设随机Hash表的长度为n=8
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了设随机Hash表的长度为n=8相关的知识,希望对你有一定的参考价值。
1.设随机Hash表的长度为n=8。
设Hash码为i=mod(k*0.618,n)。将关键字元素序列(19,31,20,45,01,11,25,26)填入随机Hash表,并注明冲突次数。具体步骤,还有Hash码怎么看是哪个数字的呢
2.设线性Hash表的长度n=12,分别用下列Hash码将关键字元素序列(09,12,04,16,19,31,20,45,01,11,25,26)填入线性Hash表,并指出各关键字元素在填入过程中的冲突次数。
(1) i=mod(k,n)
(2) i=mod(k*0.618,n)
快且详细的有悬赏哟
1、设随机Hash表的长度为n=8。设Hash码为i=mod(k*0.618,n)。将关键字元素序列(19,31,20,45,01,11,25,26)填入随机Hash表,并注明冲突次数。
①计算关键字k的Hash码i0=i(k)。且令i=i0。
②伪随机数序列初始化,令j=1(即将取随机数指针指向伪随机数序列中的第1个随机数)。
③检查表中第i项的内容:若第i项为空,则将关键字k及有关信息填入该项;若第i项不空,则令i=mod(i0+ RN(j),n),并令j=j+1(即将取随机数指针指向下一个随机数),转③继续检查。其中RN(j)表示伪随机数序列RN中的第j个随机数。
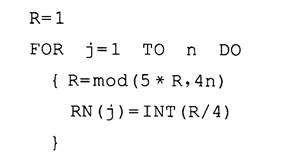
如图为取随机数的方法。
则过程为:
用取随机数的方法取得随机数。
可以用c++自动计算:
代码如下:
#include<iostream>using namespace std;
main()
int n = 8,R = 1;
int RN[8],j;
for(j=1;j<=n;j++)
R=(5*R)%(4*n);
RN[j]=int(R/4);
cout<<RN[j]<<endl;
结果为:1,6,7,4,5,2,3,0

看不清的点击下载excel

2.设线性Hash表的长度n=12,分别用下列Hash码将关键字元素序列(09,12,04,16,19,31,20,45,01,11,25,26)填入线性Hash表,并指出各关键字元素在填入过程中的冲突次数。
(1)i=mod(k,n)
(2)i=mod(k*0.618,n)
答:(1)i=mod(k,n)

(2)i=mod(k*0.618,n)

ES(Unix)
例子: IvS7aeT4NzQPM
说明:Linux或者其他linux内核系统中
长度: 13 个字符
描述:第1、2位为salt,例子中的'Iv'位salt,后面的为hash值
系统:MD5(Unix)
例子:$1$12345678$XM4P3PrKBgKNnTaqG9P0T/
说明:Linux或者其他linux内核系统中
长度:34个字符
描述:开始的$1$位为加密标志,后面8位12345678为加密使用的salt,后面的为hash
加密算法:2000次循环调用MD5加密
系统:SHA-512(Unix)
例子:$6$12345678$U6Yv5E1lWn6mEESzKen42o6rbEm
说明:Linux或者其他linux内核系统中
长度: 13 个字符
描述:开始的$6$位为加密标志,后面8位为salt,后面的为hash
加密算法:5000次的SHA-512加密
系统:SHA-256(Unix)
例子:$5$12345678$jBWLgeYZbSvREnuBr5s3gp13vqi
说明:Linux或者其他linux内核系统中
长度: 55 个字符
描述:开始的$5$位为加密标志,后面8位为salt,后面的为hash
加密算法:5000次的SHA-256加密
系统:MD5(APR)
例子:$apr1$12345678$auQSX8Mvzt.tdBi4y6Xgj.
