深入TLS/SSL协议
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入TLS/SSL协议相关的知识,希望对你有一定的参考价值。
TLS/SSL 协议是为了解决网络通讯中的信息安全问题而诞生的。它的设计目的主要有三个:
TLS/SSL 协议主要包含两部分:
对称加密算法是指在加密和解密过程中使用相同的密钥。
举例:
张三在与李四通讯时为了防止第三方窃听,使用莫斯密码将通讯内容加密。李四接收到通讯内容后,使用相同的莫斯密码将内容解密。
因为使用了相同的莫斯密码,所以这属于对称加密。
网络通讯中的对称加密之所以能够使用相同的密钥对内容进行加/解密,是因为使用了异或运算。
在数学领域中异或运算:当两两数值相同为否,而数值不同时为真。
举例:
现有一把密钥:1010,与明文:0110。
可见 XOR 异或运算是对称加密的关键!
优点:
缺点:
异或运算要求双方长度一致的这个缺点要怎么解决呢?聪明的同学或许已经想到解决方法了:就是将明文划分为多个等长的块。
比如密钥为16字节的,那就将明文划分为多个16字节的块,分别用密钥对这些明文块进行加解密。
Block cipher 分组加密原理就是这样:将明文划分为多个等长的 Block 块,对每一个 Block 块分别加解密。
但并不是所有的明文都能恰好的划分为16字节的块。这时就需要填充!
填充的目的:
填充主要有两种方法:
其中字节填充有4种填充方式:
对明文进行分组、填充后,还要按照一定的规律或方法进行加/解密。这些规律或者方法就是工作模式。
分组工作模式: block cipher mode of operation
1、 电子密码本 ECB 模式-- Electronic codebook
就是直接将明文分解为多个块,对每个块进行加密。
这种工作方法非常简单、快速。但是缺点在于同样的明文块会被加密成相同的密文块;因此,它不能很好的隐藏数据模式。
举例:
对图片进行 ECB 之后,是无法隐藏到图像的轮廓特性的。如下图所示:
CTR 模式同样存在问题:无法提供密文的完整性校验。当密文在传输过程中存在丢失的情况下,是无法保证密文的完整性的。
MAC 算法-- Message Authentication Code 。
MAC 算法能够实现消息的完整性校验。工作原理是基于hash函数的。
hash 函数是一种从任何一种数据中创建小的数字“指纹”的方法。 hash 函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。
简而言之就是:无论输入多长的字符串,通过 hash 函数,都能得到定长较短的字符串。
MAC 工作流程如图所示:
CTR 分组工作模式加上 MAC 算法就诞生了 GCM 分组工作模式。
高级加密标准 AES 算法-- Advanced Encryption Standard
AES 的分组 Block 块长度固定为128比特,也就是16字节。
密钥长度则可以是128,192或256比特。
所以从上图中看出,分组长度128比特分为4个32比特。而不同长度的密钥则分为4、6. 8组32位比特的矩阵。
AES 加密流程:如图所示
10轮加密可分为初始轮、普通轮和最终轮。
addRoundKey 轮密钥加
SubBytes 字节替代
ShiftRows 行移位
对称加密的最大的问题是怎么把密钥传递给对方。非对称密码可以实现密钥的安全传递。
每一个参与方都有一对密钥:
非对称加解密过程:
举例:
张三要和李四通讯
第一步:张三用李四的公钥进行加密,将密文发送给李四。
第二步:李四用自己的私钥进行解密。
密文是无法通过公钥解密的,只有私钥才能解密。
张三怎么拿到李四的公钥?有两种办法:
