MySQL数据库Query性能定位
Posted ╰☆ぷ天然ルo槑ご
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL数据库Query性能定位相关的知识,希望对你有一定的参考价值。
1.SQL前面加 EXPLAIN 定位到sql级别
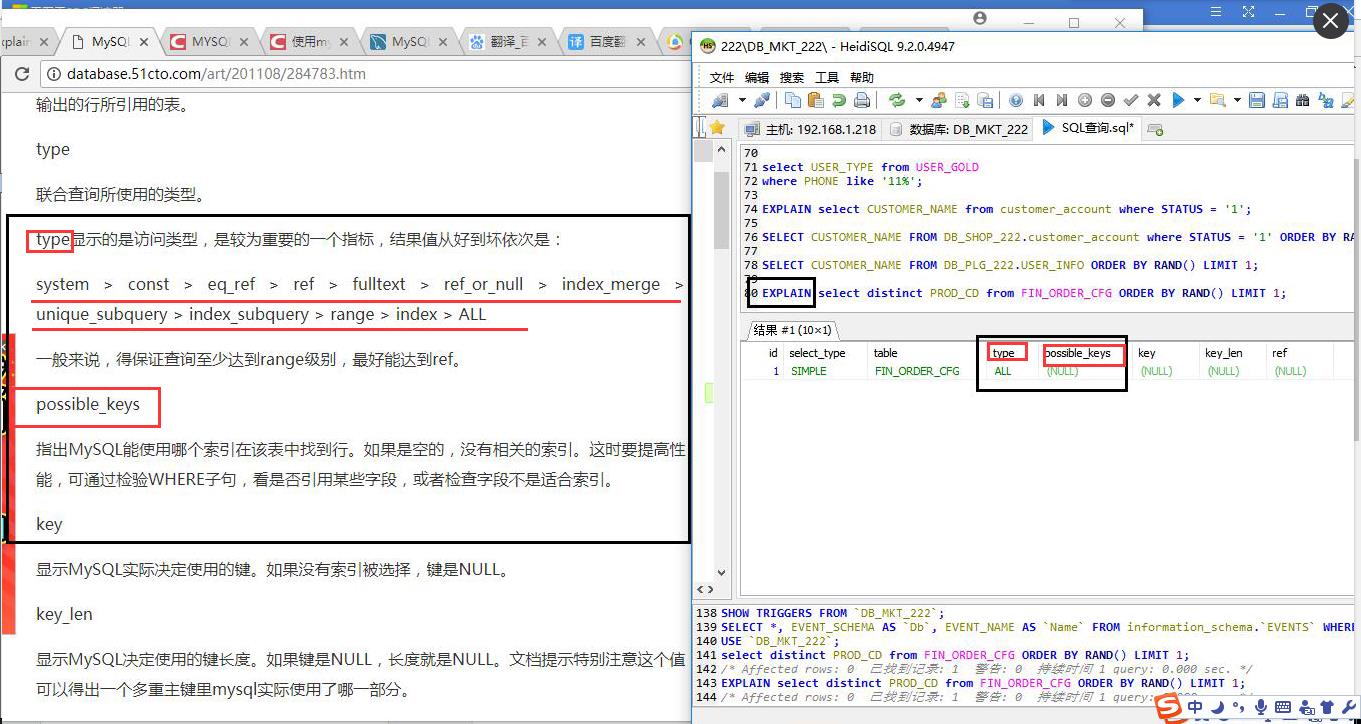
各个属性的含义
id
select查询的序列号
select_type
select查询的类型,主要是区别普通查询和联合查询、子查询之类的复杂查询。
table
输出的行所引用的表。
type
联合查询所使用的类型。
type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
possible_keys
指出mysql能使用哪个索引在该表中找到行。如果是空的,没有相关的索引。这时要提高性能,可通过检验WHERE子句,看是否引用某些字段,或者检查字段不是适合索引。
key
显示MySQL实际决定使用的键。如果没有索引被选择,键是NULL。
key_len
显示MySQL决定使用的键长度。如果键是NULL,长度就是NULL。文档提示特别注意这个值可以得出一个多重主键里mysql实际使用了哪一部分。
ref
显示哪个字段或常数与key一起被使用。
rows
这个数表示mysql要遍历多少数据才能找到,在innodb上是不准确的。
Extra
如果是Only index,这意味着信息只用索引树中的信息检索出的,这比扫描整个表要快。
如果是where used,就是使用上了where限制。
如果是impossible where 表示用不着where,一般就是没查出来啥。
如果此信息显示Using filesort或者Using temporary的话会很吃力,WHERE和ORDER BY的索引经常无法兼顾,如果按照WHERE来确定索引,那么在ORDER BY时,就必然会引起Using filesort,这就要看是先过滤再排序划算,还是先排序再过滤划算。
详细含义
我们先看一下在 MySQL Explain 功能中给我们展示的各种信息的解释:
◆ ID:Query Optimizer 所选定的执行计划中查询的序列号;
◆ Select_type:所使用的查询类型,主要有以下这几种查询类型
◇ DEPENDENT SUBQUERY:子查询中内层的第一个 SELECT,依赖于外部查询的结果集;
◇ DEPENDENT UNION:子查询中的 UNION,且为 UNION 中从第二个 SELECT 开始的后面所有
SELECT,同样依赖于外部查询的结果集;
◇ PRIMARY:子查询中的最外层查询,注意并不是主键查询;
◇ SIMPLE:除子查询或者 UNION 之外的其他查询;
◇ SUBQUERY:子查询内层查询的第一个 SELECT,结果不依赖于外部查询结果集;
◇ UNCACHEABLE SUBQUERY:结果集无法缓存的子查询;
◇ UNION:UNION 语句中第二个 SELECT 开始的后面所有 SELECT,第一个 SELECT 为 PRIMARY
◇ UNION RESULT:UNION 中的合并结果;
◆ Table:显示这一步所访问的数据库中的表的名称;
◆ Type:告诉我们对表所使用的访问方式,主要包含如下集中类型;
◇ all:全表扫描
◇ const:读常量,且最多只会有一条记录匹配,由于是常量,所以实际上只需要读一次;
◇ eq_ref:最多只会有一条匹配结果,一般是通过主键或者唯一键索引来访问;
◇ fulltext:
◇ index:全索引扫描;
◇ index_merge:查询中同时使用两个(或更多)索引,然后对索引结果进行 merge 之后再读
取表数据;
◇ index_subquery:子查询中的返回结果字段组合是一个索引(或索引组合),但不是一个
主键或者唯一索引;
◇ rang:索引范围扫描;
◇ ref:Join 语句中被驱动表索引引用查询;
◇ ref_or_null:与 ref 的唯一区别就是在使用索引引用查询之外再增加一个空值的查询;
◇ system:系统表,表中只有一行数据;
◇ unique_subquery:子查询中的返回结果字段组合是主键或者唯一约束;
◇
