Sql Server优化---统计信息维护策略
Posted Avatarx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sql Server优化---统计信息维护策略相关的知识,希望对你有一定的参考价值。
首先解释一个概念,统计信息是什么:
简单说就是对某些字段数据分布的一种描述,让SQL Server大概知道预期的数据大小,从而指导生成合理执行计划的一种数据库对象
默认情况下统计信息的更新策略:
1,表数据从0行变为1行
2,少于500行的表增加500行或者更多
3,当表中行多于500行时,数据的变化量大于500+20%*表中数据行数
非默认情况下,促使已有统计信息更新的因素(包括但不限于下面三种,别的我也没想起来):
1,rebulid\\Reorg index
2,主动update statistics
3,数据库级别的sp_updatestats
开始问题:
对于大表的更新策略是:数据的变化量大于500+20%*表中数据行数
比如对于1000W数据量的表,数据变化要超过500+1000W*20%=2,000,500之后才能触发统计信息的更新,
这一点大多数情况下是无法接受的,为什么?因为该规则下触发统计信息更新的阈值太大,会导致某些统计信息长期无法更新,
由于统计信息导致的执行计划不合理的情况已经在实际业务中屡见不鲜,对于统计信息的更新已经显得非常必要
同时,仅仅靠sqlserver自己更新统计信息,也不一定可靠,因为统计信息中还要一个取样行数的问题,这个也非常重要
因为SQL Server默认的取样行数是有上限的(默认取样,未指定取样百分比或者SQL Server自动更新统计信息时候的取样百分比),
这个上限值在100W行左右(当然也不肯定,只是观察),对于超过千万行的表,这个取样比例还是非常低的
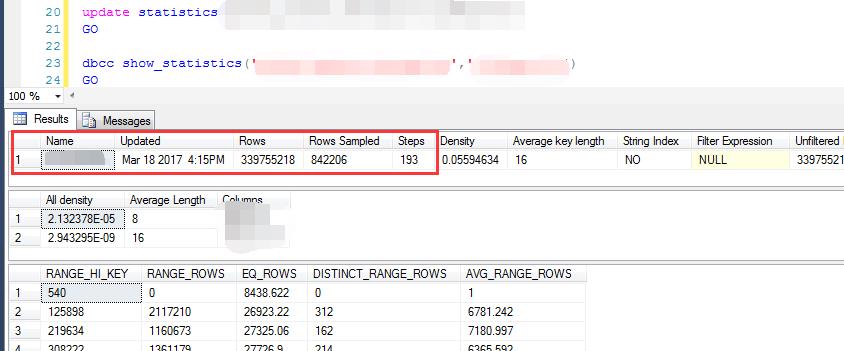
比如下图超过3亿行的表,更新统计信息时候未指定取样百分比,默认取样才去了84万行)
据楼主的观察看,对于小表,不超过500W行的表,默认的取样比例是没有问题的,对于较大的表,比如超过500W行的表(当然这个500W行也是一个参考值,不是绝对值)
因此说默认取样比例是根本无法准确描述数据分布的。
由此看来,人工介入统计信息的更新是非常有必要的。那么如何更新索引的统计信息,有没有一种固定的方式?答案是否定的。
首先来看能够触发统计信息更新的方式
1,Rebulid\\Reorg index
当然Rebulid\\Reorg索引只是附带更新了索引的统计信息,主要是为了整理了索引碎片,
对于大表,代价相当大,数据库的维护策略,没有一概而论的方法,
对于较小的数据库或者是较小的表,比如几十万几百万的表,每天一个rebuild index都可以,
但是这种经验移植到大一点的数据库上恐怕就不好使了(正如名人的成功经验不可复印一样,每个人生活的环境不一样,不能一概而论)。
这种Rebulid\\Reorg index对资源的消耗以及时间代价上都会相当大,甚至有些情况下是不会给你机会这么做的。
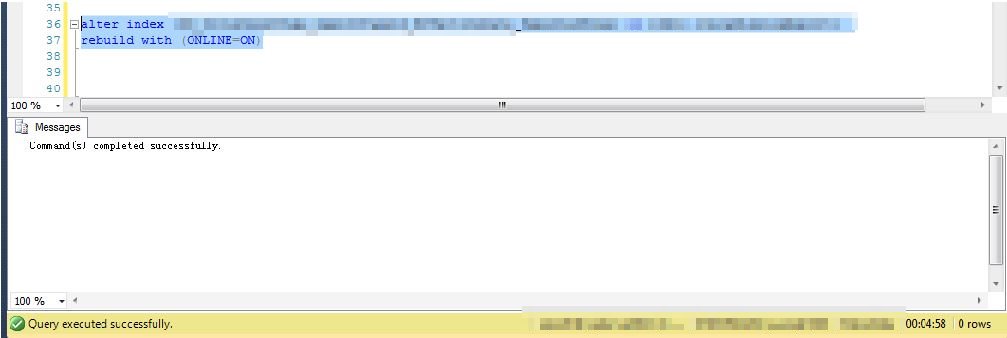
比如下面rebuild一个复合索引的耗时情况,仅仅是一个表上的一个索引,就花费了5分钟的时间
一个业务复杂的表上有类似这么三五个索引也是正常的,
照这么算下去,如果全库或者是整个实例下的十几个库,每个库数百张表全部这么做,要多长时间,代价可想而知
说不定整都没整完,维护窗口期的时间就到了,除非数据库不大(究竟大小的临界值为多少?个人觉得可以粗略地认为100GB吧),否则是不可以这么做的。