RSA 是基于公开密钥密码体制的。
公开密钥密码体制是一种“由已知加密密钥推导出解密密钥在计算上是不可行的”密码体制。
RSA 算法中公私钥的产生:
RSA 的安全性依赖于大数因数分解非常非常困难,也就是通过一个大数 n 是非常难的分解出 p 和 q 。
RSA 算法的加解密流程:如下图所示
由于进行大量的大数乘法运算,RSA的速度是对应同样安全级别的对称密码算法的1/1000左右。
PKI 是非对称密码学的一个非常重要的应用。
基于私钥加密,只能使用公钥解密的原理实现身份验证的作用。
签名与验签的流程
签名:
验签:
证书类型:
从加密安全性上看,三类证书的保密性都是一样的,只有在站长的个人信息验证上有所不同。
上面说到张三有两种办法可以拿到李四的公钥:
RSA 算法一般是第一种方法中用于 CA 机构的身份验证上的。事实上 RSA 算法用于第二种方法也是可行的。
举例:
张三与李四建立链接。李四用RSA算法生成一对公私钥,在握手中李四将公钥传递给张三。然后张三将对称加密的密钥用公钥进行加密后传递给李四,李四用私钥解密得到密钥。
就算第三方拿到公钥,没有私钥是无法解密密文的。
但这种方式有一个缺点:没有前向保密性。
也就是说当第三方将通讯的报文全部保存下来后,在破解出私钥之后,就能知道所有密文内容。
而 DH 密钥交换协议就解决了这个问题。它可以双方在完全没有对方任何预先信息的条件下通过不安全信道创建起一个密钥。所以每一次通讯中密钥都是实时生成的
具体流程:
DH密钥交互协议的原理:
DH 交换协议的问题:容易遭到中间人伪造攻击。
简单来说:第三方假装自己是张三向李四进行一次 DH 密钥交换,然后又假装李四向张三进行一个 DH 密钥交换。就可以知道密钥 K 。
解决这个方法很简单,就是使用 PKI 公钥基础体系中的身份验证。第三方就无法假装李四这个站长了。
从图中看出 DH 协议也涉及到大量的大数乘法运算,速度也是非常慢的。而目前使用的 DH 密钥交换协议是基于 ECC 椭圆曲线加持过的,速度非常的快。称为 ECDHE 密钥交换算法。具体细节可以自己去搜索查询。
TLS1.2 中经常使用的一个安全套件是:
TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
具体说明一下:
分组密码工作模式 --wiki
高级加密标准 --wiki
RSA算法 --wiki
DH密钥交换协议 --wiki
《计算机网络:自顶向下方法》
Web协议详解与抓包实战--陶辉 参考技术A SSl/TLS是一种安全协议。
SSLSecureSocketsLayer)及其继任者传输层安全(TransportLayerSecurity,TLS)是为网络通信提供安全及数据完整性的一种安全协议。TLS与SSL在传输层对网络连接进行加密。
SSL为Netscape所研发,用以保障在Internet上数据传输之安全,利用数据加密技术,可确保数据在网络上之传输过程中不会被截取及窃听。一般通用之规格为40bit之安全标准,美国则已推出128bit之更高安全标准,但限制出境。
SSL协议位于TCP/IP协议与各种应用层协议之间,为数据通讯提供安全支持。广泛地用于Web浏览器与服务器之间的身份认证和加密数据传输。 参考技术B 传输层安全(TLS)是SSL的后继协议。TLS是SSL的改进版本。它的工作方式与SSL基本相同,使用加密来保护数据和信息的传输。尽管SSL仍然被广泛使用,但这两个术语在行业中经常互换使用。
深入理解 WEB协议HTTP2
一、http2 连接的建立
和许多人的固有印象不同的是http2协议本身并没有规定必须建立在tls/ssl之上,其实用普通的tcp连接也可以完成http2连接的建立。只不过现在为了安全市面上所有的浏览器都仅默认支持基于tls/ssl的http2协议。简单来说我们可以把构建在tcp连接之上的http2协议称之为h2c,而构建在tls/ssl协议之上的就可以理解为是h2了。