◆ Possible_keys:该查询可以利用的索引. 如果没有任何索引可以使用,就会显示成null,这一
项内容对于优化时候索引的调整非常重要;
◆ Key:MySQL Query Optimizer 从 possible_keys 中所选择使用的索引;
◆ Key_len:被选中使用索引的索引键长度;
◆ Ref:列出是通过常量(const),还是某个表的某个字段(如果是 join)来过滤(通过 key)
的;
◆ Rows:MySQL Query Optimizer 通过系统收集到的统计信息估算出来的结果集记录条数;
◆ Extra:查询中每一步实现的额外细节信息,主要可能会是以下内容:
◇ Distinct:查找 distinct 值,所以当 mysql 找到了第一条匹配的结果后,将停止该值的查
询而转为后面其他值的查询;
◇ Full scan on NULL key:子查询中的一种优化方式,主要在遇到无法通过索引访问 null
值的使用使用;
◇ Impossible WHERE noticed after reading const tables:MySQL Query Optimizer 通过
收集到的统计信息判断出不可能存在结果;
◇ No tables:Query 语句中使用 FROM DUAL 或者不包含任何 FROM 子句;
◇ Not exists:在某些左连接中 MySQL Query Optimizer 所通过改变原有 Query 的组成而
使用的优化方法,可以部分减少数据访问次数;
◇ Range checked for each record (index map: N):通过 MySQL 官方手册的描述,当
MySQL Query Optimizer 没有发现好的可以使用的索引的时候,如果发现如果来自前面的
表的列值已知,可能部分索引可以使用。对前面的表的每个行组合,MySQL检查是否可以使
用 range 或 index_merge 访问方法来索取行。
◇ Select tables optimized away:当我们使用某些聚合函数来访问存在索引的某个字段的
时候,MySQL Query Optimizer 会通过索引而直接一次定位到所需的数据行完成整个查
询。当然,前提是在 Query 中不能有 GROUP BY 操作。如使用 MIN()或者 MAX()的时
候;
◇ Using filesort:当我们的 Query 中包含 ORDER BY 操作,而且无法利用索引完成排序操
作的时候,MySQL Query Optimizer 不得不选择相应的排序算法来实现。
◇ Using index:所需要的数据只需要在 Index 即可全部获得而不需要再到表中取数据;
◇ Using index for group-by:数据访问和 Using index 一样,所需数据只需要读取索引即
可,而当 Query 中使用了 GROUP BY 或者 DISTINCT 子句的时候,如果分组字段也在索引
中,Extra 中的信息就会是 Using index for group-by;
◇ Using temporary:当 MySQL 在某些操作中必须使用临时表的时候,在 Extra 信息中就会
出现 Using temporary 。主要常见于 GROUP BY 和 ORDER BY 等操作中。
◇ Using where:如果我们不是读取表的所有数据,或者不是仅仅通过索引就可以获取所有需
要的数据,则会出现 Using where 信息;
◇ Using where with pushed condition:这是一个仅仅在 NDBCluster 存储引擎中才会出现
的信息,而且还需要通过打开 Condition Pushdown 优化功能才可能会被使用。控制参数
为 engine_condition_pushdown 。
2、使用PROFILING 功能可以很清楚的找出一个Query 的IO和cup的瓶颈所在。(百度一下,有很多)
1、 开启 profiling 参数
root@localhost : (none) 10:53:11> set profiling=1;
Query OK, 0 rows affected (0.00 sec)
通过执行 “set profiling”命令,可以开启关闭 Query Profiler 功能。
2、 执行 Query
... ...
