UnityLOD Group- 关于性能优化中LOD的使用与总结
Posted CoderZ1010
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了UnityLOD Group- 关于性能优化中LOD的使用与总结相关的知识,希望对你有一定的参考价值。
LOD是性能优化中常考虑的一项内容,本文分为以下部分介绍LOD的相关内容:
目录
一、什么是LOD:
LOD技术(level of detail)被称作多层次细节,它的原理是模型物体在场景中根据距离相机的远近来显示不同细节程度的模型,距离渐近时,显示细节程度较高的模型,距离渐远时,显示细节程度较低的模型,从而节省性能的开销。
二、LOD如何使用:
Unity中通过LOD Group组件来实现LOD,如图所示的集装箱模型,我们准备了四个不同细节程度的Mesh网格:

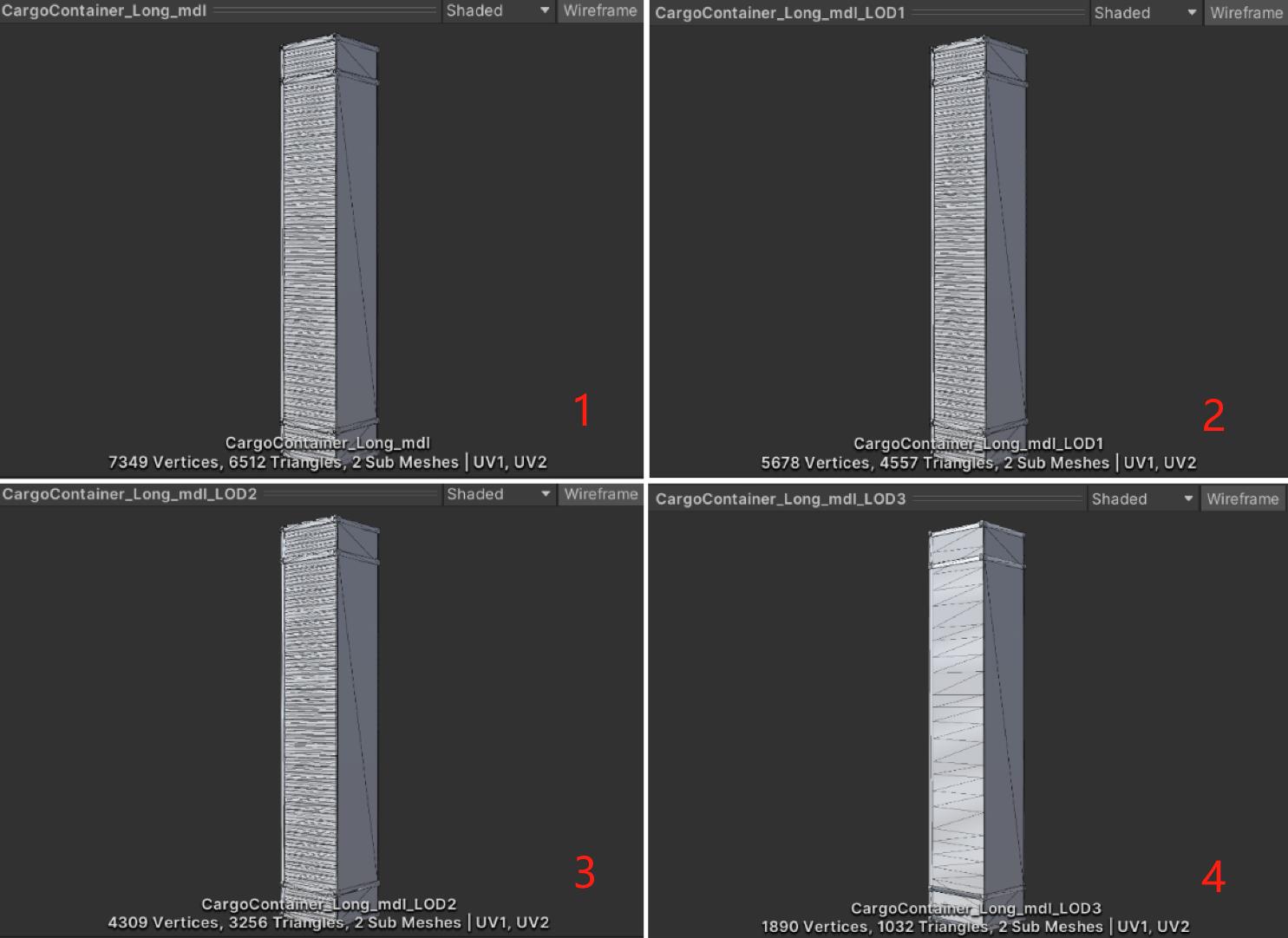
新建一个空物体,添加LOD Group组件,默认是分为3个层次,最后的Culled层是指的剔除层,不会渲染任何模型:
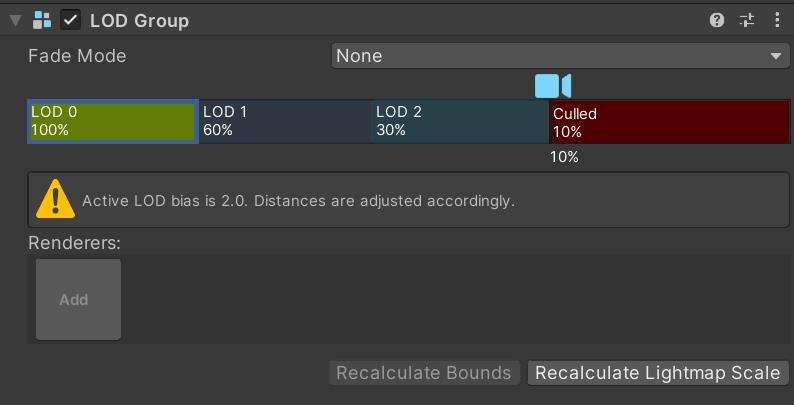
这里我们需要四个层次,通过选中一个层次右键/Insert Before插入一个:
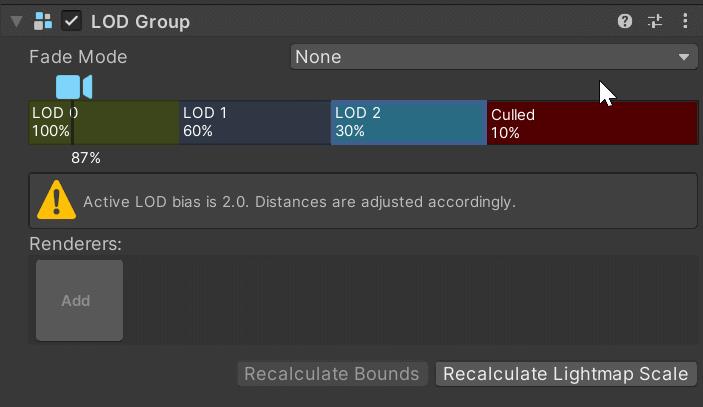
通过Add来添加不同层次要渲染的Mesh网格:
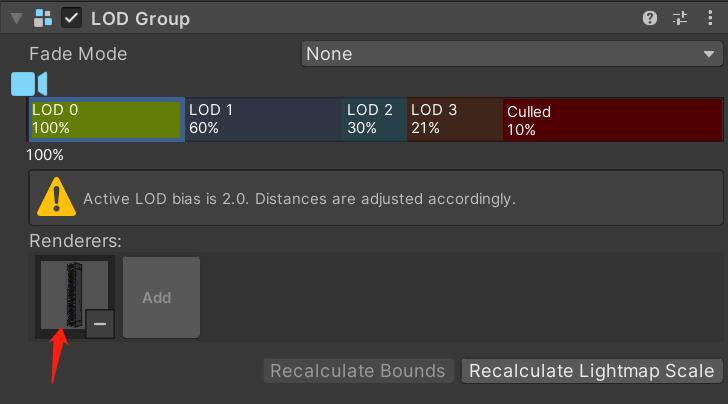
添加完成后在场景中进行预览:
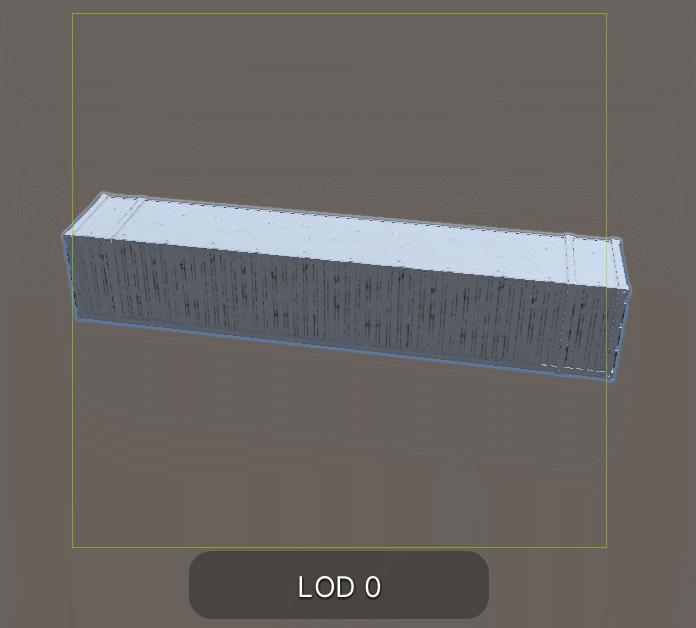
除了在Inspector检视面板设置LOD外,在代码中也可以进行设置,LOD Group类中提供了SetLODs函数:
//
// 摘要:
// Set the LODs for the LOD group. This will remove any existing LODs configured
// on the LODGroup.
//
// 参数:
// lods:
// The LODs to use for this group.
[MethodImpl(MethodImplOptions.InternalCall)]
[FreeFunction("SetLODs_Binding", HasExplicitThis = true)]
public extern void SetLODs(LOD[] lods);测试代码:
using UnityEngine;
public class LODExample : MonoBehaviour
private void Start()
LODGroup group = gameObject.AddComponent<LODGroup>();
LOD[] lods = new LOD[4];
for (int i = 0; i < lods.Length; i++)
lods[i] = new LOD(1 - (i + 1) * .2f, new Renderer[] transform.GetChild(i).GetComponent<Renderer>() );
group.SetLODs(lods);
group.RecalculateBounds();
三、使用LOD的弊端:
弊端也是显而易见的,首先是增加建模同事的工作量,要准备不同细节程度的模型,当然有很多自动减面的插件,例如资源商店中的Mesh Simplify插件,但是程序减面多多少少会破坏模型的原有外观,最理想的情况还是建模人员手动减面。另外,大量的模型文件不但会增加包体的大小,而且在运行时会大量增加内存消耗,因此对于LOD有一句空间换取时间的评价,当然最终是否采用LOD技术要根据具体情况而定,性能优化无非是CPU、GPU与内存之间的取舍。

四、使用LOD的注意事项:
只有最高层次细节的模型才会参与静态光照的烘焙,如图所示,当集装箱物体上的LOD0过渡到LOD1时会变黑,因为LOD1没有参与静态光照烘焙。
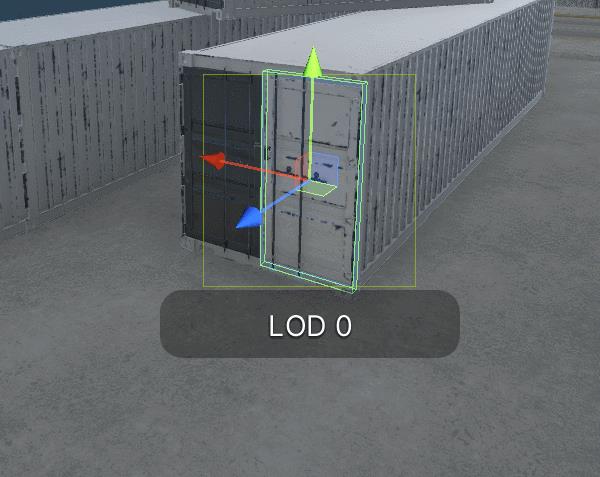
如果我们希望细节程度较低的模型看起来也正常,需要在周围放置Light Probe Group 即光照探针,以获取烘焙过程中的间接光照。
具体可以参考官方文档:https://docs.unity.cn/2017.2/Documentation/Manual/LODForBakedGI.html
