[翻译]——SQL Server索引的介绍:SQL Server索引级的阶梯
Posted 我是墩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[翻译]——SQL Server索引的介绍:SQL Server索引级的阶梯相关的知识,希望对你有一定的参考价值。
SQL Server索引的介绍:SQL Server索引级的阶梯
By David Durant, 2014/11/05 (first published: 2011/02/17)
该系列
本文是楼梯系列的一部分:SQL Server索引的阶梯
索引是数据库设计的基础,并告诉开发人员使用数据库非常了解设计器的意图。不幸的是,当性能问题出现时,索引常常被添加到事后。这里最后是一个简单的系列文章,它应该能让任何数据库专业人员快速“跟上”他们的步伐
第一个层次引入了SQL Server索引:使SQL Server能够在最少的时间内找到或修改请求数据的数据库对象,使用最少的系统资源来达到最大的性能。好的索引还允许SQL服务器实现最大的并发性,因此由一个用户运行的查询对其他用户运行的查询几乎没有影响。最后,索引提供了一种有效的方法来强制执行数据完整性,在创建唯一索引时保证键值的唯一性。这个级别是一个介绍;它涵盖了概念和用法,但将物理细节留给了稍后的层次。
对于数据库开发人员来说,对索引的深入理解对于一个以上的原因是非常重要的:当一个SQL Server请求从客户端到达时,SQL Server只有两种可能的方法来访问请求的行:
它可以扫描包含数据的表中的每一行,从第一行开始,一直到最后一行,检查每一行,看它是否满足请求标准。
或者,如果有一个有益的索引可用,它可以使用索引来定位所请求的数据。
第一个选项总是对SQL Server可用。如果您已经指示SQL Server创建一个有益的索引,那么第二个选项只能是可用的,但是它可以导致显著的性能改进,我们稍后将在这个层次上演示。
因为索引有与它们相关的开销(它们占用空间,它们必须与表保持同步),它们不需要SQL Server。有一个完全没有索引的数据库是可能的。它可能会表现得很差,它肯定会有数据完整性问题,但是SQL Server会允许它。
然而,这不是我们想要的。我们都想要一个性能良好的数据库,具有数据完整性,同时,将索引开销保持在最小值。这个水平将使我们朝着这个目标前进。
示例数据库
通过StairWay,我们将用例子来说明关键的概念。这些示例基于Microsoft AdventureWorks示例数据库。我们关注的是“销售订单“”的功能。5个表将提供事务性和非事务性数据的良好组合;客户,销售人员,产品,销售订单,和销售细节。为了保持注意力集中,我们使用了列的一个子集。
AdventureWorks是标准化的,所以销售人员信息被分解成三个表;销售人员、雇员和联系。对于一些示例,我们将它们作为单个表进行处理。我们将使用的完整的表集以及它们之间的关系如图1.1所示
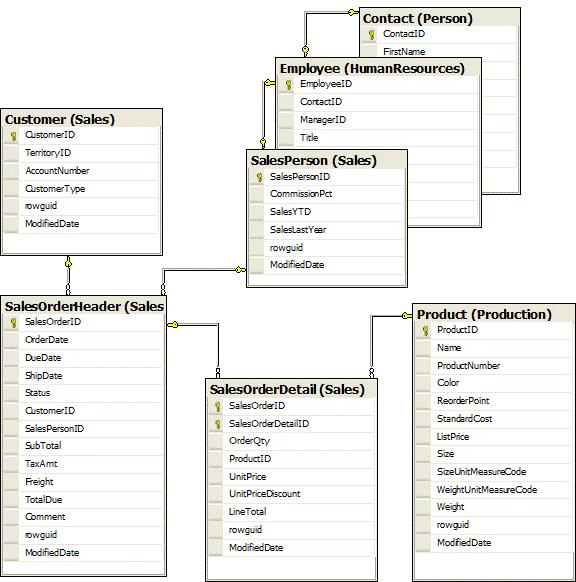
图1.1:将在此StairWay上使用的AdventureWorks表
注:
在这个阶梯级显示的所有TSQL代码都可以连同文章一起下载(参见本文底部的链接)
索引是什么?
