上一篇说完了如何爬取一个网页,以及爬取中可能遇到的几个问题。那么接下来我们就需要对已经爬取下来的网页进行解析,从中提取出我们想要的数据。
根据爬取下来的数据,我们需要写不同的解析方式,最常见的一般都是HTML数据,也就是网页的源码,还有一些可能是Json数据,Json数据是一种轻量级的数据交换格式,相对来说容易解析,它的格式如下。
{
"name": "中国",
"province": [{
"name": "黑龙江",
"cities": {
"city": ["哈尔滨", "大庆"]
}
}, {
"name": "广东",
"cities": {
"city": ["广州", "深圳", "珠海"]
}
}, {
"name": "台湾",
"cities": {
"city": ["台北", "高雄"]
}
}, {
"name": "新疆",
"cities": {
"city": ["乌鲁木齐"]
}
}]
}
上一篇说到的爬取携程加载不出来的那部分数据就是异步请求Json返回给我们的,对于这类数据,Python有着十分便捷的解析库,所以我们相对不用写多少代码。
但是对于爬取下来是一个HTML数据,其中标签结构可能十分复杂,而且不同HTML的结构可能存在差异,所以解析方式也需要看情况而定。
相对方便的解析方式有正则表达式,xPath和BeautifulSoup4库。
三者的运行速度相比当然是正则表达式最快,xPath其次,Bs4最慢了,因为Bs4是经过封装的库,相对于另外两个,无疑是重装坦克一般,但Bs4确实使用最简单的一个,而正则表达式是最麻烦的一个。
正则表达式几乎所有编程语言都支持,每一种语言的正则表达式都存在一点差异但大同小异。如果你是在设计一个复杂系统,就不要考虑正则表达式了,因为这种方法太过于不稳定,你永远不敢保证你写的正则规则是对应当前系统完全不会报错的。
xPath 是一门在XML文档中查找信息的语言。xPath可用来在XML文档中对元素和属性进行遍历。
关于正则表达式和xPath在之后的实战中再做详解,现在主要是掌握Bs4的使用。
我们首先需要下载Bs4的库。
pip install lxml
pip install beautifulsoup4
当我们爬取下来一整个网页的HTML之后,Bs4就可以根据标签的相对定位来找准你要爬取的数据了。
这个相对定位类似于如下:
body > div.banner > div > div.celeInfo-right.clearfix > div.movie-stats-container > div > div > span > span
