《mysql必知必会》笔记-部分
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《mysql必知必会》笔记-部分相关的知识,希望对你有一定的参考价值。
《mysql必知必会》笔记-部分
注释:
开始时整理笔记,记录自己看书过程的疑问和重点,后来发现记录没太多意义,还不如直接去翻原书,所以就放弃了。
因此,这个笔记只有一部分,不过依旧分享出来。
1、语言分类:
客户机可以是MySQL提供的工具、脚本语言(如perl)、Web应用开发语言(如ASP、ColdFusion、JSP和php)、程序设计语言(如C、C+kJava)等。
2、之前找不到表的原因:
虽然SQL是不区分大小写的,但有些标识符(如数据库名、表名、列名)可能不同:在MySQL4.1及之前的版本中,这些标识符默认区分大小写;在MySQL4.1.1版本中,这些标识符默认不区分大小写。
3、养成良好的习惯:
多条SQL语句必须以分号(;)分隔。MySQL如同多数DBMS—样,不需要在单条SQL语句后加分号。但特定的DBMS可能必须在单条SQL语句后加上分号。当然,如果愿意可以总是加上分号。事实上,即使不一定需要,但加上分号肯定没有坏。处如果你使用的是mysql命令行,必须加上分号来结束SQL语句。
4、我总是使用,以后记得这么优化:
除非你确实需要表中的每个列,否则最好别使用 * 通配符。虽然使用通配符可能会使你自己省事,不
用明确列出所需列,但检索不需要的列通常会降低检索和应用程序的性能。
5、对于Distinct的理解:
DISTINCT 关键字应用于 所有列而不仅是前置它的列 。如果给出 SELECT DISTINCT vend_id,
prod_price ,除非指定的两个列都不同,否则所有行都将被检索出来。
具体可看教程,很详细
6、LIMIT 的用法:我总是误解。
LIMIT 5 :指示MySQL返回不多于5行。
LIMIT 5, 5 :指示MySQL返回从行5开始的5行。第一个数为开始位置,第二个数为要检索的行数。
注意:MySQL行计数从0开始。因此, LIMIT 1, 1将检索出第二行而不是第一行。
7、子句:
SQL语句由子句构成,有些子句必需,有的可选。一个子句通常由一个关键字和所提供的数据组
成。子句的例子有 SELECT 语句的 FROM 子句,WHERE子句等…
8、多列排序:
按多个列排序时,排序完全按所规定的顺序进行。
即先对第一列排序,再在第一列的结果基础上,对第二列进行排序。如果第一列中所有的值都是唯一的,则不会按第二列排序。
如果想在多个列上进行降序排序,必须对每个列指定 DESC 关键字。(没写:默认升序)
9、何时使用引号:
单引号用来限定字符串。如果将值与串类型的列进行比较,则需要限定引号。用来与数值列进行比较的值不用引号。
10、BETWEEN:
使用 BETWEEN 时,必须指定两个值——所需范围的低端值和高端值。这两个值必须用 AND 关键字
分隔。 BETWEEN 匹配范围中所有的值,包括指定的开始值和结束值。
11、空格和空字符串不一样么?
NULL 无值(no value),它与字段包含 0 、空字符串或仅仅包含空格不同。
12、NULL 与不匹配
在通过过滤选择出不具有特定值的行时,你可能希望返回具有 NULL 值的行。但是,不行。
因为未知具有特殊的含义,数据库不知道它们是否匹配,所以在匹配过滤或不匹配过滤时不返回它们。
因此,在过滤数据时,一定要验证返回数据中确实给出了被过滤列具有 NULL 的行。
13、AND和OR的优先级问题:

14、为什么要使用 IN 操作符?IN 操作符的优点:
- 在使用长的合法选项清单时, IN 操作符的语法更清楚且更直观。
- 在使用 IN 时,计算的次序更容易管理(因为使用的操作符更少)。
- IN 操作符一般比 OR 操作符清单执行更快。
- IN 的最大优点是可以包含其他 SELECT 语句,使得能够更动态地建立 WHERE 子句。
15、通配符 和 LIKE :
LIKE 指示MySQL,后跟的搜索模式利用通配符匹配而不是直接相等匹配进行比较。
百分号( % )通配符: 代表搜索模式中给定位置的0个、1个或多个字符。
下划线( _ )通配符:用途与 % 一样,但下划线只匹配单个字符而不是多个字符。
使用通配符时注意:
- 注意尾空格:尾空格可能会干扰通配符匹配。例如,在保存词anvil 时,如果它 后面有一个或多个空格,则子句 WHEREprod_name LIKE ‘%anvil‘ 将不会匹配它们,因为在最后的 l后有多余的字符。解决这个问题的一个简单的办法是在搜索模式最后附加一个 % 。一个更好的办法是使用函数(第11章将会介绍)去掉首尾空格。
- 注意NULL : 虽然似乎 % 通配符可以匹配任何东西,但有一个例外,即 NULL 。即使是 WHERE prod_name LIKE ‘%‘ 也不能匹配用值 NULL 作为产品名的行。
使用通配符的技巧:
- 使用通配符有代价:通配符搜索的处理一般要比前面讨论的其他搜索所花时间更长。
- 不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。
- 在确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索模式的开始处。把通配符置于搜索模式的开始处,搜索起来是最慢的。
- 仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据。
16、谓词:
操作符何时不是操作符?答案是在它作为谓词(predi-cate)时。从技术上说, LIKE 是谓词而不是操作符。虽然最终的结果是相同的,但应该对此术语有所了解,以免在SQL文档中遇到此术语时不知道。
17、正则表达式:
REGEXP :它告诉MySQL: REGEXP 后所跟的东西作为正则表达式(与文字正文 1000 匹配的一个正则表达式)处理。
- 正则表达式和like的不同:

- 匹配不区分大小写:MySQL中的正则表达式匹配(自版本3.23.4后)不区分大小写(即,大写和小写都匹配)。为区分大小写,可使用 BINARY 关键字,如 WHERE prod_name REGEXP
BINARY ‘JetPack .000‘ 。
- 匹配不区分大小写:MySQL中的正则表达式匹配(自版本3.23.4后)不区分大小写(即,大写和小写都匹配)。为区分大小写,可使用 BINARY 关键字,如 WHERE prod_name REGEXP
| 为正则表达式的 OR 操作符。
- 是另一种形式的 OR 语句:[123] 定义一组字符,它的意思是匹配 1 或 2 或 3
使用 - 来定义一个范围
匹配特殊字符(转义字符):
必须用 \\ 为前导。 \\- 表示查找 - , \\. 表示查找 .
- 匹配 \\: 为了匹配反斜杠( \\ )字符本身,需要使用 \\\\ 。
注意:\\ 或 \\? 多数正则表达式实现使用单个反斜杠转义特殊字符,以便能使用这些字符本身。但MySQL要求两个反斜杠(MySQL自己解释一个,正则表达式库解释另一个)。

- 匹配字符类:

- 匹配多个实例

- 定位符

注意:
- ^ 的双重用途 ^ 有两种用法。在集合中(用 [ 和 ] 定义),用它来否定该集合,否则,用来指串的开始处。
- 字符集合也可以被否定,即,它们将匹配除指定字符外的任何东西。为否定一个字符集,在集合的开始处放置一个 ^ 即可。因此,尽管 [123]匹配字符 1 、 2 或 3 ,但 [^123] 却匹配除这些字符外的任何东西。
18、计算字段:
字段(field) :基本上与列(column)的意思相同,经常互换使用,不过数据库列一般称为列,而术语字段通常用在计算字段的连接上。
客户机与服务器的格式:可在SQL语句内完成的许多转换和格式化工作都可以直接在客户机应用程序内完成。但一般来说,在数据库服务器上完成这些操作比在客户机中完成要快得多,因为DBMS是设计来快速有效地完成这种处理的。
1、拼接字段:将值联结到一起构成单个值。
MySQL中,可使用Concat() 函数。
Concat() 需要一个或多个指定的串,各个串之间用逗号分隔。
2、删除数据中多余的空格:
可使用MySQL的 RTrim() 函数。
RTrim() 函数:去掉值右边的所有空格。
LTrim() 函数:去掉串左边的空格。
Trim() 函数:去掉串左右两边的空格。
3、使用别名
别名(alias:也称为导出列)是一个字段或值的替换名。别名用 AS 关键字赋予。
4、执行算术计算:
MySQL支持基本算术操作符:

19、函数:
使用函数的注意事项:
函数没有SQL的可移植性强:
能运行在多个系统上的代码称为可移植的(portable)。
相对来说,多数SQL语句是可移植的,在SQL实现之间有差异时,这些差异通常不那么难处理。
而函数的可移植性却不强。几乎每种主要的DBMS的实现都支持其他实现不支持的函数,而且有时差异还很大。
为了代码的可移植,许多SQL程序员不赞成使用特殊实现的功能。虽然这样做很有好处,但不总是利于应用程序的性能。如果不使用这些函数,编写某些应用程序代码会很艰难。必须利用其他方法来实现DBMS非常有效地完成的工作。如果你决定使用函数,应该保证做好代码注释,以便以后你(或
其他人)能确切地知道所编写SQL代码的含义。
1、文本处理函数:
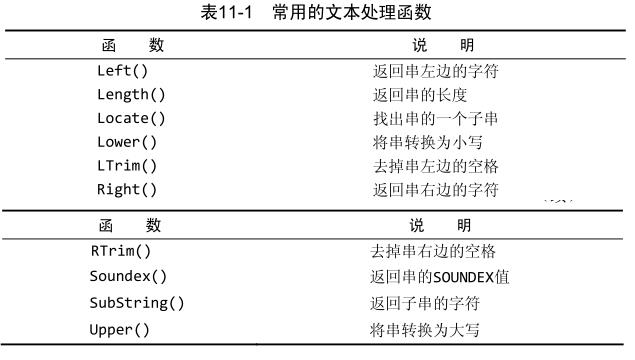
SOUNDEX 是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。 SOUNDEX 考虑了类似的发音字符和音节,使得能对串进行发音比较而不是字母比较。
2、日期和时间处理函数:
数据类型为 datetime :存储日期及时间值。样表中的值全都具有时间值 00:00:00
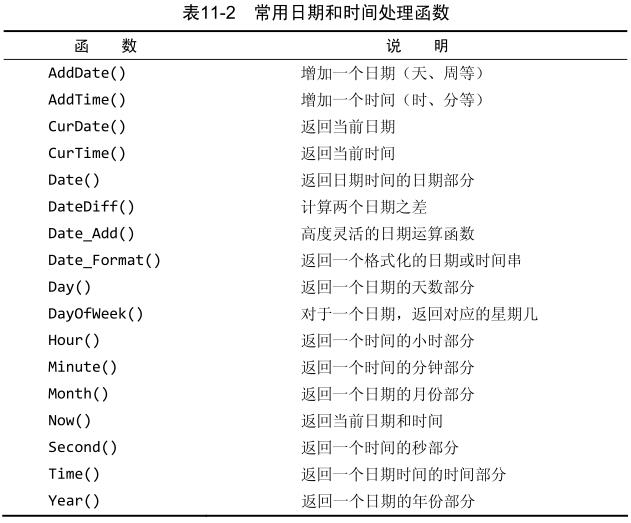
检索出2005年9月下的所有订单:(两种方法)