输入命令:
tcpdump -i eth0 port 80 and host nghttp2.org -w h2c.pcap &然后用curl访问基于tcp连接,也就是port 80端口的 http2站点(这里是没办法用浏览器访问的,因为浏览器不允许)
curl http://nghttp2.org --http2 -v其实看日志也可以大致了解一下这个连接建立的过程:
我们将tcpdump出来的pcap文件拷贝到本地,然后用Wireshark打开以后还原一下整个http2连接建立的报文:
首先是 http 1.1 升级到 http2 协议
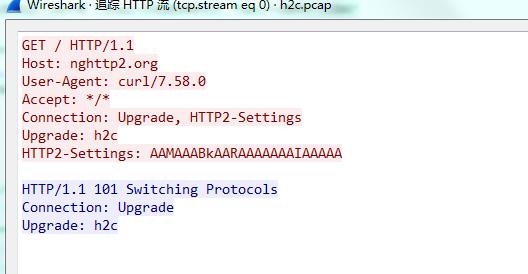
然后客户端还需要发送一个“魔法帧”:
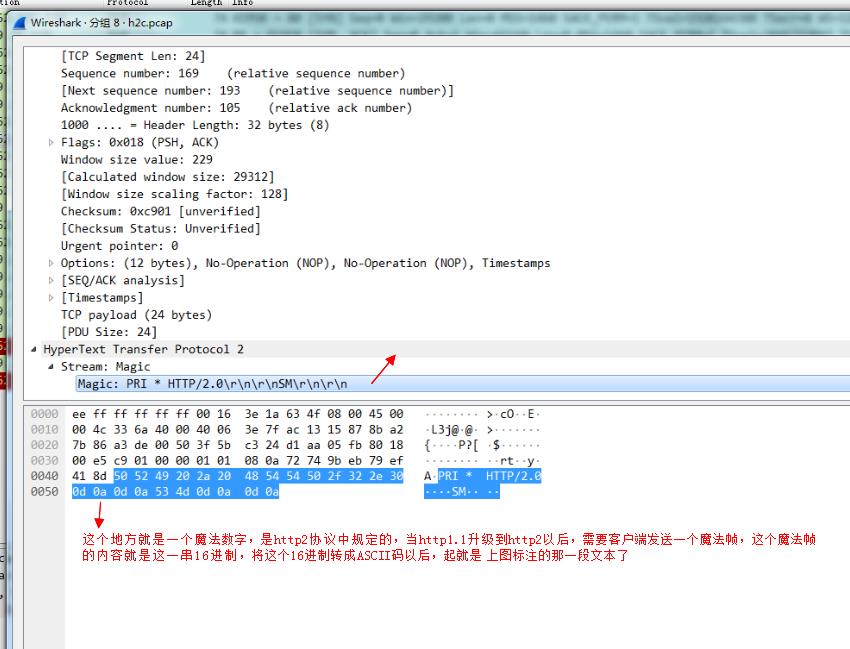
最后还需要发送一个设置帧:
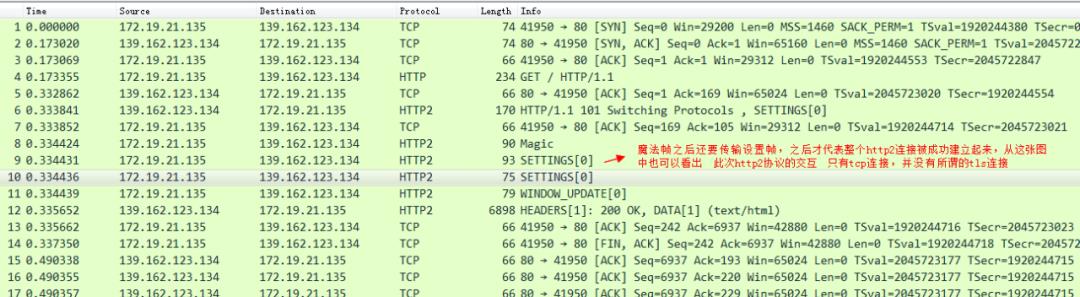
之后,我们来看一下,基于tls的http2连接是如何建立的,考虑到加密等因素,我们需要提前做一些准备工作。可以在chrome中下载这个插件。

然后打开任意一个网页只要看到这个闪电的图标为蓝色就代表这个站点支持http2;否则不支持。如下图:
将chrome浏览器的tls/ssl之类的信息 输出到一个日志文件中,需要额外配置系统变量,如图所示:
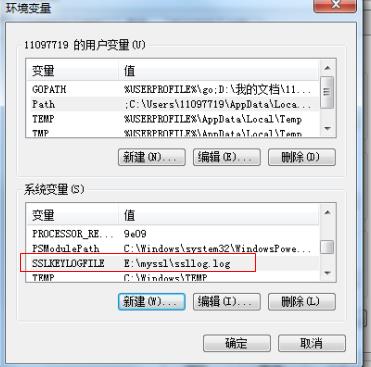
然后将我们的Wireshark中ssl相关的设置也进行配置。
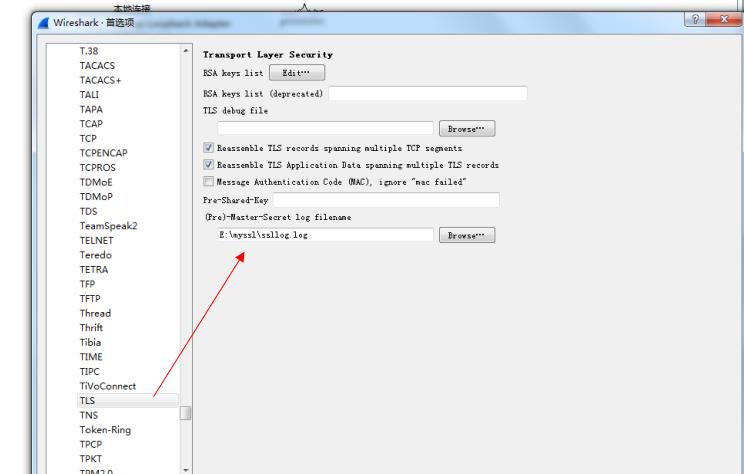
这样浏览器在进行tls协议交互的时候,相关的加密解密信息都会写入到这个log文件中,我们的Wireshark就会用这个log文件中的信息来解密出我们的tls报文。
有了上述的基础,我们就可以着手分析基于tls连接的http2协议了。比如我们访问tmall的站点 https://www.tmall.com/ 然后打开我们的Wireshark。
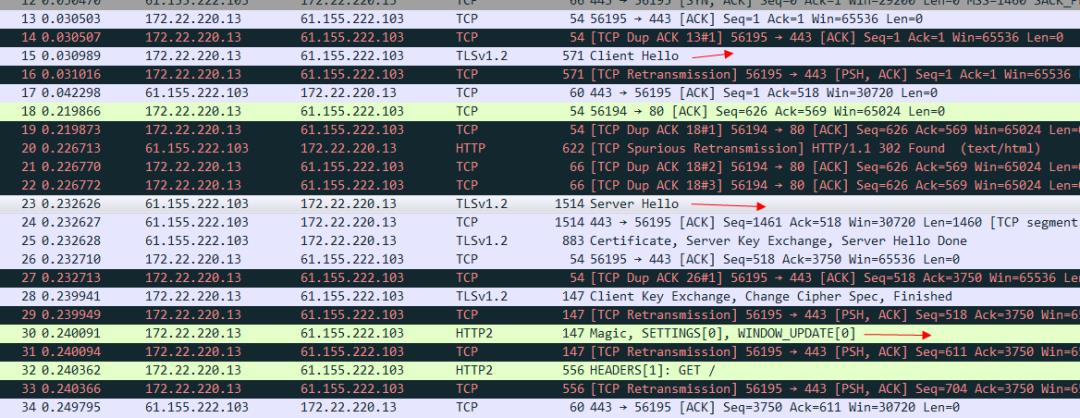
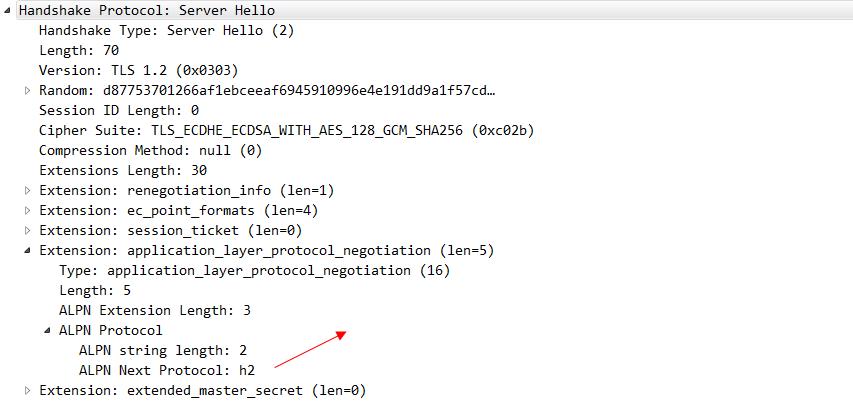
看一下标注的地方可以看出来,是tls连接建立以后 然后继续发送魔法帧和设置帧,才代表http2的连接真正建立完毕。我们看一下tls报文的client hello 这个信息:

其中这个alpn协议的信息 就代表客户端可以接受哪两种协议。server hello 这个消息 就明确的告知 我们要使用h2协议。
这也是http2相比spdy协议最重要的一个优点:spdy协议强依赖tls/ssl,服务器没有任何选择。而http2协议则会在客户端发起请求的时候携带alpn这个扩展,也就是说客户端发请求的时候会告诉服务端我支持哪些协议。从而可以让服务端来选择,我是否需要走tls/ssl
二、http2 中帧和流的关系
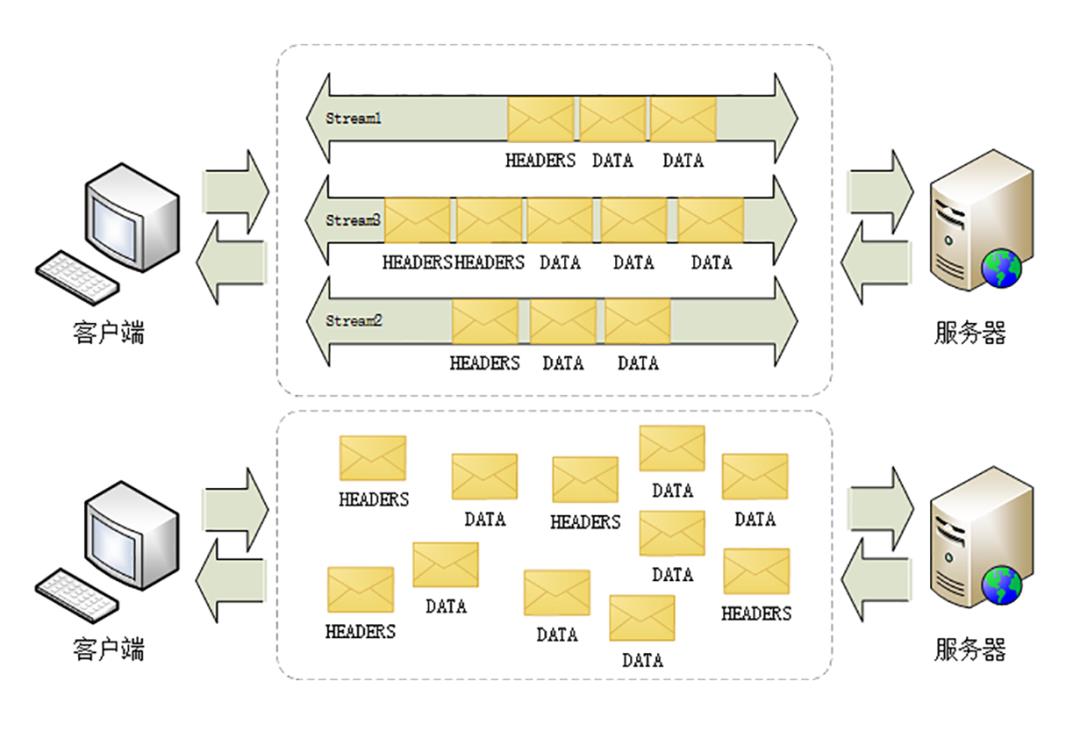
简单来说,http2就是在应用层上模拟了一下传输层tcp中“流”的概念,从而解决了http1.x协议中的队头拥塞的问题,在1.x协议中,http协议是一个个消息组成的,同一条tcp连接上,前面一个消息的响应没有回来,后续的消息是不可以发送的。在http2中,取消了这个限制,将所谓的“消息”定义成“流”,流跟流之间的顺序可以是错乱的,但是流里面的帧的顺序是不可以错乱的。如图:
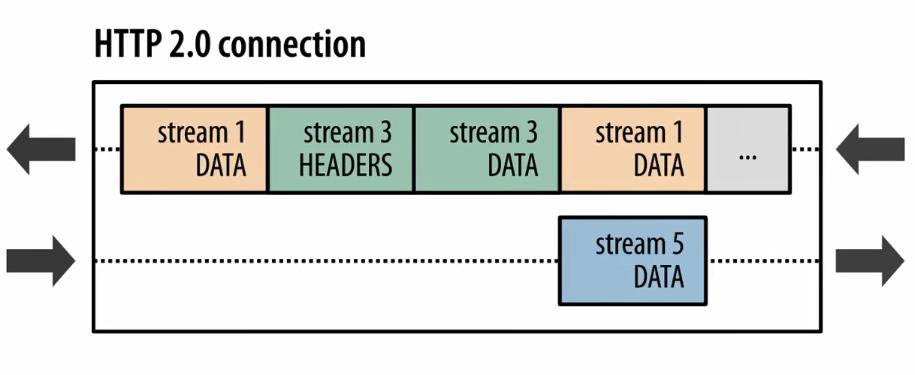
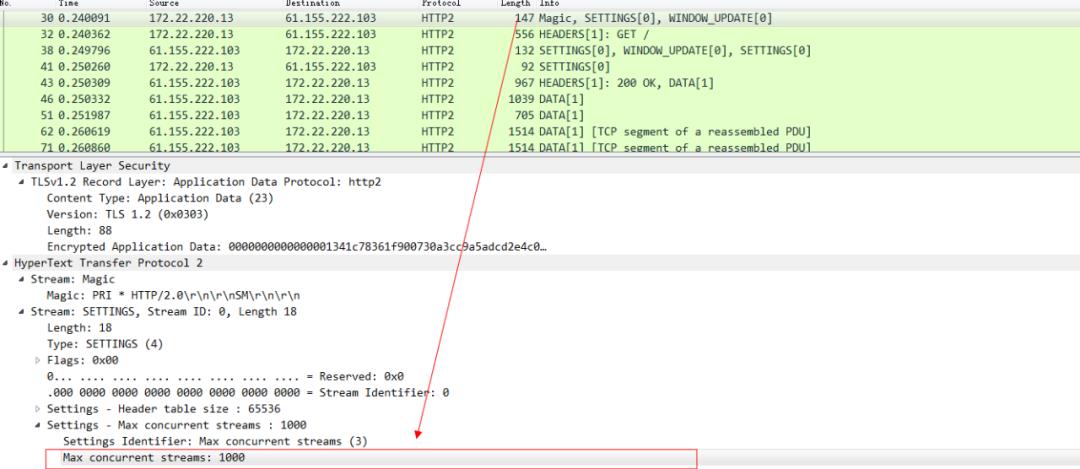
也就是说在同一条tcp连接上,可以同时存在多个stream流,这些流 由一个个frame帧组成,流跟流之间没有顺序关系,但是每一个流内部的帧是有先后顺序的。注意看这张图中的 135 等数字其实就是stream id,websocket中虽然也有帧的概念,但是因为websocket中没有stream id,所以websocket是没有多路复用的功能的。http2因为有了stream id所以就有了多路复用的能力。可以在一条tcp连接上存在n个流,就意味着服务端可以同时并发处理n个请求然后同时将这些请求都响应到同一条tcp连接上。当然这种在同一条tcp连接上传送n个stream的能力也是有限制的,在http2连接建立的时候,setting帧 中会包含这个设置信息。例如下图 在访问天猫的站点的时候,浏览器携带的setting帧的消息里面就标识了 浏览器这个http2的客户端可以支持并发最大的流为1000。
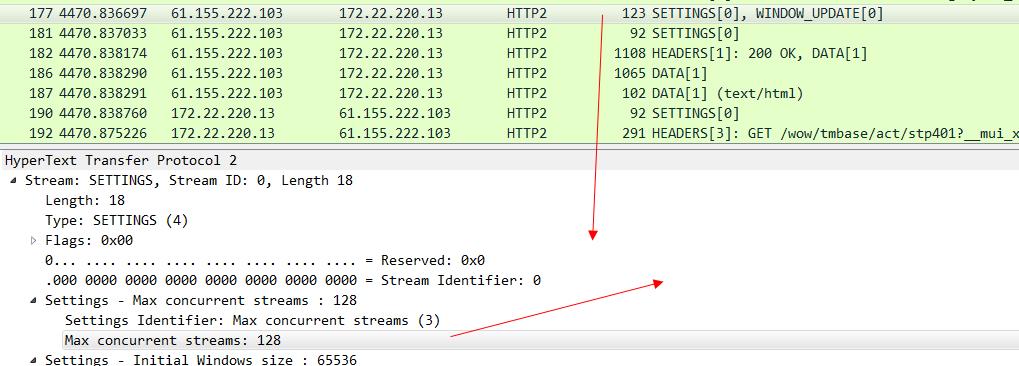
当天猫服务器返回这个setting帧的响应的时候,就告知了浏览器,我能支持的最大并发stream为128。
同时 我们也要知道,http2协议中 流id为单数就代表是客户端发起的流,偶数代表服务端主动发起的流(可以理解为服务端主动推送)。
三、 http2 中流量节省的奥秘:HPACK 算法
相比与http1.x协议,http2协议还在流量消耗上做了极大改进。主要分为三块:静态字典,动态字典,和哈夫曼编码. 可以安装如下工具探测一下 对流量节省的作用:
apt-get install nghttp2-client然后可以探测一下一些已经开启http2的站点,基本上节约的流量都是百分之25起,如果频繁访问的话 会更多:
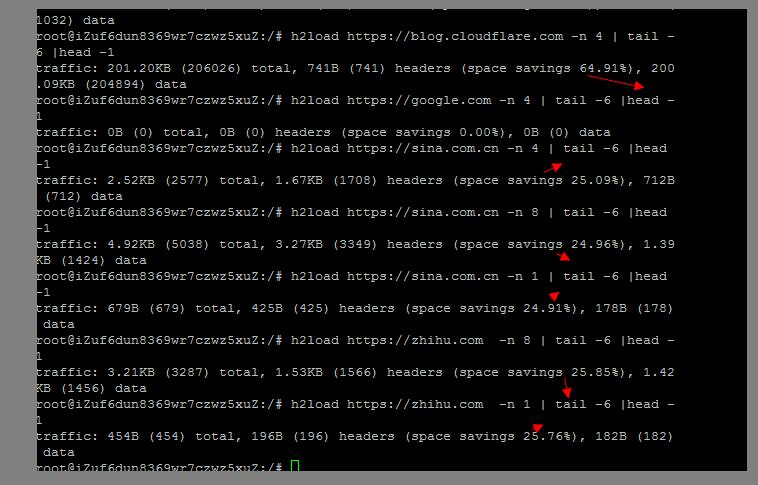
对于流量消耗来说,其实http2相比http1.x协议最大的改进就是在http2中我们可以对http的头部进行压缩了,而在以往http 1.x协议中,gzip等是无法对header进行压缩的,尤其对于绝大多数的请求来说,其实header的占比是最大的。
我们首先来了解一下静态字典,如图所示:
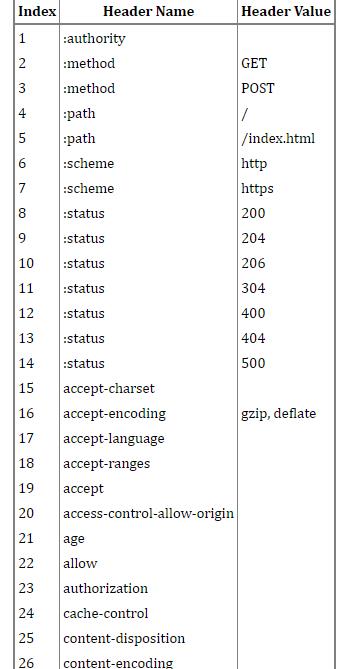
这个其实不难理解,无非就是将我们那些常用的http头部,用固定的数字来表示,那当然可以起到节约流量的作用.这里要注意的是 有些value 情况比较复杂的header,他们的value 是没有做静态字典的。比如cache-control这个缓存控制字段,这后面的值因为太多了就无法用静态字典来解决,而只能靠霍夫曼编码。下图可以表示 HPACK这种压缩算法 起到的节约流量的作用:
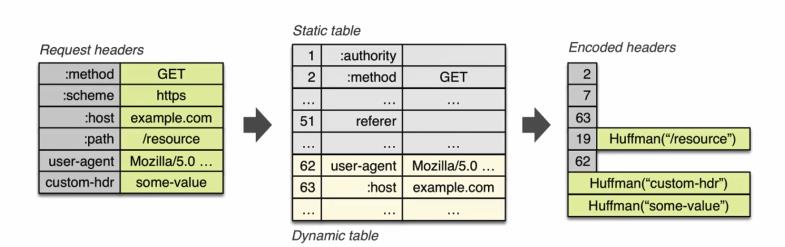
例如,我们看下62这个 头部,user-agent 代指浏览器,一般我们请求的时候这个头部信息都是不会变的,所以最终经过hpack算法优化以后 后续再传输的时候 就只需要传输62这个数字就可以代表其含义了。
又例如下图:
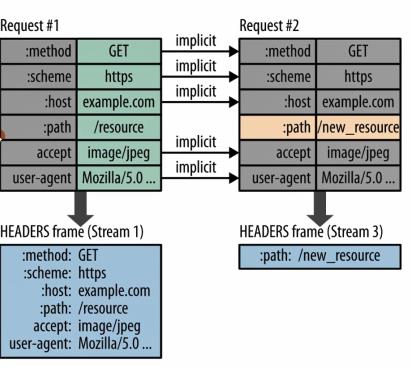
也是一样的,多个请求连续发送的时候,多数情况下变化的只有path,其余头部信息是不变的,那么基于此场景,最终传输的时候也就只有path这一个头部信息了。
最后我们来看看hpack算法中的核心:哈夫曼编码。哈弗曼编码核心思想就是出现频率较高的用较短的编码,出现频率较低的用较长的编码(http2协议的前身spdy协议采用的是动态的哈夫曼编码,而http2协议则选择了静态的哈夫曼编码)。