可以理解把HTML页面当做洋葱一层一层剥开。
这种定位叫做selector,我们可以不用自己编写它,比较HTML结构可能比较复杂,很容易写错。
我们可以打开浏览器的控制台(F12),然后Elements里面找到我们想要爬取之后解析的内容,这时候你鼠标放上去的位置对应页面内容会变成蓝色让你来对比,如下图。
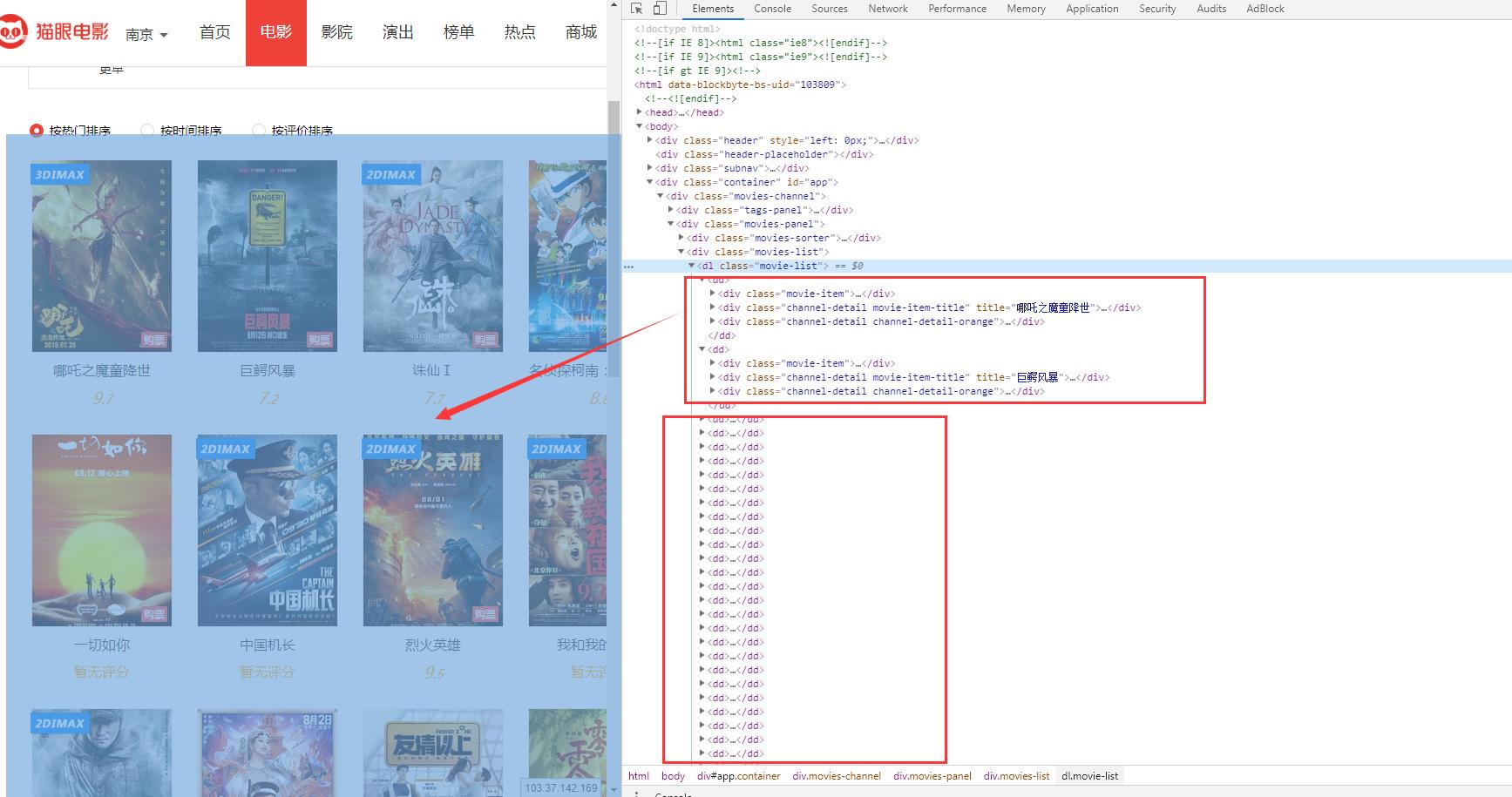
可以发现,这些dd标签里面就是当前页面所有的电影信息了。哪吒之魔童降世你可以理解为dd-1,巨鳄风暴可以当做dd-2,以此类推。
然后你把鼠标放在dd标签上右键,会有一个copy选项,里面有一个selector,就是将它的selector复制下来。
下面分别是哪吒之魔童降世和巨鳄风暴的selector,可以发现,只有最后的dd:nth-child不同。
#app > div > div.movies-panel > div.movies-list > dl > dd:nth-child(1)
#app > div > div.movies-panel > div.movies-list > dl > dd:nth-child(2)
有了这个规律,我们就可以很容易的一次性解析那种列表型网页了。
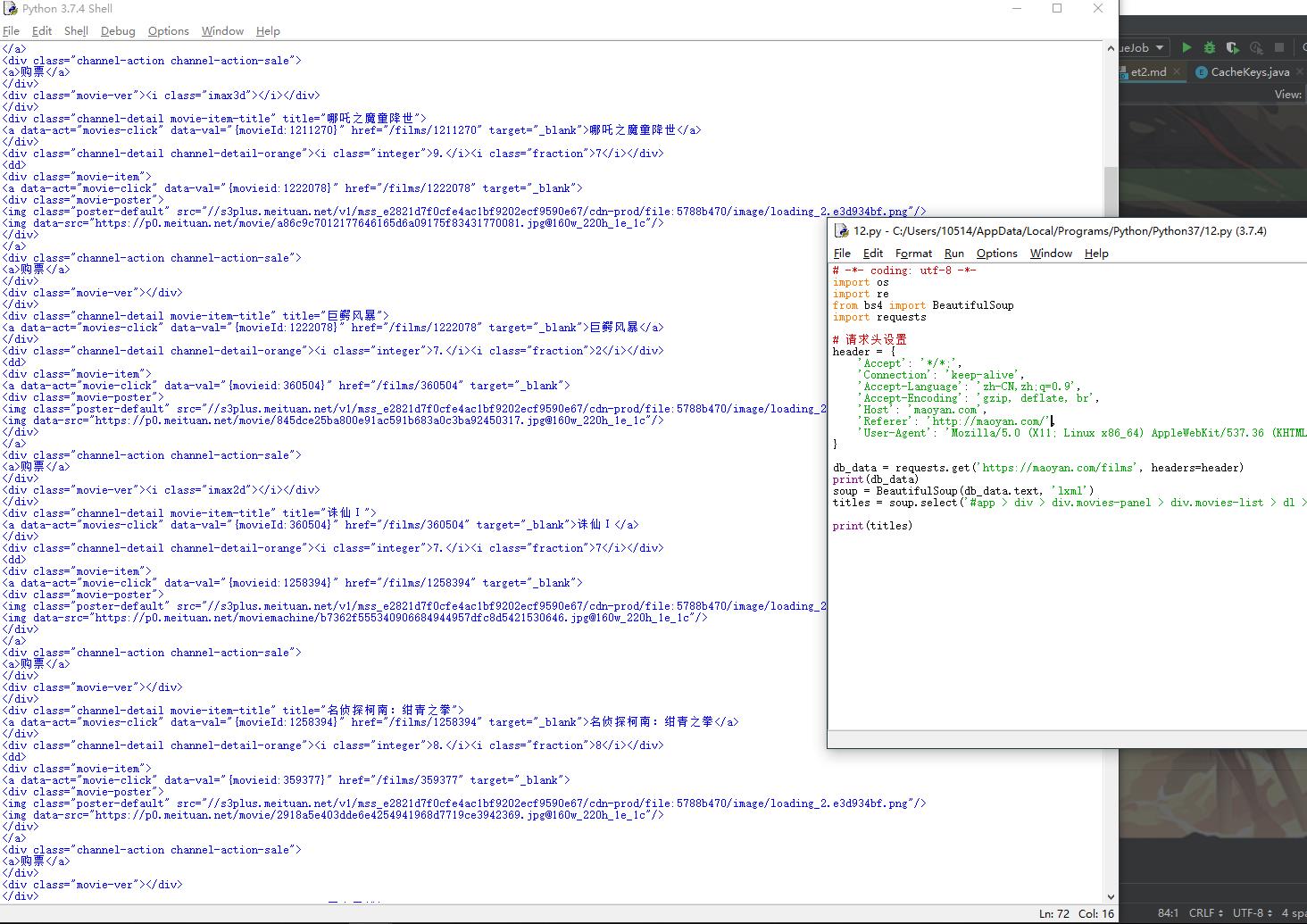
# -*- coding: utf-8 -*-
import os
import re
from bs4 import BeautifulSoup
import requests
# 请求头设置
header = {
\'Accept\': \'*/*;\',
\'Connection\': \'keep-alive\',
\'Accept-Language\': \'zh-CN,zh;q=0.9\',
\'Accept-Encoding\': \'gzip, deflate, br\',
\'Host\': \'maoyan.com\',
\'Referer\': \'http://maoyan.com/\',
\'User-Agent\': \'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36\'
}
data = requests.get(\'https://maoyan.com/films\', headers=header)
soup = BeautifulSoup(data.text, \'lxml\')
