

在redis.conf中配置文件名称,默认为dump.rdb
2、命令save vs bgsave
save: 只管保存,占主进程,其它不管,以后的操作全部阻塞,性能杀器
BGSAVE:Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。可以通过lastsave命令获取最后一次成功执行快照的时间background后台存储
3、执行flushall命令,也会产生dump.rdb文件,但里面是空的,无意义
rdb的保存的文件
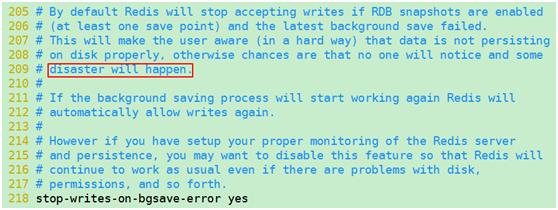
当Redis无法写入磁盘的话,直接关掉Redis的写操作,
如果没有设置,容易导致数据一致性问题,后台报错不及时修改容易出现灾难disaster
事故案例:小型机磁盘清理,备份数据时后台报错,实际没有备份成功造成数据丢失

进行rdb保存时,将文件压缩,但是会占CPU
对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用
LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能

在存储快照后,还可以让Redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能

rdb文件的保存路径,也可以修改。默认为Redis启动时命令行所在的目录下
五、 rdb的备份和恢复
备份:先通过config get dir 查询rdb文件的目录,将*.rdb的文件拷贝到别的地方
恢复:先关闭Redis,把备份的文件拷贝到工作目录上,
启动Redis,备份数据会自动加载
六、 Rdb 小总结
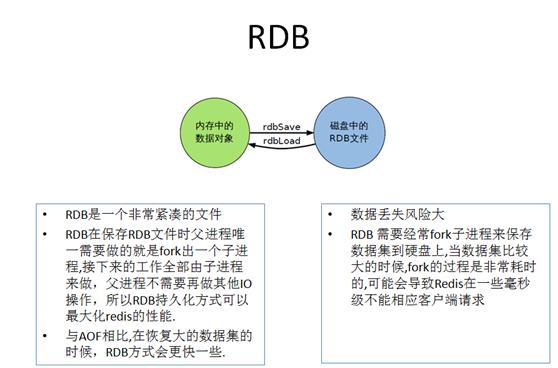
优点:节省磁盘空间
恢复速度快,就是一个镜像,适合大规模的数据恢复
对数据完整性和一致性要求不高
缺点:
- 在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
- 虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是会占用cpu性能。
Redis Persistence
Redis provides a different range of persistence options:
- The RDB persistence performs point-in-time snapshots of your dataset at specified intervals.
- the AOF persistence logs every write operation received by the server, that will be played again at server startup, reconstructing the original dataset. Commands are logged using the same format as the Redis protocol itself, in an append-only fashion. Redis is able to rewrite the log on background when it gets too big.
- If you wish, you can disable persistence at all, if you want your data to just exist as long as the server is running.
- It is possible to combine both AOF and RDB in the same instance. Notice that, in this case, when Redis restarts the AOF file will be used to reconstruct the original dataset since it is guaranteed to be the most complete.
The most important thing to understand is the different trade-offs between the RDB and AOF persistence. Let\'s start with RDB:
RDB advantages
- RDB is a very compact single-file point-in-time representation of your Redis data. RDB files are perfect for backups. For instance you may want to archive your RDB files every hour for the latest 24 hours, and to save an RDB snapshot every day for 30 days. This allows you to easily restore different versions of the data set in case of disasters.
- RDB is very good for disaster recovery, being a single compact file can be transferred to far data centers, or on Amazon S3 (possibly encrypted).
- RDB maximizes Redis performances since the only work the Redis parent process needs to do in order to persist is forking a child that will do all the rest. The parent instance will never perform disk I/O or alike.
- RDB allows faster restarts with big datasets compared to AOF.
RDB disadvantages
- RDB is NOT good if you need to minimize the chance of data loss in case Redis stops working (for example after a power outage). You can configure different save points where an RDB is produced (for instance after at least five minutes and 100 writes against the data set, but you can have multiple save points). However you\'ll usually create an RDB snapshot every five minutes or more, so in case of Redis stopping working without a correct shutdown for any reason you should be prepared to lose the latest minutes of data.
- RDB needs to fork() often in order to persist on disk using a child process. Fork() can be time consuming if the dataset is big, and may result in Redis to stop serving clients for some millisecond or even for one second if the dataset is very big and the CPU performance not great. AOF also needs to fork() but you can tune how often you want to rewrite your logs without any trade-off on durability.
http://redis.io/topics/persistence
以上是关于Redis持久化之RDB的主要内容,如果未能解决你的问题,请参考以下文章