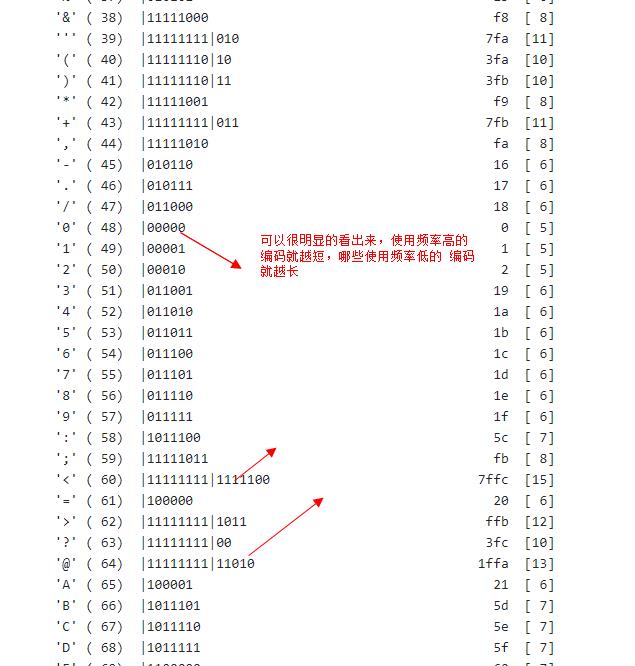
来看几个例子:
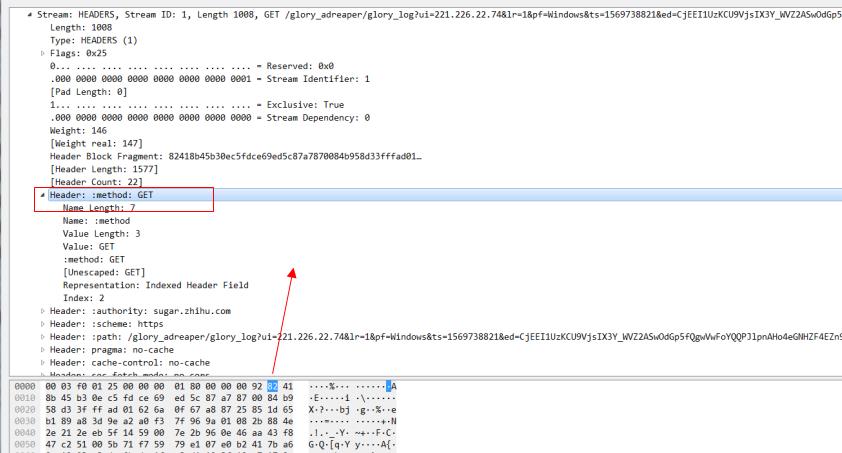
例如这个header帧,注意看这个method:get的头部信息。因为method:get 在静态索引表中的索引值为2.对于这种key和value都在索引表中的值,我们用一个字节也就是8个bit来标识,其中第一个bit固定为1,剩下7位就用来表示索引表中的值,这里method:get 索引表的值为2,所以这个值就是1000 0010,换算成16进制就是0x82.

再看一组,key在索引表中,value 不在索引表中的header例子。
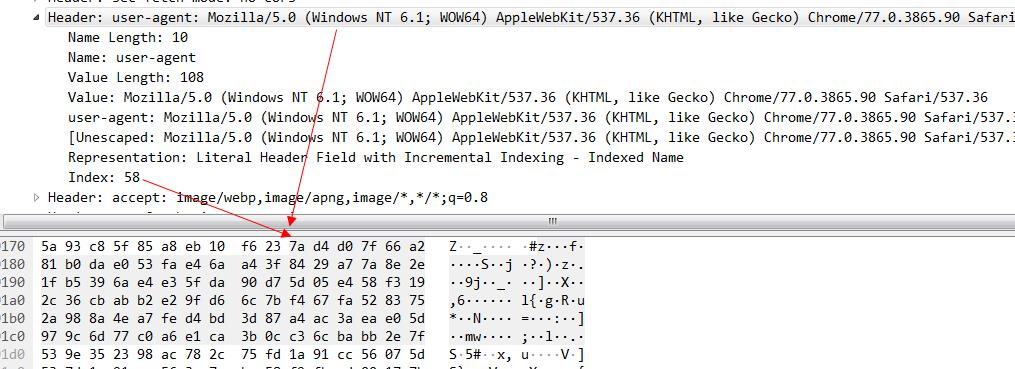
对于key在索引表中,value 不在索引表中的情况,固定是01开头的字节,后面6个bit(111010 换算成十进制就是58)就是静态索引的值, user-agent在索引中index的值是58 再加上01开头的2个bit 换算成二进制就是01111010,16进制就7a了。然后接着看第二个字节,0xd4,0xd4换算成二进制就是 1 101 0100,其中第一个bit 代表后面采用的是哈夫曼编码,后面的7个bit 这个key-value的value 需要几个字节来表示,这里是101 0100 换算成10进制就是84,也就是说这个user-agent后面的value需要84个字节来表示,我们数一下图中的字节数 16*5+第一排d4后面的4个字节,刚好等于84个字节。
最后再看一个key和value 都不在索引表中的例子。
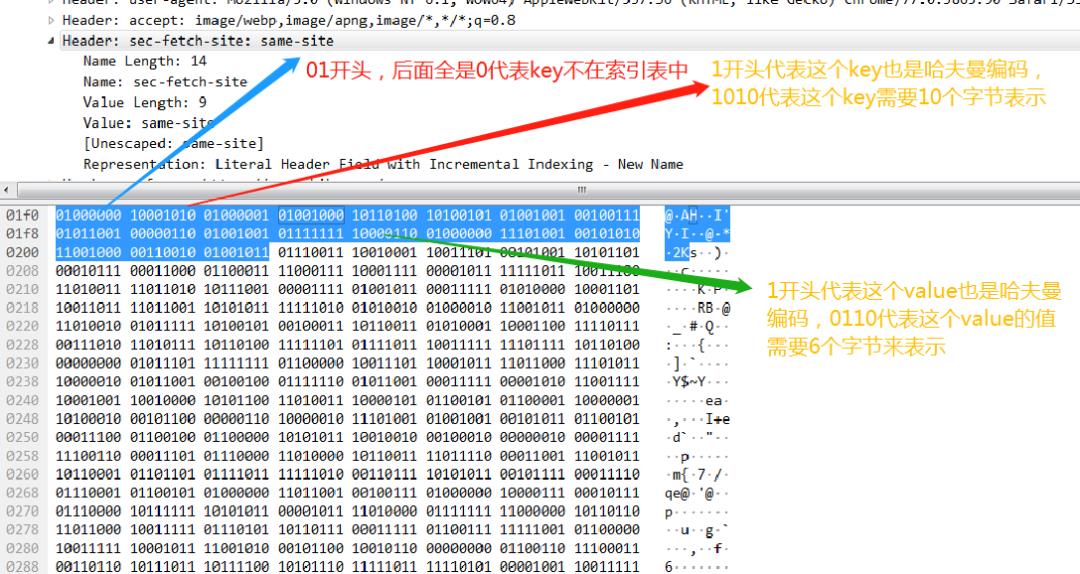
四、http2 协议中 server push 的能力
前文我们提到过,h2相比h1.x协议提升最大的就是h2可以在单条tcp连接的基础上 同时传输n个stream。从而避免h1.x协议中队头拥塞的问题。实际上在大部分前端的页面中,我们还可以使用h2协议的server push能力 进一步提高页面的加载速度。例如通常我们用浏览器访问一个html页面时,只有当html页面返回到浏览器,浏览器内核解析到这个html页面中有CSS或者JS之类的资源时,浏览器才会发送对应的CSS或者JS请求,当CSS和JS回来以后 浏览器才会进一步渲染,这样的流程通常会导致浏览器处于一段时间内的白屏从而降低用户体验。有了h2协议以后,当浏览器访问一个html页面到服务器时,服务器就可以主动推送相应的CSS和JS的内容到浏览器,这样就可以省略浏览器之后重新发送CSS和JS请求的步骤。
有些人对Server Push存在一定程度上的误解,认为这种技术能够让服务器向浏览器发送“通知”,甚至将其与WebSocket进行比较。事实并非如此,Server Push只是省去了浏览器发送请求的过程。只有当“如果不推送这个资源,浏览器就会请求这个资源”的时候,浏览器才会使用推送过来的内容。否则如果浏览器本身就不会请求某个资源,那么推送这个资源只会白白消耗带宽。当然如果与服务器通信的是客户端而不是浏览器,那么http2协议自然就可以完成 push推送的功能了。所以都使用http2协议的情况下,与服务器通信的是客户端还是浏览器 在功能上还是有一定区别的。
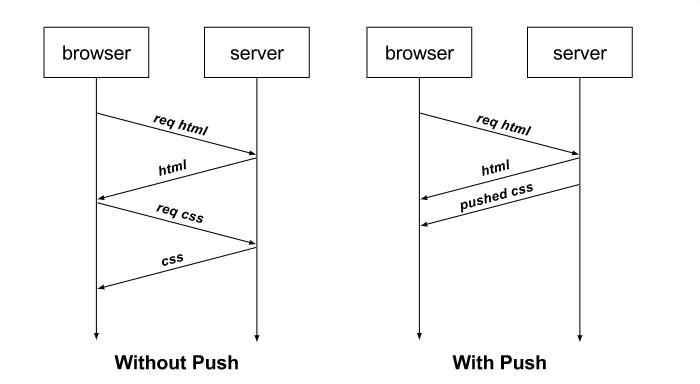
下面为了演示这个过程,我们写一段代码。考虑到浏览器访问http2站点必须要建立在tls连接之上,我们首先要生成对应的证书和秘钥。

然后开启http2,在接收到html请求的时候主动push html中引用的CSS文件。