我们从一个简短的故事开始我们的索引研究,它使用的是一个古老的,但经过验证的技术,我们将在本文中引用它来介绍索引的基本概念。
你离开家去办事。当你回来的时候,你会从你女儿的垒球教练那里得到一个信息。三名女孩,特雷西,丽贝卡和艾米已经失去了他们的球队帽子。你能不能在运动用品店转一下,给姑娘们买帽子。他们的父母会在下一场比赛中给你报销。
你认识那些女孩,你也认识他们的父母。但你不知道他们的帽子大小。在你镇上的某个地方有三个住宅,每个都包含你需要的信息。没问题,你就打电话给父母,把帽子的尺寸拿出来。你拿着你的手机,伸手去拿一个索引——你的电话簿的白页。
你需要到达的第一个居住地是海伦·迈耶。估计“迈耶”将位于人口中间,你就会跳到白页中间;只有发现你在页面上,标题写着“kline - koerber”。你向前跳跃,到达“nagle - nyeong”页面。在“maldonado - nagle”页面上,你可以看到一个更小的跳转。当你意识到你现在正处于正确的页面时,你会向下浏览页面,直到到达“Meyer,Helen”线,并获得电话号码。使用电话号码,你可以到达迈耶住所,获取你需要的信息。
你再重复这个过程两次,到达另外两个住处,再获得两个帽子大小。
您刚刚使用了一个索引,并且使用它的方式与SQL服务器使用索引的方式相同;因为在白页和SQL Server索引之间有很大的相似点和不同之处。
实际上,您刚才使用的索引代表了SQL Server支持的两个SQL Server索引类型:集群化和非集群化。白色页面最好表示非聚集索引的概念。因此,在这个级别,我们引入了非聚集索引。随后的级别将引入集群索引,并对这两种类型进行深入挖掘。
非聚集索引
白色页面类似于非聚集索引,因为它们不是数据本身的组织;但更确切地说,是一种机制,或者地图,来帮助你获取这些数据。数据本身就是我们需要联系的人。电话公司没有把城镇的住宅安排成一个有意义的顺序,把房子从一个地方搬到另一个地方,这样所有的女孩都住在同一个垒球队的隔壁,而房子不是由居民的姓组织的。相反,它会给你一本书,里面有每个住宅的入口。这些条目由白色页面的搜索键排序;姓,名,中间名和街道地址。每个条目包含搜索键和允许您访问该住所的数据块;电话号码。
就像进入白页一样,SQL Server非聚集索引中的每个条目由两个部分组成:
1、搜索键,如姓-名-中间名。在SQL Server术语中,这是索引键。
2、与电话号码相同用途的书签,允许SQL Server直接导航到表中对应于该索引条目的行。
此外,SQL Server非集群索引项有一些内部使用的头信息,可能包含一些可选信息。这两种方法都将在以后的水平上进行讨论;在这个时候,对非聚集索引的理解也不是很重要。
与白页一样,在搜索键序列中维护一个SQL Server索引,以便在一组小的“跳转”中访问任何特定的条目。给定搜索键,SQL Server可以快速获取该键的索引条目。与白页不同的是,SQL Server索引是动态的。也就是说,每次添加一行、删除或有修改的搜索键列值时,SQL服务器都会更新索引。
就像在白页里的条目顺序不同于城镇里的地理顺序一样;非聚集索引中的条目序列与表中的行序列不相同。索引中的第一个条目可能是表中的最后一行,而索引中的第二个条目可能是表中的第一行。如果事实,不像一个索引,它的条目总是有意义的序列;一个表的行可以完全没有排序。
当您创建一个索引时,SQL Server生成并在底层表中的每一行的索引中保持一个条目(当我们覆盖筛选的索引时,在以后的级别中会遇到这个一般规则的例外情况)。您可以在表上创建多个非聚集索引,但您不能有一个索引,该索引包含来自多个表的数据。
最大的区别是:SQL Server不能使用电话。它必须使用索引条目中的bookmark部分中的信息导航到表的相应行。每当SQL Server需要数据行中的任何信息,而不是对应的索引项,比如Tracy Meyer的垒球帽大小时,就需要这样做。因此,为了更好的类比,一个白页的条目包含一组GPS坐标而不是一个电话号码。然后使用GPS坐标导航到由白页条目表示的住所。
创建并从非聚集索引中受益