因此可以认为:通过重建或者重组索引来更新索引统计信息,代价太大了,基本上是不现实的。
2,update statistics
正是我想重点说的,因为我这里不具体说语法了,具体语法就不做详细说明了,
简单来说,大概有如下几种选择:
一种默认方式,另外还可以是全表扫描的方式更新,还有就是是指定一个取样百分比,如下:
--默认方式更新表上的所有统计信息 update statistics TableName --对指定的统计信息,采用全表扫描的方式取样 update statistics TableName(index_or_statistics__name) with FullScan --对指定的统计信息,采用指定取样百分比的方式取样 update statistics TableName(index_or_statistics__name1,index_or_statistics__name2) with sample 70 percent
相对于重建或者重组索引,update statistics 也是通过扫描数据页(索引页)的方式来获取数据分布,但是不会移动数据(索引)页,
这是Update Statistics代价相对于Rebuild索引小的地方(即便是Update Statistics的时候100%取样)
关键在于第三种方式:人为指定取样百分比,如果取样百分比为100,那跟FullScan一样
如果不用100,比如80,60,50,30,又如何选择?取样百分比越高,得到的统计信息越准确,但是代价越大,取样越小效率越高,但是误差的可能性会变大,怎么办,这就需要找一个平衡点。
那么究竟要取样多少,既能在更新统计信息的效率上可以接受,又能够使得统计信息达到相对准确地描述数据分布的目的,
这是还是一个需要慎重选择的问题,为什么?参考:http://www.cnblogs.com/wy123/p/5875237.html
如果统计信息取样百分比过低,会影响到统计信息的准确性,
如果过于暴力,比如fullscan的方式扫描,
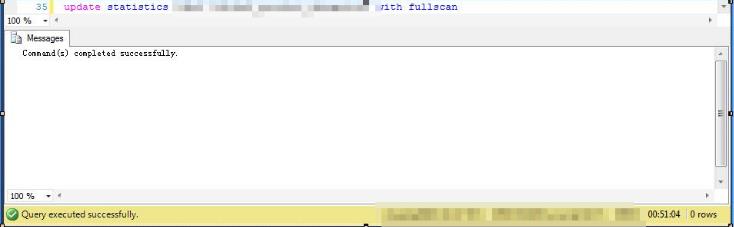
参考下图,一个表就Update了50分钟(当然这是一个大表,上面有多个索引统计信息以及非索引统计信息)。如果有数十张类似的表,效率可想而知
总之就是,没有一个固定的方式,数据库不大,怎么做问题都不大,数据库一大,加上维护的窗口期时间有限,要在统计信息的质量和维护效率上综合考虑
3,数据库级别的sp_updatestats
用法:
exec sp_updatestats
或者
exec sp_updatestats @resample = \'resample\'
指定 sp_updatestats 使用 UPDATE STATISTICS 语句的 RESAMPLE 选项。
对于基于默认抽样的查询计划并非最佳的特殊情况,SAMPLE 非常有用。
在大多数情况下,不必指定 SAMPLE,
这是因为在默认情况下,查询优化器根据需要采用抽样,并以统计方式确定大量样本的大小,以便创建高质量的查询计划。
如果未指定 \'resample\',则 sp_updatestats 将使用默认的抽样来更新统计信息。
默认值为 NO。
直接执行exec sp_updatestats更新统计信息,取样密度是默认的,
究竟这默认值是多少,MSDN上说默认情况下是“查询优化器根据需要采用抽样”,我想着采样算法应该没那么简单粗暴
目前也不知道具体是怎么一个算法或者采样方式,如果有知道园友的话请不惜赐教,谢谢
4,TraceFlag 2371
开启TraceFlag 2371之后,统计信息的变化是根据表做动态变化的,