说明:Linux或者其他linux内核系统中
长度:37个字符
描述:开始的$apr1$位为加密标志,后面8位为salt,后面的为hash
加密算法:2000次循环调用MD5加密
windows系统:
windows
例子:Admin:b474d48cdfc4974d86ef4d24904cdd91
长度:98个字符
加密算法:MD4(MD4(Unicode($pass)).Unicode(strtolower($username)))
mysql
系统:mysql
例子:606717496665bcba
说明:老版本的MySql中
长度:8字节(16个字符)
说明:包括两个字节,且每个字的值不超过0x7fffffff
系统:MySQL5
例子:*E6CC90B878B948C35E92B003C792C46C58C4AF40
说明:较新版本的MySQL
长度:20字节(40位)
加密算法:SHA-1(SHA-1($pass))
其他系统:
系统:MD5(WordPress)
例子:$P$B123456780BhGFYSlUqGyE6ErKErL01
说明:WordPress使用的md5
长度:34个字符
描述:$P$表示加密类型,然后跟着一位字符,经常是字符‘B’,后面是8位salt,后面是就是hash
加密算法:8192次md5循环加密
系统:MD5(phpBB3)
说明:phpBB 3.x.x.使用
例子:$H$9123456785DAERgALpsri.D9z3ht120
长度:34个字符
描述:开始的$H$为加密标志,后面跟着一个字符,一般的都是字符‘9’,然后是8位salt,然后是hash 值
加密算法:2048次循环调用MD5加密
系统:RAdmin v2.x
说明:Remote Administrator v2.x版本中
例子:5e32cceaafed5cc80866737dfb212d7f
长度:16字节(32个字符)
加密算法:字符用0填充到100字节后,将填充过后的字符经过md5加密得到(32位值)
md5加密
标准MD5
例子:c4ca4238a0b923820dcc509a6f75849b
使用范围:phpBB v2.x, Joomla 的 1.0.13版本前,及其他cmd
长度:16个字符
其他的加salt及变形类似:
md5($salt.$pass)
例子:f190ce9ac8445d249747cab7be43f7d5:12
md5(md5($pass))
例子:28c8edde3d61a0411511d3b1866f0636
md5(md5($pass).$salt)
例子:6011527690eddca23580955c216b1fd2:wQ6
md5(md5($salt).md5($pass))
例子: 81f87275dd805aa018df8befe09fe9f8:wH6_S
md5(md5($salt).$pass)
例子: 816a14db44578f516cbaef25bd8d8296:1234 参考技术B *nix系系统:
ES(Unix)
例子: IvS7aeT4NzQPM
说明:Linux或者其他linux内核系统中
长度: 13 个字符
描述:第1、2位为salt,例子中的'Iv'位salt,后面的为hash值
系统:MD5(Unix)
例子:$1$12345678$XM4P3PrKBgKNnTaqG9P0T/
说明:Linux或者其他linux内核系统中
长度:34个字符
描述:开始的$1$位为加密标志,后面8位12345678为加密使用的salt,后面的为hash
加密算法:2000次循环调用MD5加密
系统:SHA-512(Unix)
例子:$6$12345678$U6Yv5E1lWn6mEESzKen42o6rbEm
说明:Linux或者其他linux内核系统中
长度: 13 个字符
描述:开始的$6$位为加密标志,后面8位为salt,后面的为hash
加密算法:5000次的SHA-512加密
系统:SHA-256(Unix)
例子:$5$12345678$jBWLgeYZbSvREnuBr5s3gp13vqi
说明:Linux或者其他linux内核系统中
长度: 55 个字符
描述:开始的$5$位为加密标志,后面8位为salt,后面的为hash
加密算法:5000次的SHA-256加密
系统:MD5(APR)
例子:$apr1$12345678$auQSX8Mvzt.tdBi4y6Xgj.
