大数据量样本随机采样-蓄水池算法
Posted 笨兔勿应
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据量样本随机采样-蓄水池算法相关的知识,希望对你有一定的参考价值。
最近在个性化推荐系统的优化过程中遇到一些问题,大致描述如下:目前在我们的推荐系统中,各个推荐策略召回的item相对较为固定,这样就会导致一些问题,用户在多个推荐场景(如果多个推荐场景下使用了相同的召回策略)、多次请求时得到的结果也较为固定,对流量的利用效率会有所降低;尤其对于行为较少的用户,用来作为trigger的行为数据本身就很少,这样就使得召回item同质化较为严重,使得第一个问题更加明显。
目前的解决方法是,在推荐策略的召回阶段加入一定的随机机制,使得用户在多个场景、多次请求时能后给用户展示相似但不完全雷同的结果 。所以问题就转化为在N个召回结果(召回结果需要适当地扩大)中随机抽样出K个结果,两个难点:
1. N的值很大时,直接在N个数中取K个数实际是比较慢的,再加上我们这里还要求是不重复的采样,这就导致每次产生的随机数采样的结果与之前采样的某一个结果一致就需要重新进行采样,这就导致线上计算的性能会受到影响,这个影响随着N的增加会越来越严重。所以我们需要有一种时间复杂度较小的采样算法,如O(N)的时间复杂度。
2. 对于推荐策略召回的结果,其实每个item是具有不同的权重(相似度)的,所以我们也可以利用到这部分信息,即在抽样时并不是等概率采样,而是带权重的概率采样。
对于第一个问题,我们可以使用蓄水池算法来解决。首先先看这个问题的简化版,即从n个数中随机采样出1个数。
解法:我们总是选择第一个对象,以1/2的概率选择第二个,以1/3的概率选择第三个,以此类推,以1/m的概率选择第m个对象。当该过程结束时,每一个对象具有相同的选中概率,即1/n,证明如下。
证明:第m个对象最终被选中的概率P=选择m的概率*其后面所有对象不被选择的概率,即
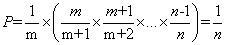
再来看对应的蓄水池抽样问题,即从n个数中随机采样k个数。可以类似的思路解决。先把读到的前k个对象放入“水库”,对于第k+1个对象开始,以k/(k+1)的概率选择该对象,以k/(k+2)的概率选择第k+2个对象,以此类推,以k/m的概率选择第m个对象(m>k)。如果m被选中,则随机替换水库中的一个对象。最终每个对象被选中的概率均为k/n,证明如下。
证明:第m个对象被选中的概率=选择m的概率*(其后元素不被选择的概率+其后元素被选择的概率*不替换第m个对象的概率),即
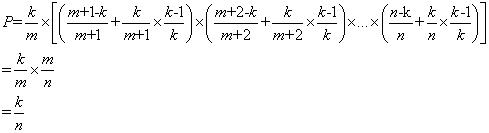
实际代码实现还是比较简单的:
1 List<Map<String, Object>> sampleList = new ArrayList<>(); 2 for (int i=0; i<sampleNum; ++i) { 3 sampleList.add(rawList.get(i)); 4 } 5 for (int i=sampleNum; i<rawListSize; ++i) { 6 int j = r.nextInt(i+1); 7 if (j < sampleNum) { 8 sampleList.remove(j); 9 sampleList.add(rawList.get(i)); 10 } 11 }
再来看看第二个问题,这就涉及到了带权重的概率抽样问题了。那有没有在蓄水池算法基础上的带权重概率的抽样算法呢?当然是有的,想要详细了解的可以直接看paper《Weighted random sampling with a reservoir》。
首先对于每个样本,都具有一个权重Wi,我们可以针对这个权重值做一个变换作为每个样本的得分:sampleScore = random(0, 1)^(1/Wi)。然后采样过程与之前的一致,也是对每个样本进行顺序读取。对前k个样本维护一个最小堆(针对sampleScore排序),然后对于后续的样本,每次来一个样本,都将这个新样本的sampleScore与之前的最小样本的sampleScore进行比较,如果比最小sampleScore要大,则推出这个最小值,压入这个新样本并继续维护这个最小堆,直到所有样本都被遍历过一次。
具体的代码实现如下:
Comparator<Map<String, Object>> cmp = new Comparator<Map<String, Object>>() { public int compare(Map<String, Object> e1, Map<String, Object> e2) { return Double.compare((double)e1.get(sampleScoreField), (double)e2.get(sampleScoreField)); } }; PriorityQueue<Map<String, Object>> pq = new PriorityQueue<>(sampleNum, cmp); for (int i=0; i<sampleNum; ++i) { Map<String, Object> item = rawList.get(i); double sampleScore = Math.pow(r.nextDouble(), 1.0/(0.001+MapUtils.getDoubleValue(item, weightField, 0.0))); item.put(sampleScoreField, sampleScore); pq.add(item); } for (int i=sampleNum; i<rawListSize; ++i) { Map<String, Object> item = rawList.get(i); double sampleScore = Math.pow(r.nextDouble(), 1.0/(0.001+MapUtils.getDoubleValue(item, weightField, 0.0))); item.put(sampleScoreField, sampleScore); Map<String, Object> minItem = pq.peek(); if (sampleScore > (double)minItem.get(sampleScoreField)) { pq.remove(); pq.add(item); } }
以上。
版权声明:
本文由笨兔勿应所有,发布于http://www.cnblogs.com/bentuwuying。如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。
以上是关于大数据量样本随机采样-蓄水池算法的主要内容,如果未能解决你的问题,请参考以下文章