打破了触发大表统计信息更新的当表中行多于500行时,数据的变化量大于500+20%*表中数据行数 阈值
参考:https://blogs.msdn.microsoft.com/saponsqlserver/2011/09/07/changes-to-automatic-update-statistics-in-sql-server-traceflag-2371/
在下图中,你可以看到新公式的工作方式,对于小表,阈值仍旧是在20%左右,
只有超过25000行之后,此动态规则才会被触发生效
随着表中数据行数的增加,(触发统计信息变更)的百分比会变的越来越低,
比如,对于100,00行的表,触发统计信息更新的阈值已经降低为10%,
对于1,000,000行的表,触发统计信息更新的阈值已经降低为3.2%。
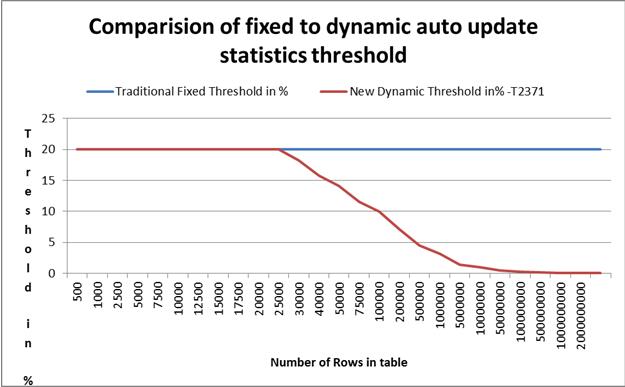
对于10,000,000或者是50,000,000行的表,触发统计信息更新的阈值为少于1%或者0.5%,
而对于他100,000,000行的表,仅仅要求变化在0.31%左右,就可以出发统计信息的更新。
但是个人认为,这种方式也不一定靠谱,虽然开启TraceFlag 2371之后触发更新索引统计信息的阈值降低了,但是取样百分比还是一个问题,
之前我自己就有一个误区,看统计信息的时候只关注统计信息的更新时间(跟自己之前遇到的数据库或者表太小有关)
对于统计信息,及时更新了(更新时间比较新)不等于这个统计信息是准确的,一定要看取样的行数所占总行数的百分比
如何有效维护索引统计信息?
上面说了,要使获取相对准确的统计信息,就要在更新统计信息时候的取样百分比,
对于小表,即便按照其默认的变化阈值触发统计信息更新,或者是按照100%取样更新统计信息,都是没有问题,
对于大表,一定要考虑在其达到默认触发统计信息更新的阈值之前人为更新这个统计信息,但是大表的100%取样统计是不太现实的(性能考虑)
取样百分比越高,得到的统计信息越准确,但是代价越大,这就需要找一个平衡点,那么如果更新大表上的统计信息呢?
如果是认为干预统计信息的生成,就要考虑两个因素:一是数据变化了多少之后更新?二是更新的时候,以什么样的取样来更新?
我们知道,一个表的数据变化信息(增删改)记录在sys.sysindexes这个系统表的rowmodctr字段中,
该表的统计信息更新之后,该字段清零,然后再次累积记录表上的数据变化。
这个信息非常好使,为人工更新统计信息提供了重要的依据,
比如,对于1000W行的表,可以指定变化超过20W行(根据业务情况自定义)之后,手动更新统计信息,
对于5000W行的表,可以指定变化超过60W行(根据业务情况自定义)之后,手动更新统计信息,
同时根据不同的表,在相对较小的表上,指定相对较高的取样百分比,在相对较大的表上,指定相对较低的取样百分比
比如对于1000W行的表,更新统计信息的时候取样百分比定位60%,对于5000W行的表,更新统计信息的时候取样百分比定位30%
这样,可以自行决定数据变化了多少之后更新统计信息,以及动态地决定不同表的不同取样百分比,达到一个合理的目的。
当然,最后强调一下,我说的每一个数据都是相对的,而不是绝对的,都是仅做参考,
具体还要你自己结合自己的服务器软硬件以环境及维护窗口时间去尝试,一切没有死的标准。
总结:统计信息的准确性对执行计划的生成有着至关重要的影响,本文粗略分析了统计信息的跟新规律以及要更新统计信息时候要注意的问题,
在人为干预统计信息更新的时候,需要根据具体的情况(表数据流量,服务器软硬件环境,维护窗口期等)在效率与准确性之间作出合理的选择。
以上是关于Sql Server优化---统计信息维护策略的主要内容,如果未能解决你的问题,请参考以下文章