说明:Linux或者其他linux内核系统中
长度:37个字符
描述:开始的$apr1$位为加密标志,后面8位为salt,后面的为hash
加密算法:2000次循环调用MD5加密
windows系统:
windows
例子:Admin:b474d48cdfc4974d86ef4d24904cdd91
长度:98个字符
加密算法:MD4(MD4(Unicode($pass)).Unicode(strtolower($username)))
mysql
系统:mysql
例子:606717496665bcba
说明:老版本的MySql中
长度:8字节(16个字符)
说明:包括两个字节,且每个字的值不超过0x7fffffff
系统:MySQL5
例子:*E6CC90B878B948C35E92B003C792C46C58C4AF40
说明:较新版本的MySQL
长度:20字节(40位)
加密算法:SHA-1(SHA-1($pass))
其他系统:
系统:MD5(WordPress)
例子:$P$B123456780BhGFYSlUqGyE6ErKErL01
说明:WordPress使用的md5
长度:34个字符
描述:$P$表示加密类型,然后跟着一位字符,经常是字符‘B’,后面是8位salt,后面是就是hash
加密算法:8192次md5循环加密
系统:MD5(phpBB3)
说明:phpBB 3.x.x.使用
例子:$H$9123456785DAERgALpsri.D9z3ht120
长度:34个字符
描述:开始的$H$为加密标志,后面跟着一个字符,一般的都是字符‘9’,然后是8位salt,然后是hash 值
加密算法:2048次循环调用MD5加密
系统:RAdmin v2.x
说明:Remote Administrator v2.x版本中
例子:5e32cceaafed5cc80866737dfb212d7f
长度:16字节(32个字符)
加密算法:字符用0填充到100字节后,将填充过后的字符经过md5加密得到(32位值)
md5加密
标准MD5
例子:c4ca4238a0b923820dcc509a6f75849b
使用范围:phpBB v2.x, Joomla 的 1.0.13版本前,及其他cmd
长度:16个字符
其他的加salt及变形类似:
md5($salt.$pass)
例子:f190ce9ac8445d249747cab7be43f7d5:12
md5(md5($pass))
例子:28c8edde3d61a0411511d3b1866f0636
md5(md5($pass).$salt)
例子:6011527690eddca23580955c216b1fd2:wQ6
md5(md5($salt).md5($pass))
例子: 81f87275dd805aa018df8befe09fe9f8:wH6_S
md5(md5($salt).$pass)
例子: 816a14db44578f516cbaef25bd8d8296:1234
随机排列单链表的前 N 个元素
【中文标题】随机排列单链表的前 N 个元素【英文标题】:Randomly permute N first elements of a singly linked list 【发布时间】:2010-12-12 12:31:07 【问题描述】:我必须随机排列长度为 n 的单链表的 N 个第一个元素。每个元素定义为:
typedef struct E_s
struct E_s *next;
E_t;
我有一个根元素,我可以遍历整个大小为 n 的链表。仅随机排列 N 个第一个元素(从根开始)的最有效技术是什么?
所以,给定 a->b->c->d->e->f->...x->y->z 我需要做点什么。比如 f->a->e->c->b->...x->y->z
我的具体情况:
n-N 大约是 n 的 20% 我的 RAM 资源有限,最好的算法应该到位 我必须在循环中进行多次迭代,所以速度很重要 不需要理想的随机性(均匀分布),“几乎”随机就可以 在进行排列之前,我已经遍历了 N 个元素(用于其他需要),所以也许我也可以将其用于排列更新:我找到了this paper。它指出它提出了一种 O(log n) 堆栈空间和预期 O(n log n) 时间的算法。
【问题讨论】:
std::random_shuffle 需要一个随机访问迭代器。单链表的迭代器不是随机访问。您需要先转换为数组。 高效是什么意思?你的问题是时间、空间还是两者兼而有之?您可以通过使用固定数量的内存并在移动到下一个元素时将指针反向指向前一个元素来遍历单链表... 我还没有读过论文,但是 O(log n) 空间和 O(n log n) 时间将很难被击败。 你会链接论文的 DOI 吗? ScienceDirect 链接已损坏。 @psihodelia:绝对清楚,您根本不关心元素 N+1...n,对吧?我想知道你为什么提到“n 中的第一个 N”——你的意思是说你想从 n 个元素中随机选择 N 个,将它们移到开头并排列该选择吗? 【参考方案1】:我没试过,但你可以使用“随机的merge-sort”。
更准确地说,您将merge-例程随机化。您没有系统地合并两个子列表,而是基于抛硬币来进行合并(即以 0.5 的概率选择第一个子列表的第一个元素,以 0.5 的概率选择正确的子列表的第一个元素)。
这应该在O(n log n) 中运行并使用O(1) 空间(如果实施得当)。
您可以在下面找到一个 C 中的示例实现,您可以根据自己的需要进行调整。请注意,此实现在两个地方使用随机化:splitList 和merge。但是,您可以只选择这两个地方之一。我不确定分布是否是随机的(我几乎可以肯定它不是),但一些测试用例产生了不错的结果。
#include <stdio.h>
#include <stdlib.h>
#define N 40
typedef struct _node
int value;
struct _node *next;
node;
void splitList(node *x, node **leftList, node **rightList)
int lr=0; // left-right-list-indicator
*leftList = 0;
*rightList = 0;
while (x)
node *xx = x->next;
lr=rand()%2;
if (lr==0)
x->next = *leftList;
*leftList = x;
else
x->next = *rightList;
*rightList = x;