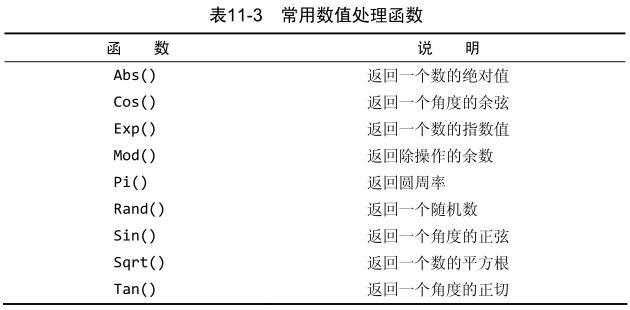
3、数值处理函数
20、聚集函数(aggregate function):运行在行组上,计算和返回单个值的函数。
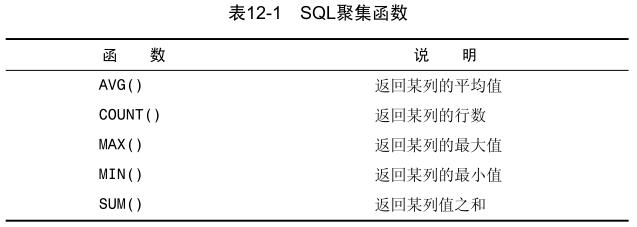
AVG()函数:对表中行数计数并计算特定列值之和,求得该列的平均值。
- 只能用来确定特定数值列的平均值,而且列名必须作为函数参数给出。
- 为了获得多个列的平均值,必须使用多个 AVG() 函数。
- AVG() 函数忽略列值为 NULL 的行。
COUNT() 函数:进行计数。
- 使用 COUNT(*) 对表中行的数目进行计数,不管表列中包含的是空值( NULL )还是非空值。
- 使用 COUNT(column) 对特定列中具有值的行进行计数,忽略NULL 值。
MAX() 函数:返回指定列中的最大值。 MAX() 要求指定列名
- 对非数值数据使用 MAX(): MAX() 一般用来找出最大的数值或日期值,但MySQL允许将它用来返回任意列中的最大值,包括返回文本列中的最大值。
- 在用于文本数据时,如果数据按相应的列排序,则 MAX() 返回最后一行。
- MAX() 函数忽略列值为 NULL 的行。
MIN() 函数:功能正好与 MAX() 功能相反,它返回指定列的最小值。要求指定列名。
- 对非数值数据使用 MIN(): MIN() 函数与 MAX() 函数类似,MySQL允许将它用来返回任意列中的最小值,包括返回文本列中的最小值。
- 在用于文本数据时,如果数据按相应的列排序,则 MIN() 返回最前面的行。
- MIN() 函数忽略列值为 NULL 的行。
SUM() 函数:用来返回指定列值的和(总计)。
- SUM(item_price*quantity):利用标准的算术操作符,所有聚集函数都可用来执行多个列上的计算。
- NULL 值 :SUM() 函数忽略列值为 NULL 的行。
聚集函数都可以如下使用:
- 对所有的行执行计算,指定 ALL 参数或不给参数(因为 ALL 是默认行为);
- 只包含不同的值,指定 DISTINCT 参数。
注意:如果指定列名,则 DISTINCT 只能用于 COUNT() 。 DISTINCT不能用于 COUNT(*),因此不允许使用COUNT(DISTINCT),否则会产生错误 。类似地, DISTINCT 必须使用列名,不能用于计算或表达式。
后续不整理了,用处不大,如需要,可直接看原书。原书就是以工具参考为目的的。
以上是关于《mysql必知必会》笔记-部分的主要内容,如果未能解决你的问题,请参考以下文章