root@localhost : test 07:43:18> select status,count(*)
-> from test_profiling group by status;
+----------------+----------+
| status | count(*) |
+----------------+----------+
| st_xxx1 | 27 |
| st_xxx2 | 6666 |
| st_xxx3 | 292887 |
| st_xxx4 | 15 |
+----------------+----------+
5 rows in set (1.11 sec)
... ...
在开启 Query Profiler 功能之后,MySQL 就会自动记录所有执行的 Query 的 profile 信息了。
3、获取系统中保存的所有 Query 的 profile 概要信息
root@localhost : test 07:47:35> show profiles;
+----------+------------+------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+------------------------------------------------------------+
| 1 | 0.00183100 | show databases |
| 2 | 0.00007000 | SELECT DATABASE() |
| 3 | 0.00099300 | desc test |
| 4 | 0.00048800 | show tables |
| 5 | 0.00430400 | desc test_profiling |
| 6 | 1.90115800 | select status,count(*) from test_profiling group by status |
+----------+------------+------------------------------------------------------------+
3 rows in set (0.00 sec)
通过执行 “SHOW PROFILE” 命令获取当前系统中保存的多个 Query 的 profile 的概要信息。
4、针对单个 Query 获取详细的 profile 信息。
在获取到概要信息之后,我们就可以根据概要信息中的 Query_ID 来获取某个 Query 在执行过程中
详细的 profile 信息了,具体操作如下:
root@localhost : test 07:49:24> show profile cpu, block io for query 6;
+----------------------+----------+----------+------------+--------------+---------------+
| Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out |
+----------------------+----------+----------+------------+--------------+---------------+
| starting | 0.000349 | 0.000000 | 0.000000 | 0 | 0 |
| Opening tables | 0.000012 | 0.000000 | 0.000000 | 0 | 0 |
| System lock | 0.000004 | 0.000000 | 0.000000 | 0 | 0 |
| Table lock | 0.000006 | 0.000000 | 0.000000 | 0 | 0 |
| init | 0.000023 | 0.000000 | 0.000000 | 0 | 0 |
| optimizing | 0.000002 | 0.000000 | 0.000000 | 0 | 0 |
| statistics | 0.000007 | 0.000000 | 0.000000 | 0 | 0 |
| preparing | 0.000007 | 0.000000 | 0.000000 | 0 | 0 |
| Creating tmp table | 0.000035 | 0.000999 | 0.000000 | 0 | 0 |
| executing | 0.000002 | 0.000000 | 0.000000 | 0 | 0 |
| Copying to tmp table | 1.900619 | 1.030844 | 0.197970 | 347 | 347 |
| Sorting result | 0.000027 | 0.000000 | 0.000000 | 0 | 0 |
| Sending data | 0.000017 | 0.000000 | 0.000000 | 0 | 0 |
| end | 0.000002 | 0.000000 | 0.000000 | 0 | 0 |
| removing tmp table | 0.000007 | 0.000000 | 0.000000 | 0 | 0 |
| end | 0.000002 | 0.000000 | 0.000000 | 0 | 0 |
| query end | 0.000003 | 0.000000 | 0.000000 | 0 | 0 |
| freeing items | 0.000029 | 0.000000 | 0.000000 | 0 | 0 |
| logging slow query | 0.000001 | 0.000000 | 0.000000 | 0 | 0 |
| logging slow query | 0.000002 | 0.000000 | 0.000000 | 0 | 0 |
| cleaning up | 0.000002 | 0.000000 | 0.000000 | 0 | 0 |
+----------------------+----------+----------+------------+--------------+---------------+
上面的例子中是获取 CPU 和 Block IO 的消耗,非常清晰,对于定位性能瓶颈非常适用。希望得到
取其他的信息,都可以通过执行 “SHOW PROFILE *** FOR QUERY n” 来获取,各位读者朋友可以自行
测试熟悉。
以上是关于MySQL数据库Query性能定位的主要内容,如果未能解决你的问题,请参考以下文章