一次 group by + order by 性能优化分析
一次 group by + order by 性能优化分析
最近通过一个日志表做排行的时候发现特别卡,最后问题得到了解决,梳理一些索引和MySQL执行过程的经验,但是最后还是有5个谜题没解开,希望大家帮忙解答下。
主要包含如下知识点
- 用数据说话证明慢日志的扫描行数到底是如何统计出来的
- 从 group by 执行原理找出优化方案
- 排序的实现细节
- gdb 源码调试
背景
需要分别统计本月、本周被访问的文章的 TOP10。日志表如下
CREATE TABLE `article_rank` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `aid` int(11) unsigned NOT NULL, `pv` int(11) unsigned NOT NULL DEFAULT ‘1‘, `day` int(11) NOT NULL COMMENT ‘日期 例如 20171016‘, PRIMARY KEY (`id`), KEY `idx_day_aid_pv` (`day`,`aid`,`pv`), KEY `idx_aid_day_pv` (`aid`,`day`,`pv`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
准备工作
为了能够清晰的验证自己的一些猜想,在虚拟机里安装了一个 debug 版的 mysql,然后开启了慢日志收集,用于统计扫描行数
安装
- 下载源码
- 编译安装
- 创建 mysql 用户
- 初始化数据库
- 初始化 mysql 配置文件
- 修改密码
开启慢日志
编辑配置文件,在[mysqld]块下添加
slow_query_log=1 slow_query_log_file=xxx long_query_time=0 log_queries_not_using_indexes=1
性能分析
发现问题
假如我需要查询2018-12-20 ~ 2018-12-24这5天浏览量最大的10篇文章的 sql 如下,首先使用explain看下分析结果
mysql> explain select aid,sum(pv) as num from article_rank where day>=20181220 and day<=20181224 group by aid order by num desc limit 10;
+----+-------------+--------------+------------+-------+-------------------------------+----------------+---------+------+--------+----------+-----------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+-------------------------------+----------------+---------+------+--------+----------+-----------------------------------------------------------+
| 1 | SIMPLE | article_rank | NULL | range | idx_day_aid_pv,idx_aid_day_pv | idx_day_aid_pv | 4 | NULL | 404607 | 100.00 | Using where; Using index; Using temporary; Using filesort |
+----+-------------+--------------+------------+-------+-------------------------------+----------------+---------+------+--------+----------+-----------------------------------------------------------+
系统默认会走的索引是idx_day_aid_pv,根据Extra信息我们可以看到,使用idx_day_aid_pv索引的时候,会走覆盖索引,但是会使用临时表,会有排序。
我们查看下慢日志里的记录信息