x=xx;
lr=(lr+1)%2;
void merge(node *left, node *right, node **result)
*result = 0;
while (left || right)
if (!left)
node *xx = right;
while (right->next)
right = right->next;
right->next = *result;
*result = xx;
return;
if (!right)
node *xx = left;
while (left->next)
left = left->next;
left->next = *result;
*result = xx;
return;
if (rand()%2==0)
node *xx = right->next;
right->next = *result;
*result = right;
right = xx;
else
node *xx = left->next;
left->next = *result;
*result = left;
left = xx;
void mergeRandomize(node **x)
if ((!*x) || !(*x)->next)
return;
node *left;
node *right;
splitList(*x, &left, &right);
mergeRandomize(&left);
mergeRandomize(&right);
merge(left, right, &*x);
int main(int argc, char *argv[])
srand(time(NULL));
printf("Original Linked List\n");
int i;
node *x = (node*)malloc(sizeof(node));;
node *root=x;
x->value=0;
for(i=1; i<N; ++i)
node *xx;
xx = (node*)malloc(sizeof(node));
xx->value=i;
xx->next=0;
x->next = xx;
x = xx;
x=root;
do
printf ("%d, ", x->value);
x=x->next;
while (x);
x = root;
node *left, *right;
mergeRandomize(&x);
if (!x)
printf ("Error.\n");
return -1;
printf ("\nNow randomized:\n");
do
printf ("%d, ", x->value);
x=x->next;
while (x);
printf ("\n");
return 0;
【讨论】:
+1 基本上是正确的想法。我在回答中对此进行了扩展。但请注意,这至少使用O(log n) 堆栈空间进行递归。此外,这个特定的实现既不能保证使用有限的时间,也不能保证使用有限的空间。
更正O(log n) 堆栈空间。同样正确的是不能保证使用有限的时间和空间(尽管很有可能),但是您可以通过从 splitList 例程中删除随机化来确保这一点,对吧?
这段代码让我想起了为什么我在大学里喜欢 C,以及为什么它作为一种高级编程语言很糟糕。你忙于操纵指针,解决方案的精髓就丢失了。【参考方案2】:
转换为数组,使用Fisher-Yates shuffle,然后转换回列表。
【讨论】:
这并不容易,因为我没有太多额外的RAM空间(嵌入式平台)。而且名单很大。我必须置换 N 个元素,其中 n-N 相对于 n 足够小。 你为什么有这么大的链表(而且是单链表)? 好吧,在受限环境的情况下,这很有意义,因为您少了一个指针。当然,为什么在基于节点的容器占用内存时使用列表仍然是一个好问题。【参考方案3】:我认为没有任何有效的方法可以在没有中间数据结构的情况下随机打乱单链表。我只需将前 N 个元素读入一个数组,执行 Fisher-Yates shuffle,然后将前 N 个元素重构到单链表中。
【讨论】:
请阅读我的更新部分。似乎有一个有效的算法。 请注意,您实际上不必将元素本身放入数组中,只需将指向它们的指针即可。 嗯,这里的解决方案很好,但是空间限制。 Bellow 我有一个 O(1) 额外空间的解决方案,但我怀疑运行时是否接近 O(n log n)。 @psihodelia:O(n log n) 的效率低于我所介绍的。费舍尔耶茨只有 O(n)。但它使用更多内存。 @Peter - 不是 O(N),而不是 O(n)?重要的是被洗牌的元素数量,而不是列表中的元素数量。【参考方案4】:首先,获取列表的长度和最后一个元素。你说你在随机化之前已经做了一次遍历,那会是个好时机。
然后,通过将第一个元素链接到最后一个元素,将其变成一个循环列表。通过将大小除以四并迭代它进行第二次传递,获取列表中的四个指针。 (这些指针也可以通过在上一次遍历中每四次迭代递增一次、两次和三次从上一次遍历中获得。)
对于随机化过程,再次遍历并以 50% 的概率交换指针 0 和 2 以及指针 1 和 3。 (要么同时执行交换操作,要么都不执行;只有一个交换操作会将列表一分为二。)
这是一些示例代码。看起来它可能更随机一些,但我想多传几遍就可以了。无论如何,分析算法比编写它更困难 :vP 。对缺少缩进表示歉意;我只是在浏览器中将它打入ideone。
http://ideone.com/9I7mx
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
struct list_node
int v;
list_node *n;
list_node( int inv, list_node *inn )
: v( inv ), n( inn)
;
int main()
srand( time(0) );
// initialize the list and 4 pointers at even intervals
list_node *n_first = new list_node( 0, 0 ), *n = n_first;
list_node *p[4];
p[0] = n_first;
for ( int i = 1; i < 20; ++ i )
n = new list_node( i, n );
if ( i % (20/4) == 0 ) p[ i / (20/4) ] = n;
// intervals must be coprime to list length!
