Mysql索引
Posted 兰昌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql索引相关的知识,希望对你有一定的参考价值。
注:建立索引是为了避免全表扫描,从而提高 sql 语句执行效率。
聚集索引(clustered index)
innodb引擎,优势:根据主键查询条目比较少时,不用回行。
劣势:如果碰到不规则数据插入时,造成频繁页分裂。
如图:

注意:innodb来说
1、主键索引:既存索引值,又在叶子中存储行的数据。
2、如果没有主键(primary key),则会 Unique key 做主键。
3、如果没有 unique ,则系统生成一个内部的 rowid 做主键。
4、像 innodb 中,主键的索引结构中,既存储了主键值,又存储了行数据,这种结构称为“聚簇索引”。
非聚集索引(non-clustered index)
myisam引擎:主索引和次索引,都指向物理行(磁盘位置)。
explain用法
explain是用来查看mysql是如何计划执行sql语句的。可以帮助选择更适合的索引和更适合的sql语句。
explain结果参数详解:
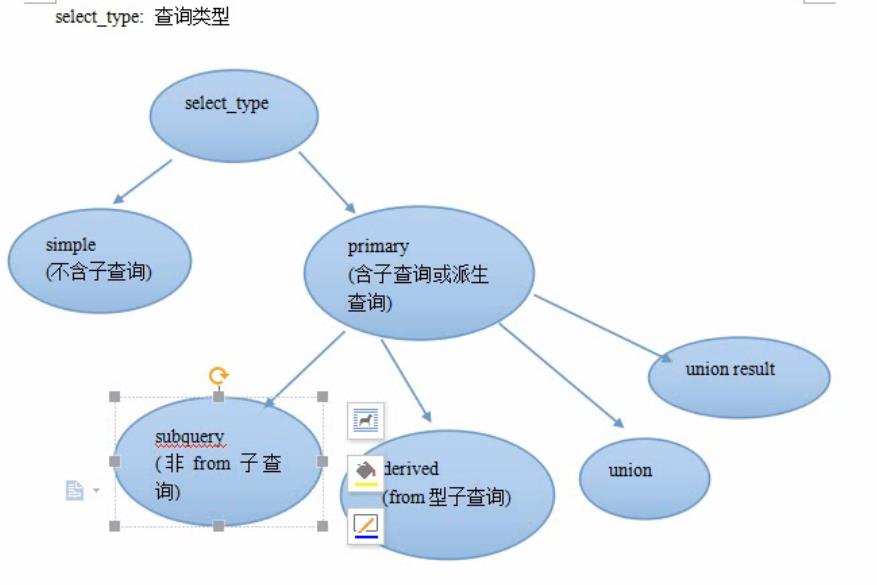
select_type 查询类型
table 查询针对的表
type
possible_keys 可能用到的索引 (分析的是索引用于查找的过程)
key 最终用到的索引(可能是被用于查找、排序或索引覆盖)
key_len 使用索引的最大长度
ref
rows 扫描了多少行数据,找到了需要数据。
extra
optimal 索引
条件因素:
1、查询频繁。
2、区分度高(数据的不相似度,至少为 0.1)。
3、索引的长度(用于区分度的长度):直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(或占用内存多)。
通过计算区分度的值,来获得区分度和长度取衡:
select ((select count(distinct left(字段名,长度))from 表名)/(select count(*) from 表名));
sql语句
分解查询:按逻辑把多表连接查询分成多个简单sql(不允许三表以上的连接查询)。
union
1、union 的子句条件要尽量具体,即--查询更少的行。
2、子句的结果在内存里并成结果集,需要先排序再去重复。如果不需要去重,尽量加 all 之后。
group by
注意:1、分组用于统计,而不用于筛选重复数据。
2、group by 的列要有索引,可以避免临时表及文件排序。
3、order by 的列要和 group by 的一致,否则也会引起临时表。
count()
myisam 的 count() 的“所有行”很快,因为 myisam 对行数进行了储存。一旦有条件的查询,速度就不再快,尤其是 where 条件的列上没有索引。
以上是关于Mysql索引的主要内容,如果未能解决你的问题,请参考以下文章