# Time: 2019-03-17T03:02:27.984091Z
# [email protected]: root[root] @ localhost [] Id: 6
# Query_time: 56.959484 Lock_time: 0.000195 Rows_sent: 10 Rows_examined: 1337315
SET timestamp=1552791747;
select aid,sum(pv) as num from article_rank where day>=20181220 and day<=20181224 group by aid order by num desc limit 10;
为什么扫描行数是 1337315
我们查询两个数据,一个是满足条件的行数,一个是group by统计之后的行数。
mysql> select count(*) from article_rank where day>=20181220 and day<=20181224;
+----------+
| count(*) |
+----------+
| 785102 |
+----------+
mysql> select count(distinct aid) from article_rank where day>=20181220 and day<=20181224;
+---------------------+
| count(distinct aid) |
+---------------------+
| 552203 |
+---------------------+
发现满足条件的总行数(785102)+group by之后的总行数(552203)+limit 的值 =慢日志里统计的 Rows_examined。
要解答这个问题,就必须搞清楚上面这个 sql 到底分别都是如何运行的。
执行流程分析
索引示例
为了便于理解,我按照索引的规则先模拟idx_day_aid_pv索引的一小部分数据
表格
| day | aid | pv | id |
|---|---|---|---|
| 20181220 | 1 | 23 | 1234 |
| 20181220 | 3 | 2 | 1231 |
| 20181220 | 4 | 1 | 1212 |
| 20181220 | 7 | 2 | 1221 |
| 20181221 | 1 | 5 | 1257 |
| 20181221 | 10 | 1 | 1251 |
| 20181221 | 11 | 8 | 1258 |
因为索引idx_day_aid_pv最左列是day,所以当我们需要查找20181220~20181224之间的文章的pv总和的时候,我们需要遍历20181220~20181224这段数据的索引。
查看 optimizer trace 信息
# 开启 optimizer_trace
set optimizer_trace=‘enabled=on‘;
# 执行 sql
select aid,sum(pv) as num from article_rank where day>=20181220 and day<=20181224 group by aid order by num desc limit 10;
# 查看 trace 信息
select trace from `information_schema`.`optimizer_trace`\\G;
摘取里面最后的执行结果如下
{ "join_execution": { "select#": 1, "steps": [ { "creating_tmp_table": { "tmp_table_info": { "table": "intermediate_tmp_table", "row_length": 20, "key_length": 4, "unique_constraint": false, "location": "memory (heap)", "row_limit_estimate": 838860 } } }, { "converting_tmp_table_to_ondisk": { "cause": "memory_table_size_exceeded", "tmp_table_info": { "table": "intermediate_tmp_table", "row_length": 20, "key_length": 4, "unique_constraint": false, "location": "disk (InnoDB)", "record_format": "fixed" } } }, { "filesort_information": [ { "direction": "desc", "table": "intermediate_tmp_table", "field": "num" } ], "filesort_priority_queue_optimization": { "limit": 10, "rows_estimate": 1057, "row_size": 36, "memory_available": 262144, "chosen": true }, "filesort_execution": [ ], "filesort_summary": { "rows": 11, "examined_rows": 552203, "number_of_tmp_files": 0, "sort_buffer_size": 488, "sort_mode": "<sort_key, additional_fields>" } } ] } }
通过gdb调试确认临时表上的字段是aid和num
Breakpoint 1, trace_tmp_table (trace=0x7eff94003088, table=0x7eff94937200) at /root/newdb/mysql-server/sql/sql_tmp_table.cc:2306 warning: Source file is more recent than executable. 2306 trace_tmp.add("row_length",table->s->reclength). (gdb) p table->s->reclength $1 = 20 (gdb) p table->s->fields $2 = 2 (gdb) p (*(table->field+0))->field_name $3 = 0x7eff94010b0c "aid" (gdb) p (*(table->field+1))->field_name $4 = 0x7eff94007518 "num" (gdb) p (*(table->field+0))->row_pack_length() $5 = 4 (gdb) p (*(table->field+1))->row_pack_length() $6 = 15 (gdb) p (*(table->field+0))->type() $7 = MYSQL_TYPE_LONG (gdb) p (*(table->field+1))->type() $8 = MYSQL_TYPE_NEWDECIMAL (gdb)
通过上面的打印,确认了字段类型,一个aid是MYSQL_TYPE_LONG,占4字节,num是MYSQL_TYPE_NEWDECIMAL,占15字节。
但是通过我们上面打印信息可以看到两个字段的长度加起来是19,而optimizer_trace里的tmp_table_info.reclength是20。通过其他实验也发现table->s->reclength的长度就是table->field数组里面所有字段的字段长度和再加1。
总结执行流程
- 尝试在堆上使用memory的内存临时表来存放group by的数据,发现内存不够;
- 创建一张临时表,临时表上有两个字段,aid和num字段(sum(pv) as num);
- 从索引idx_day_aid_pv中取出1行,插入临时表。插入规则是如果aid不存在则直接插入,如果存在,则把pv的值累加在num上;
- 循环遍历索引idx_day_aid_pv上20181220~20181224之间的所有行,执行步骤3;
- 对临时表根据num的值做优先队列排序;
- 取出最后留在堆(优先队列的堆)里面的10行数据,作为结果集直接返回,不需要再回表;
补充说明优先队列排序执行步骤分析:
- 在临时表(未排序)中取出前 10 行,把其中的num和aid作为10个元素构成一个小顶堆,也就是最小的 num 在堆顶。
- 取下一行,根据 num 的值和堆顶值作比较,如果该字大于堆顶的值,则替换掉。然后将新的堆做堆排序。
- 重复步骤2直到第 552203 行比较完成。
优化
方案1 使用 idx_aid_day_pv 索引