p[2] = p[2]->n;
p[3] = p[3]->n;
// turn it into a circular list
n_first->n = n;
// swap the pointers around to reshape the circular list
// one swap cuts a circular list in two, or joins two circular lists
// so perform one cut and one join, effectively reordering elements.
for ( int i = 0; i < 20; ++ i )
list_node *p_old[4];
copy( p, p + 4, p_old );
p[0] = p[0]->n;
p[1] = p[1]->n;
p[2] = p[2]->n;
p[3] = p[3]->n;
if ( rand() % 2 )
swap( p_old[0]->n, p_old[2]->n );
swap( p_old[1]->n, p_old[3]->n );
// you might want to turn it back into a NULL-terminated list
// print results
for ( int i = 0; i < 20; ++ i )
cout << n->v << ", ";
n = n->n;
cout << '\n';
【讨论】:
【参考方案5】:对于 N 非常大的情况(所以它不适合您的记忆),您可以执行以下操作(一种 Knuth 的 3.4.2P):
-
j = N
k = 1 到 j 之间的随机数
遍历输入列表,找到第k项并输出;从序列中删除所述项目(或以某种方式标记它,以便您在下一次遍历时不会考虑它)
减小 j 并返回 2,除非 j==0
输出列表的其余部分
请注意,这是 O(N^2),除非您可以在步骤 3 中确保随机访问。
如果 N 相对较小,以便 N 个项目适合内存,只需将它们加载到数组中并随机播放,就像 @Mitch 建议的那样。
【讨论】:
【参考方案6】:如果你同时知道 N 和 n,我认为你可以简单地做到这一点。这也是完全随机的。您只需遍历整个列表一次,并在每次添加节点时遍历随机部分。我认为这是 O(n+NlogN) 或 O(n+N^2)。我不知道。它基于在给定先前节点发生的情况下更新为随机部分选择节点的条件概率。
-
根据先前节点发生的情况确定某个节点将被随机选择的概率 (p=(N-size)/(n-position) 其中 size 是先前选择的节点数,position 是之前考虑过的节点)
如果没有为随机部分选择节点,则转到步骤 4。如果为随机部分选择了节点,则根据到目前为止的大小在随机部分中随机选择位置 (place=(random between 0 and 1) * size , size 又是先前节点的数量)。
将节点放在需要去的地方,更新指针。增加大小。改为查看之前指向您正在查看和移动的内容的节点。
增加位置,看下一个节点。
我不会 C,但我可以给你伪代码。在此,我将排列称为随机化的第一个元素。
integer size=0; //size of permutation
integer position=0 //number of nodes you've traversed so far
Node head=head of linked list //this holds the node at the head of your linked list.
Node current_node=head //Starting at head, you'll move this down the list to check each node, whether you put it in the list.
Node previous=head //stores the previous node for changing pointers. starts at head to avoid asking for the next field on a null node
While ((size not equal to N) or (current_node is not null)) //iterating through the list until the permutation is full. We should never pass the end of list, but just in case, I include that condition)
pperm=(N-size)/(n-position) //probability that a selected node will be in the permutation.
if ([generate a random decimal between 0 and 1] < pperm) //this decides whether or not the current node will go in the permutation
if (j is not equal to 0) //in case we are at start of list, there's no need to change the list
pfirst=1/(size+1) //probability that, if you select a node to be in the permutation, that it will be first. Since the permutation has
//zero elements at start, adding an element will make it the initial node of a permutation and percent chance=1.
integer place_in_permutation = round down([generate a random decimal between 0 and 1]/pfirst) //place in the permutation. note that the head =0.
previous.next=current_node.next
if(place_in_permutation==0) //if placing current node first, must change the head
current_node.next=head //set the current Node to point to the previous head
head=current_node //set the variable head to point to the current node
else
Node temp=head
for (counter starts at zero. counter is less than place_in_permutation-1. Each iteration, increment counter)
counter=counter.next
//at this time, temp should point to the node right before the insertion spot
current_node.next=temp.next
temp.next=current_node
current_node=previous
size++ //since we add one to the permutation, increase the size of the permutation
j++;
previous=current_node
current_node=current_node.next
如果您保留最近添加的节点,以防您必须在其右侧添加一个节点,您可能会提高效率。
【讨论】:
【参考方案7】:与弗拉德的回答类似,这里有一点改进(统计上):
算法中的索引是基于 1 的。
-
初始化 lastR = -1
如果 N
在 1 和 N 之间随机化数字 r。
如果 r != N
4.1 遍历列表到项目 r 及其前身。
If lastR != -1
If r == lastR, your pointer for the of the r'th item predecessor is still there.