titles = soup.select(\'#app > div > div.movies-panel > div.movies-list > dl > dd \')
print(titles)
来仔细讲解一下上面这些代码。
request.get(url,headers)是昨天说过的了,headers就是请求头信息,里面包含了我们客户端的信息以及请求方式是Get还是Post等。
返回的data就是响应了,你可以直接print这个数据,但是这个响应体里面不止包含网页的HTML,还有这次请求的相关数据,比如响应码,200说明成功,404说明没有找到资源等。
data.text就是从响应体中拿到网页HTML代码了。
BeautifulSoup就是我们的主要解析对象,lxml是相应的解析方式。
通过调用BeautifulSoup的select选择器方法,来从之前传入的HTML中获取相应的标签。
这么一看其实Bs4还是很简单的,但这只是Bs4的基础应用了,对于我们普通解析一个网页已经足够用了,如果感兴趣可以去深入去了解一下,不过这个这么说也只是工具库,如果你不嫌麻烦可以自己解析。
看完代码,如果现在我要拿到这个页面的电影名称,这时候上面这个selector就不能用了,因为它不够精确,它只到了\'
用这个selector。

#app > div > div.movies-panel > div.movies-list > dl > dd:nth-child(1) > div.channel-detail.movie-item-title > a
其它方式几乎都大同小异了。
以上是HTML的解析,我们爬取的数据有时还会是Json数据,这类数据相对来说十分规则,我倒是很希望目标数据会是Json格式。
比如上篇中的携程。
它的航班信息就是请求Json返回的。
Python中正则表达式的解析十分简单,你把它当做字典数据类型就可以了。
最开始你获得的Json是一串字符串,通过Python的Json.loads(jsonData)之后,返回的其实就是字典数据类型,直接操作就可以了。

import json
jsonData = \'{
"name":"gzj",
"age":"23",
"sex":"man",
"mail":{
"gmail":"antzuhl@gmail.com",
"qmail":"1325200@qq.com"
}
}\'
res = json.loads(jsonData)
print(res[\'mail\'][\'qmail\'])
(最近在想实战部分要不要录视频和文章两部分,欢迎关注公众号来康康!)