# Query_time: 4.406927 Lock_time: 0.000200 Rows_sent: 10 Rows_examined: 1337315 SET timestamp=1552791804; select aid,sum(pv) as num from article_rank force index(idx_aid_day_pv) where day>=20181220 and day<=20181224 group by aid order by num desc limit 10;
扫描行数都是1337315,为什么执行消耗的时间上快了12倍呢?
group by 不需要临时表的情况
为什么性能上比 SQL1 高了,很多呢,原因之一是idx_aid_day_pv索引上aid是确定有序的,那么执行group by的时候,则不会创建临时表,排序的时候才需要临时表。如果印证这一点呢,我们通过下面的执行计划就能看到
使用idx_day_aid_pv索引的效果:
mysql> explain select aid,sum(pv) as num from article_rank force index(idx_day_aid_pv) where day>=20181220 and day<=20181224 group by aid order by null limit 10; +----+-------------+--------------+------------+-------+-------------------------------+----------------+---------+------+--------+----------+-------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+-------+-------------------------------+----------------+---------+------+--------+----------+-------------------------------------------+ | 1 | SIMPLE | article_rank | NULL | range | idx_day_aid_pv,idx_aid_day_pv | idx_day_aid_pv | 4 | NULL | 404607 | 100.00 | Using where; Using index; Using temporary | +----+-------------+--------------+------------+-------+-------------------------------+----------------+---------+------+--------+----------+-------------------------------------------+
注意我上面使用了order by null表示强制对group by的结果不做排序。如果不加order by null,上面的 sql则会出现Using filesort
使用idx_aid_day_pv索引的效果:
mysql> explain select aid,sum(pv) as num from article_rank force index(idx_aid_day_pv) where day>=20181220 and day<=20181224 group by aid order by null limit 10; +----+-------------+--------------+------------+-------+-------------------------------+----------------+---------+------+------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+-------+-------------------------------+----------------+---------+------+------+----------+--------------------------+ | 1 | SIMPLE | article_rank | NULL | index | idx_day_aid_pv,idx_aid_day_pv | idx_aid_day_pv | 12 | NULL | 10 | 11.11 | Using where; Using index | +----+-------------+--------------+------------+-------+-------------------------------+----------------+---------+------+------+----------+--------------------------+