If r < lastR, traverse to it from the beginning of the list.
If r > lastR, traverse to it from the predecessor of the lastR'th item.
4.2 将列表中的第 r 个项目作为尾部删除到结果列表中。
4.3 lastR = r
将 N 减 1 并转到第 2 步。 将结果列表的尾部链接到剩余输入列表的头部。您现在拥有前 N 项排列的原始列表。由于您没有随机访问权限,这将减少您在列表中所需的遍历时间(我假设减半,因此渐近地,您不会获得任何东西)。
【讨论】:
运行时间为 O(N^2)。 我知道...我没有说它是线性的。它只是在统计上稍微好一点,因为它将在大约一半的时间内运行。仍然是 O(N^2)。【参考方案8】:O(NlogN) 易于实施的解决方案,不需要额外的存储空间:
假设你想随机化 L:
是 L 有 1 或 0 个元素你就完成了
创建两个空列表 L1 和 L2
遍历 L,破坏性地将其元素移动到 L1 或 L2,在两者之间随机选择。
对 L1 和 L2 重复该过程(递归!)
将 L1 和 L2 加入 L3
返回 L3
更新
在第 3 步,应将 L 划分为大小相等 (+-1) 的列表 L1 和 L2,以保证最佳情况复杂度 (N*log N)。这可以通过动态调整一个元素进入 L1 或 L2 的概率来完成:
p(insert element into L1) = (1/2 * len0(L) - len(L1)) / len(L)
在哪里
len(M) is the current number of elements in list M
len0(L) is the number of elements there was in L at the beginning of step 3
【讨论】:
这使用来自递归的预期 O(log(N)) 最坏情况 O(N) 堆栈空间。 在实践中,最坏情况的 O(N) 内存使用(以及 O(N*N) 复杂度)不会发生在常见的伪数生成器中。 重点在于它不需要额外存储空间的说法是错误的。事实上,它至少会递归 log(n) 次,因此至少需要一些 log(n) 额外存储的常数因子。 @Chris Hopman:哦,好吧,你是对的,但是当谈到内存时,log(N) 是如此微不足道,我通常会忽略它。无论如何,该算法可以转换为具有实际 O(1) 内存使用的迭代形式。 @Chris Hopman:关于复杂度 O(NlogN) 和内存 O(1) 的迭代版本,请参阅我在同一线程中的另一篇文章。【参考方案9】:有一个算法需要 O(sqrt(N)) 空间和 O(N) 时间,用于单链表。
它不会在所有排列序列上生成均匀分布,但它可以提供不易区分的良好排列。基本思想类似于按行和列排列矩阵,如下所述。
算法
让元素的大小分别为N和m = floor(sqrt(N))。假设一个“方阵”N = m*m 将使这个方法更加清晰。
在第一遍中,您应该将由每个m 元素分隔的元素的指针存储为p_0, p_1, p_2, ..., p_m。也就是说,p_0->next->...->next(m times) == p_1 应该是真的。
排列每一行
对于 i = 0 到 m 做: 按大小为O(m) 的数组索引链接列表中p_i->next 到p_(i+1)->next 之间的所有元素
使用标准方法随机播放此数组
使用这个打乱的数组重新链接元素
排列每一列。
初始化数组A以存储指针p_0, ..., p_m。用于遍历列
对于 i = 0 到 m 做
用大小为m 的数组索引链接列表中指向A[0], A[1], ..., A[m-1] 的所有元素
随机播放此数组
使用这个打乱的数组重新链接元素
将指针前进到下一列A[i] := A[i]->next
请注意,p_0 是指向第一个元素的元素,p_m 指向最后一个元素。此外,如果N != m*m,您可以使用m+1 分隔一些p_i。现在你得到一个“矩阵”,使得p_i 指向每一行的开头。
分析和随机性
空间复杂度:该算法需要O(m) 空间来存储行的开头。 O(m) 用于存储数组的空间和O(m) 用于在列置换期间存储额外指针的空间。因此,时间复杂度约为 O(3*sqrt(N))。对于N = 1000000,大约有 3000 个条目和12 kB 内存。
时间复杂度:显然是O(N)。它要么逐行或逐列遍历“矩阵”
随机性:首先要注意的是,每个元素都可以通过行和列排列到达矩阵中的任何位置。元素可以到达链表中的任何位置是非常重要的。其次,虽然它不会生成所有的排列序列,但它确实会生成其中的一部分。为了找到排列的数量,我们假设N=m*m,每个行排列有m!,并且有m行,所以我们有(m!)^m。如果还包括列置换,则正好等于(m!)^(2*m),因此几乎不可能得到相同的序列。