package mainimport ("fmt""net/http""github.com/labstack/echo")func main() {e := echo.New()e.Static("/", "html")//主要用来验证是否成功开启http2环境e.GET("/request", func(c echo.Context) error {req := c.Request()format := `<code>Protocol: %s<br>Host: %s<br>Remote Address: %s<br>Method: %s<br>Path: %s<br></code>`return c.HTML(http.StatusOK, fmt.Sprintf(format, req.Proto, req.Host, req.RemoteAddr, req.Method, req.URL.Path))})//在收到html请求的时候 同时主动push html中引用的css文件,不需要等待浏览器发起请求e.GET("/h2.html", func(c echo.Context) (err error) {pusher, ok := c.Response().Writer.(http.Pusher)if ok {if err = pusher.Push("/app.css", nil); err != nil {println("error push")return}}return c.File("html/h2.html")})//e.StartTLS(":1323", "cert.pem", "key.pem")}
然后Chrome访问这个网页的时候,看下network面板:

可以看出来这个CSS文件 就是我们主动push过来的。再看下Wireshark。

可以看出来 stream id为13的 是客户端发起的请求,因为id是单数的,在这个stream中,还存在着push_promise帧,这个帧就是由服务器发送给浏览器的,看一下他的具体内容。
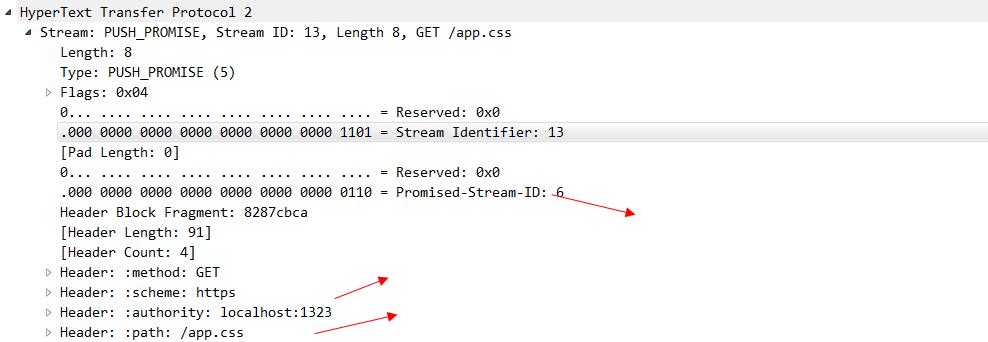
可以看出来这个帧就是用来告诉浏览器,我主动push给你的是哪个资源,这个资源的stream-id 是6.图中我们也看到了有一个stream-id 为6的 data在传输了,这个就是服务器主动push出来的CSS文件。到这里,一次完整的server push就交互完毕了。
但在实际线上应用server push的时候 挑战远远比我们这个demo中来的复杂。首先就是大部分cdn供应商(除非自建cdn)对server push的支持比较有限。我们不可能让每一次资源的请求都直接打到我们的源服务器上,大部分静态资源都是前置在cdn中。其次,对于静态资源来说,我们还要考虑缓存的影响,如果是浏览器自己发出去的静态资源请求,浏览器是可以根据缓存状态来决定这个资源我是否真的需要去请求,而server push 是服务器主动发起的,服务器多数情况下是不知道这个资源的缓存是否过期的。当然可以在浏览器接收到push promise帧以后,查询自身的缓存状态然后发起RST_STREAM帧,告知服务器这个资源我有缓存,不需要继续发送了,但是你没办法保证这个RST_STREAM在到达服务器的时候,服务器主动push出去的data帧还没发出去。所以还是会存在一定的带宽浪费的现象。总体来说,server push 还是一个提高前端用户体验相当有效的手段,使用了server push以后 浏览器的性能指标 idle指标 一般可以提高3-5倍(毕竟浏览器不用等待解析html以后再去请求CSS和JS了)。
五、http2 为什么要实现流量控制?