查看 optimizer trace 信息
# 开启optimizer_trace set optimizer_trace=‘enabled=on‘; # 执行 sql select aid,sum(pv) as num from article_rank force index(idx_aid_day_pv) where day>=20181220 and day<=20181224 group by aid order by num desc limit 10; # 查看 trace 信息 select trace from `information_schema`.`optimizer_trace`\\G;
摘取里面最后的执行结果如下
{ "join_execution": { "select#": 1, "steps": [ { "creating_tmp_table": { "tmp_table_info": { "table": "intermediate_tmp_table", "row_length": 20, "key_length": 0, "unique_constraint": false, "location": "memory (heap)", "row_limit_estimate": 838860 } } }, { "filesort_information": [ { "direction": "desc", "table": "intermediate_tmp_table", "field": "num" } ], "filesort_priority_queue_optimization": { "limit": 10, "rows_estimate": 552213, "row_size": 24, "memory_available": 262144, "chosen": true }, "filesort_execution": [ ], "filesort_summary": { "rows": 11, "examined_rows": 552203, "number_of_tmp_files": 0, "sort_buffer_size": 352, "sort_mode": "<sort_key, rowid>" } } ] } }
执行流程如下
- 创建一张临时表,临时表上有两个字段,aid和num字段(sum(pv) as num);
- 读取索引idx_aid_day_pv中的一行,然后查看是否满足条件,如果day字段不在条件范围内(20181220~20181224之间),则读取下一行;如果day字段在条件范围内,则把pv值累加(不是在临时表中操作);
- 读取索引idx_aid_day_pv中的下一行,如果aid与步骤1中一致且满足条件,则pv值累加(不是在临时表中操作)。如果aid与步骤1中不一致,则把之前的结果集写入临时表;
- 循环执行步骤2、3,直到扫描完整个idx_aid_day_pv索引;
- 对临时表根据num的值做优先队列排序;
- 根据查询到的前10条的rowid回表(临时表)返回结果集。
补充说明优先队列排序执行步骤分析:
- 在临时表(未排序)中取出前 10 行,把其中的num和rowid作为10个元素构成一个小顶堆,也就是最小的 num 在堆顶。
- 取下一行,根据 num 的值和堆顶值作比较,如果该字大于堆顶的值,则替换掉。然后将新的堆做堆排序。
- 重复步骤2直到第 552203 行比较完成。
该方案可行性
实验发现,当我增加一行20181219的数据时,虽然这行记录不满足我们的需求,但是扫描索引的也会读取这行。因为我做这个实验,只弄了20181220~201812245天的数据,所以需要扫描的行数正好是全表数据行数。
那么如果该表的数据存储的不是5天的数据,而是10天的数据呢,更或者是365天的数据呢?这个方案是否还可行呢?先模拟10天的数据,在现有时间基础上往后加5天,行数与现在一样785102行。