强烈建议重复第二步和第三步至少一次,以获得更随机的序列。因为它可以抑制几乎所有的行和列关联到它原来的位置。当您的列表不是“方形”时,这一点也很重要。取决于您的需要,您可能想要使用更多的重复。你使用的重复次数越多,它的排列就越多,它就越随机。我记得可以为N=9 生成均匀分布,并且我想可以证明随着重复趋于无穷大,它与真正的均匀分布相同。
编辑:时间和空间复杂度是严格限制的,在任何情况下都几乎相同。我认为这种空间消耗可以满足您的需求。如果您有任何疑问,您可以在一个小列表中尝试一下,我认为您会发现它很有用。
【讨论】:
【参考方案10】:下面的列表随机化器的复杂度为 O(N*log N),内存使用量为 O(1)。
它基于我在另一篇文章中描述的递归算法,修改为迭代而不是递归,以消除 O(logN) 内存使用。
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
typedef struct node
struct node *next;
char *str;
node;
unsigned int
next_power_of_two(unsigned int v)
v--;
v |= v >> 1;
v |= v >> 2;
v |= v >> 4;
v |= v >> 8;
v |= v >> 16;
return v + 1;
void
dump_list(node *l)
printf("list:");
for (; l; l = l->next) printf(" %s", l->str);
printf("\n");
node *
array_to_list(unsigned int len, char *str[])
unsigned int i;
node *list;
node **last = &list;
for (i = 0; i < len; i++)
node *n = malloc(sizeof(node));
n->str = str[i];
*last = n;
last = &n->next;
*last = NULL;
return list;
node **
reorder_list(node **last, unsigned int po2, unsigned int len)
node *l = *last;
node **last_a = last;
node *b = NULL;
node **last_b = &b;
unsigned int len_a = 0;
unsigned int i;
for (i = len; i; i--)
double pa = (1.0 + RAND_MAX) * (po2 - len_a) / i;
unsigned int r = rand();
if (r < pa)
*last_a = l;
last_a = &l->next;
len_a++;
else
*last_b = l;
last_b = &l->next;
l = l->next;
*last_b = l;
*last_a = b;
return last_b;
unsigned int
min(unsigned int a, unsigned int b)
return (a > b ? b : a);
randomize_list(node **l, unsigned int len)
unsigned int po2 = next_power_of_two(len);
for (; po2 > 1; po2 >>= 1)
unsigned int j;
node **last = l;
for (j = 0; j < len; j += po2)
last = reorder_list(last, po2 >> 1, min(po2, len - j));
int
main(int len, char *str[])
if (len > 1)
node *l;
len--; str++; /* skip program name */
l = array_to_list(len, str);
randomize_list(&l, len);
dump_list(l);
return 0;
/* try as: a.out list of words foo bar doz li 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
*/
请注意,这个版本的算法对缓存完全不友好,递归版本可能会执行得更好!
【讨论】:
【参考方案11】:如果以下两个条件都为真:
您有足够的程序内存(许多嵌入式硬件直接从闪存执行); 您的解决方案不会因为您的“随机性”经常重复而受到影响,然后您可以选择在编程时定义的足够大的特定排列集,编写代码来编写实现每个排列的代码,然后在运行时对其进行迭代。
【讨论】:
以上是关于设随机Hash表的长度为n=8的主要内容,如果未能解决你的问题,请参考以下文章
为什么Java的hash表的长度一直是2的指数次幂?为什么这个(hash&(h-1)=hash%h)位运算公式等价于取余运算?