很多人不理解,为什么tcp传输层已经实现了流量控制,我们的应用层http2还要实现流量控制。下面我们看一张图。
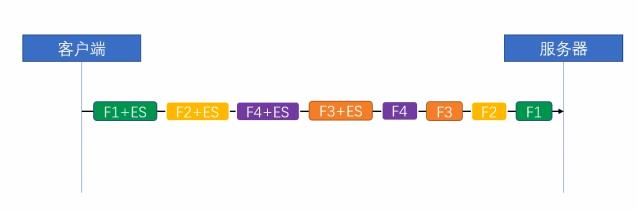
在http2协议中,因为我们支持多路复用,也就是说我们可以同时发送多个stream 在同一条tcp连接中,上图中,每一种颜色就代表一个stream,可以看到 我们总共有4种stream,每一个stream又有n个frame,这个就很危险了,假设在应用层中我们使用了多路复用,就会出现n个frame同时不停的发送到目标服务器中,此时流量达到顶峰就会触发tcp的拥塞控制,从而将后续的frame全部阻塞住,造成服务器响应过慢了。http1.x 中因为不支持多路复用自然就不存在这个问题。且我们之前多次提到过,一个请求从客户端到达服务器端要经过很多的代理服务器,这些代理服务器内存大小以及网络情况都可能不一样,所以在应用层上做一次流量控制尽量避开触发tcp的流控是十分有必要的。在http2协议中的流量控制策略,遵循以下几个原则:
客户端和服务端都有流量控制能力。
发送端和接收端可以独立设置流控能力。
只有data帧才需要流控,其他header帧或者push promise帧等都不需要。
流控能力只针对tcp连接的两端,中间即使有代理服务器,也不会透传到源服务器上。
访问知乎的站点看一下抓包。
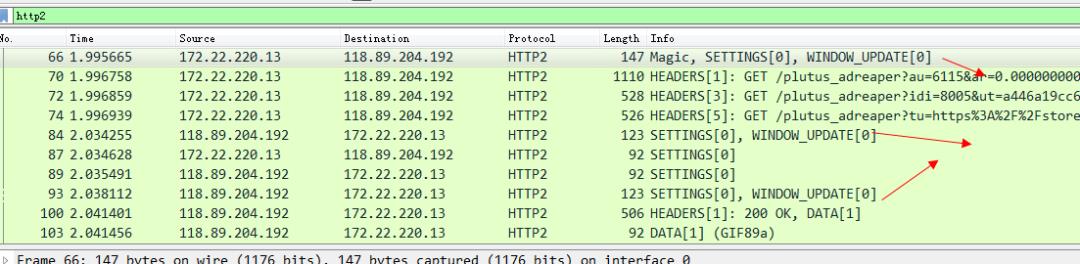
这些标识window_update帧的 就是所谓的流控帧了。我们随意点开一个看一下,就可以看到这个流量控制帧告诉我们的帧大小。
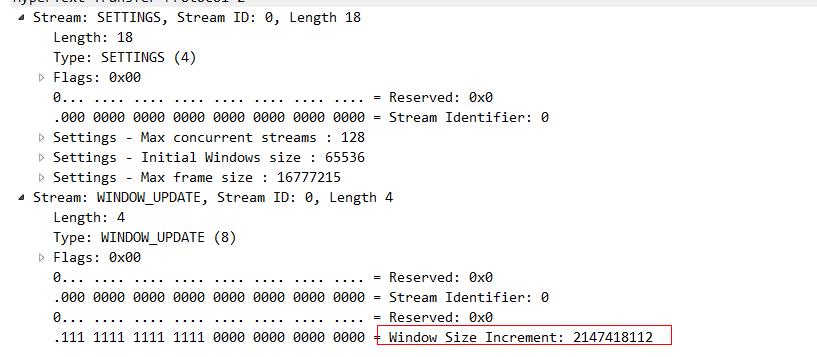
聪明如你一定能想到,既然http2都能做到流控了,那一定也可以来做优先级。比方说在http1.x协议中,我们访问一个html页面,里面会有JS和CSS还有图片等资源,我们同时发送这些请求,但是这些请求并没有优先级的概念,谁先出去谁先回来都是未知的(因为你也不知道这些CSS和JS请求是不是在同一条tcp连接上,既然是分散在不同的tcp中,那么哪个快哪个慢是不确定的),但是从用户体验的角度来说,肯定CSS的优先级最高,然后是JS,最后才是图片,这样就可以大大缩小浏览器白屏的时间。在http2中 实现了这样的能力。比如我们访问sina的站点,然后抓包就可以看到:
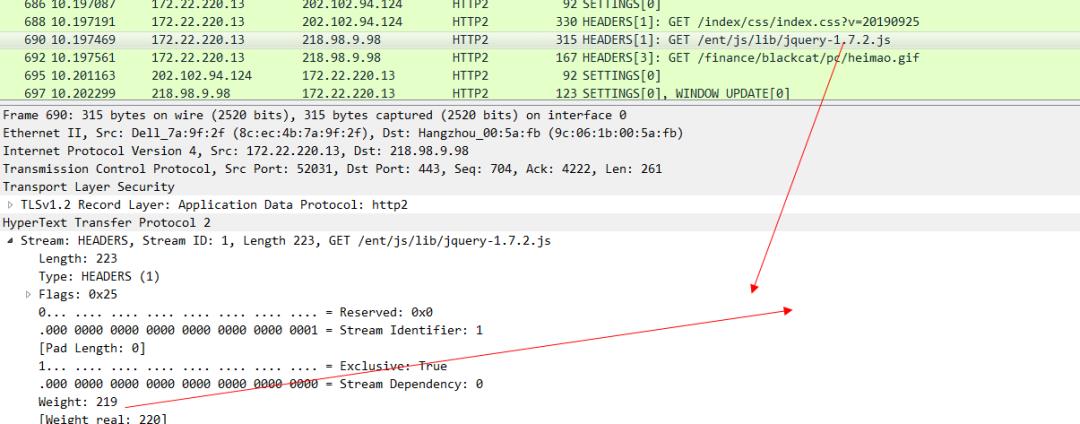
可以看下这个CSS 帧的的优先级:

JS的优先级
最后是gif图片的优先级 ,可以看出来这个优先级是最低的。
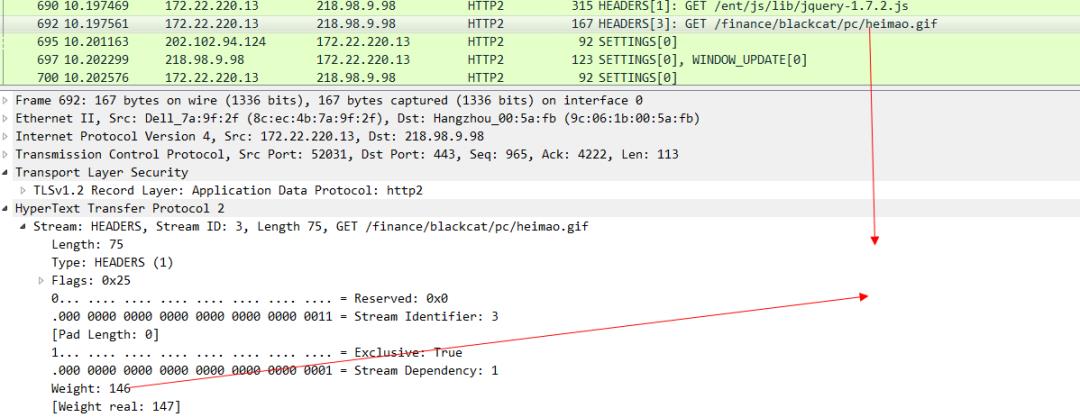
有了weight这个关键字来标识优先级,服务器就知道哪些请求需要优先被响应优先被发送response,哪些请求可以后一点被发送。这样浏览器在整体上提供给用户的体验就会变的更好。
六、http2 协议遇到的问题