drop procedure if exists idata; delimiter ;; create procedure idata() begin declare i int; declare aid int; declare pv int; declare post_day int; set i=1; while(i<=785102)do set aid = round(rand()*500000); set pv = round(rand()*100); set post_day = 20181225 + i%5; insert into article_rank (`aid`,`pv`,`day`) values(aid, pv, post_day); set i=i+1; end while; end;; delimiter ; call idata(); # Query_time: 9.151270 Lock_time: 0.000508 Rows_sent: 10 Rows_examined: 2122417 SET timestamp=1552889936; select aid,sum(pv) as num from article_rank force index(idx_aid_day_pv) where day>=20181220 and day<=20181224 group by aid order by num desc limit 10;
这里扫描行数2122417是因为扫描索引的时候需要遍历整个索引,整个索引的行数就是全表行数,因为我刚刚又插入了785102行。
当我数据量翻倍之后,这里查询时间明显已经翻倍。所以这个优化方式不稳定。
方案2 扩充临时表空间上限大小
默认的临时表空间大小是16MB
mysql> show global variables like ‘%table_size‘; +---------------------+----------+ | Variable_name | Value | +---------------------+----------+ | max_heap_table_size | 16777216 | | tmp_table_size | 16777216 | +---------------------+----------+
https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_max_heap_table_size https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_tmp_table_size max_heap_table_size This variable sets the maximum size to which user-created MEMORY tables are permitted to grow. The value of the variable is used to calculate MEMORY table MAX_ROWS values. Setting this variable has no effect on any existing MEMORY table, unless the table is re-created with a statement such as CREATE TABLE or altered with ALTER TABLE or TRUNCATE TABLE. A server restart also sets the maximum size of existing MEMORY tables to the global max_heap_table_size value. tmp_table_size The maximum size of internal in-memory temporary tables. This variable does not apply to user-created MEMORY tables. The actual limit is determined from whichever of the values of tmp_table_size and max_heap_table_size is smaller. If an in-memory temporary table exceeds the limit, MySQL automatically converts it to an on-disk temporary table. The internal_tmp_disk_storage_engine option defines the storage engine used for on-disk temporary tables.