我们通过查询示例数据库来结束这个级别。请确保您使用的是用于SQL Server 2005的AdventureWorks版本,它可以被SQL Server 2008使用。AdventureWorks2008数据库有一个不同的表结构,下面的查询将会失败。我们每次都会运行相同的查询;但是,在创建表上的索引之前,第一个执行将会发生,第二个执行将在我们创建一个索引之后。每次,SQL Server都会告诉我们在检索请求信息时做了多少工作。我们将在我们的联系表中寻找“海伦·梅耶”排(她的排在桌子中间)。最初,表在FirstName列或LastName列上都没有索引。为了确保您能多次运行这个例子,请确保我们将在第三批处理的索引不存在,通过运行以下代码:
1 IF EXISTS (SELECT * FROM sys.indexes 2 WHERE OBJECT_ID = OBJECT_ID(\'Person.Contact\') 3 AND name = \'FullName\') 4 DROP INDEX Person.Contact.FullName;
清单1.1 -确保索引不存在
1 SET STATISTICS io ON 2 SET STATISTICS time ON 3 GO
清单1.2 -打开统计数据
上面的批处理通知SQL Server,我们希望我们的查询将性能信息作为输出的一部分返回。
第二个命令批处理:
1 SELECT * 2 FROM Person.Contact 3 WHERE FirstName = \'Helen\' 4 AND LastName = \'Meyer\'; 5 GO
清单1.3 -检索一些数据
第二批检索“海伦·迈耶”行:
584 Helen Meyer helen2@adventure-works.com 0-519-555-0112
加上以下的业绩信息:
Table \'Contact\'. Scan count 1, logical reads 569.
SQL Server Execution Times: CPU time = 3 ms.
这个输出告诉我们,我们的请求执行了569个逻辑ios,需要大约3毫秒的处理器时间。处理器时间的值可能不同。
第三个命令批处理:
1 CREATE NONCLUSTERED INDEX FullName
2 ON Person.Contact
3 ( LastName, FirstName );
4 GO
清单1.4—创建非聚集索引
此批处理在Contact表的第一个和最后一个名称列上创建一个非聚集的复合索引。复合索引是一个索引,包含多个列来确定索引行序列。
第四个命令批处理:
1 SELECT * 2 FROM Person.Contact 3 WHERE FirstName = \'Helen\' 4 AND LastName = \'Meyer\'; 5 GO
清单1.3(再一次)
这最后一批是我们最初的SELECT语句的重新执行。我们得到和以前一样的行;但这一次的性能统计数据是不同的
Table \'Contact\'. Scan count 1, logical reads 4.
SQL Server Execution Times: CPU time = 0 ms.
这个输出告诉我们,我们的请求只需要4个逻辑IOs;而且需要一个不可估量的少量处理器时间来检索“海伦·梅耶”行。
结论
创建良好的索引可以极大地提高数据库性能。在下一层,我们将开始研究索引的物理结构。我们将研究为什么这个非聚集索引对这个查询如此有利,为什么可能不总是这样。未来的级别将包括其他类型的索引、索引的额外收益、与索引相关的成本、监视和维护索引和最佳实践;所有的目标都是为您提供必要的知识,以便为您自己的数据库中的表创建最佳索引方案。
本文翻译网址:http://www.sqlservercentral.com/articles/Stairway+Series/72284/
以上是关于[翻译]——SQL Server索引的介绍:SQL Server索引级的阶梯的主要内容,如果未能解决你的问题,请参考以下文章