基于tcp或者tcp+tls的 http2协议 还是遇到了很多问题,比如:握手时间过长问题,如果是基于tcp的http2协议,那么至少要三次握手,如果是tcp+tls的 http2协议,除了tcp的握手还要经历tls的多次握手(tls1.3已经可以做到只有1次握手)。每一次握手都需要发送一个报文然后接收到这个报文的ack才可以进行下一次握手,在弱网环境下可以想象的到这个连接建立的效率是极低的。此外,tcp协议天生的队头拥塞 问题也一直在困扰着http1.x协议和http2协议。我们看一下谷歌spdy的宣传图,可以更加精准的理解这个拥塞的本质:

图一很好理解,我们多路复用支持下同时发了3个stream,然后经过tcp/ip协议 发送到服务器端,然后tcp协议把这些数据包再传给我们的应用层,注意这里有个条件是,发送包的顺序要和接收包的顺序一致。上图中可以看到那些方块的图的顺序是一致的,但是如果碰到下图中的情况,比如说这些数据包恰好第一个红色的数据包传丢了,那么后续的数据包即使已经到了服务器的机器里,也无法立刻将数据传递给我们的应用层协议,因为tcp协议规定好了接收的顺序要和发送的顺序保持一致,既然红色的数据包丢失了,那么后续的数据包就只能阻塞在服务器里,一直等到红色的数据包经过重新发送以后成功到达服务器了,再将这些数据包传递给应用层协议。
tcp协议除了有上述的一些缺陷以外,还有一个问题就是tcp协议的实现者是在操作系统层面,我们任何语言,包括java,c,c++,go等等 对外暴露的所谓socket编程接口 最终实现者其实都是操作系统自己。要让操作系统自己升级tcp协议的实现是非常非常困难的,况且整个互联网中那么多设备想要整体实现tcp协议的升级是一件不现实的事情(ipv6协议升级的过慢也有这方面的原因)。基于上述问题,谷歌就基于udp协议封装了一层quic协议(其实很多基于udp协议的应用层协议,都是在应用层上部分实现了tcp协议的若干功能),来替代http1.x-http2中的tcp协议。
我们打开chrome中的quic协议开关:

然后访问一下youtube(国内的b站其实也支持)。
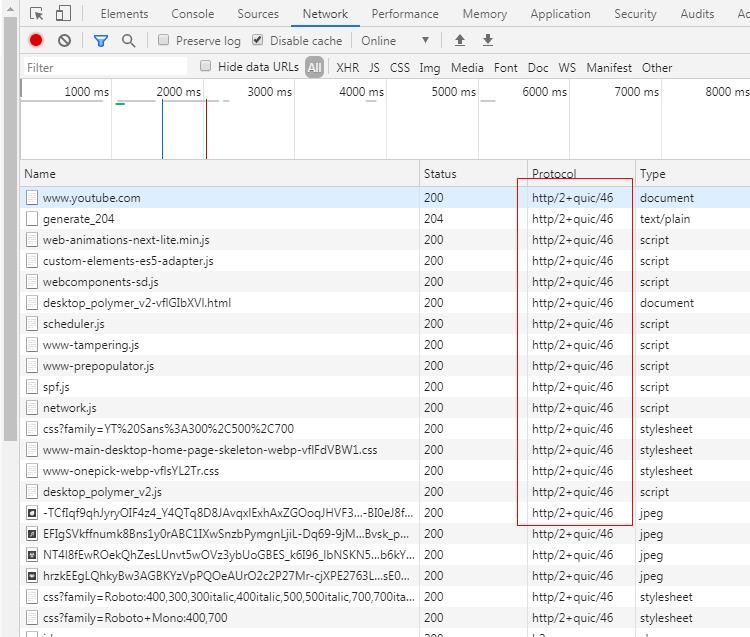
可以看出来已经支持quic协议了。为什么这个选项在chrome浏览器中默认是关闭的,其实也很好理解,这个quic协议实际上是谷歌自己搞出来的,还没有被正式纳入到http3协议中,一切都还在草案中。所以这个选项默认是关闭的。看下quic协议相比于原来的tcp协议主要做了哪些改进?其实就是将原来队列传输报文改成了无需队列传输,那自然也就不存在队头拥塞的问题了。
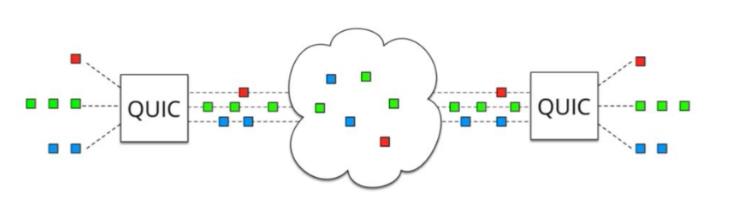
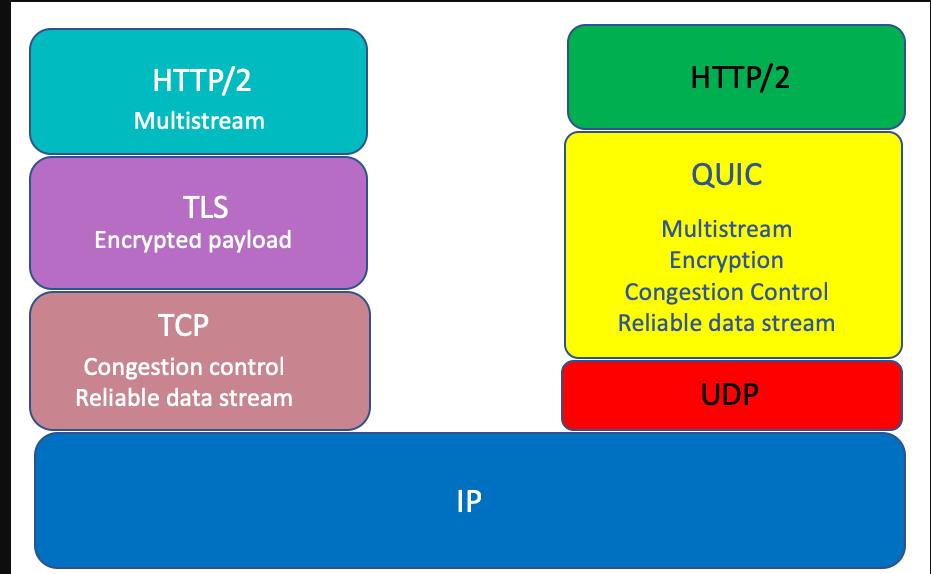
最后要提一下,在极端弱网环境中,http2的表现有可能不如http1.x,因为http2下面只有一条tcp连接,弱网下,如果丢包率极高,那么会不断的触发tcp层面的超时重传,造成tcp报文的积压,迟迟无法将报文传递给上面的应用层,但是http1.x中,因为可以使用多条tcp连接,所以在一定程度上,报文积压的情况不会像http2那么严重,这也是我认为的http2协议唯一不如http1.x的地方,当然这个锅是tcp的,并不是http2本身的。
- END -
点赞 + 在看 + 分享,一键三连,幸福满满!
以上是关于深入TLS/SSL协议的主要内容,如果未能解决你的问题,请参考以下文章
如何使用 TLS/SSL 确保 WebSocket 连接的安全