也就是说这里临时表的限制是16M,max_heap_table_size大小也受tmp_table_size大小的限制。
所以我们这里调整为32MB,然后执行原始的SQL
set tmp_table_size=33554432; set max_heap_table_size=33554432; # Query_time: 5.910553 Lock_time: 0.000210 Rows_sent: 10 Rows_examined: 1337315 SET timestamp=1552803869; select aid,sum(pv) as num from article_rank where day>=20181220 and day<=20181224 group by aid order by num desc limit 10;
方案3 使用 `SQL_BIG_RESULT` 优化
告诉优化器,查询结果比较多,临时表直接走磁盘存储。
# Query_time: 6.144315 Lock_time: 0.000183 Rows_sent: 10 Rows_examined: 2122417 SET timestamp=1552802804; select SQL_BIG_RESULT aid,sum(pv) as num from article_rank where day>=20181220 and day<=20181224 group by aid order by num desc limit 10;
扫描行数是 2x满足条件的总行数(785102)+group by之后的总行数(552203)+limit的值。
顺便值得一提的是: 当我把数据量翻倍之后,使用该方式,查询时间基本没变。因为扫描的行数还是不变的。实际测试耗时6.197484
总结
方案1优化效果不稳定,当总表数据量与查询范围的总数相同时,且不超出内存临时表大小限制时,性能达到最佳。当查询数据量占据总表数据量越大,优化效果越不明显;
方案2需要调整临时表内存的大小,可行;不过当数据库超过32MB时,如果使用该方式,还需要继续提升临时表大小;
方案3直接声明使用磁盘来放临时表,虽然扫描行数多了一次符合条件的总行数的扫描。但是整体响应时间比方案2就慢了0.1秒。因为我们这里数据量比较,我觉得这个时间差还能接受。
所以最后对比,选择方案3比较合适。
问题与困惑
# SQL1 select aid,sum(pv) as num from article_rank where day>=20181220 and day<=20181224 group by aid order by num desc limit 10; # SQL2 select aid,sum(pv) as num from article_rank force index(idx_aid_day_pv) where day>=20181220 and day<=20181224 group by aid order by num desc limit 10;
- SQL1 执行过程中,使用的是全字段排序最后不需要回表为什么总扫描行数还要加上10才对得上?
- SQL1 与 SQL2 group by之后得到的行数都是552203,为什么会出现 SQL1 内存不够,里面还有哪些细节呢?
- trace 信息里的creating_tmp_table.tmp_table_info.row_limit_estimate都是838860;计算由来是临时表的内存限制大小16MB,而一行需要占的空间是20字节,那么最多只能容纳floor(16777216/20) = 838860行,而实际我们需要放入临时表的行数是785102。为什么呢?
- SQL1 使用SQL_BIG_RESULT优化之后,原始表需要扫描的行数会乘以2,背后逻辑是什么呢?为什么仅仅是不再尝试往内存临时表里写入这一步会相差10多倍的性能?
- 通过源码看到 trace 信息里面很多扫描行数都不是实际的行数,既然是实际执行,为什么 trace 信息里不输出真实的扫描行数和容量等呢,比如filesort_priority_queue_optimization.rows_estimate在SQL1中的扫描行数我通过gdb看到计算规则如附录图 1
- 有没有工具能够统计 SQL 执行过程中的 I/O 次数?
关注微信公众号:编程学习分享

转自:https://mengkang.net/1355.htm
以上是关于UnityLOD Group- 关于性能优化中LOD的使用与总结的主要内容,如果未能解决你的问题,请参考以下文章