FLink的窗口机制与流处理Join的方案
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FLink的窗口机制与流处理Join的方案相关的知识,希望对你有一定的参考价值。
参考技术AFLink底层引擎是一个流式引擎,支持流处理和批处理,而window是streaming到batch的桥梁。因为流处理过程中,数据是源源不断流进来的,需要对数据进行实时处理的话,可以通过来一个消息处理一个的方式,也可以通过把一段时间内的数据聚合之后,再一起处理的形式,此时需要定义一个窗口来收集过去那段时间内的数据再进行处理。
Flink 提出了三种时间的概念,分别是event time(事件时间:事件发生时的时间),ingestion time(摄取时间:事件进入流处理系统的时间),processing time(处理时间:消息被计算处理的时间)。
窗口可以是时间驱动的(Time Window,例如:每30秒钟),也可以是数据驱动的(Count Window,例如:每一百个元素)。一种经典的窗口分类为:
滑动窗口分配器将元素分配给固定长度的窗口。类似于滚动窗口分配器,窗口的大小由窗口大小参数配置。另外一个参数控制滑动窗口的启动频率。因此,如果频率小于窗口尺寸,滑动窗可以重叠。在这种情况下,元素被分配到多个窗口。
例如,使用大小为10分钟的窗口,滑过5分钟。如下图所示。
会话窗口通过活动会话分配组元素。与滚动窗口和滑动窗口相比,会话窗口不重叠,没有固定的开始和结束时间。相反,当会话窗口在一段时间内没有接收到元素时,即当发生不活动的间隙时关闭。会话窗口分配器配置有会话间隙,定义所需的不活动时间长度。当此时间段到期时,当前会话关闭,后续元素被分配到新的会话窗口。
还可以分别结合以时间驱动或者数据驱动,如:sliding time window,tumbling count window。
Window Assigner : 决定某个元素被分配到哪个/哪些窗口中去。
Trigger : 触发器,进行窗口的处理或清除,每个窗口都会拥有一个的Trigger。
Evictor : “驱逐者”,类似filter作用。在Trigger触发之后,window被处理前,EVictor用来处理窗口中无用的元素。
由以上可以得知,若要对两条数据流进行join操作,则一定是基于window形式的,同样的还有和join操作类似的CoGroupedStreams。可以发现,Flink中joinStream会通过调用windowStream来实现。如图。
接下来,对join的一个实现类WindowJoin进行分析。基本思想为在一个时间窗内对两条数据结构为键值对数据流进行inner join操作。
重要参数配置: 根据Flink的时间概念,时间属性时间选为ingestion time,并设置了窗口大小和数据传输速率。
函数调用
join 窗口的双流数据都是被缓存在内存中的,也就是说如果某个key上的窗口数据太多就会导致 JVM OOM。双流join的难点也正是在这里。例如可以借鉴 Flink在批处理join中的优化方案 ,也可以像HDFS对中间结果的操作那样,当数据超过阈值时能spill到硬盘。
1-flink理论-批处理与流处理+简单示例
【README】
1.本文包含了 批处理与流处理的代码示例;
- 批处理:把数据 攒在一起(或攒一段时间或攒一定内存大小),然后再处理,这叫批处理;
- 流处理:数据每来一个就处理一个;
2.特点:
| 数据处理方式 | 特点 |
| 批处理 | 1.高延时; |
| 流处理 | 1.低延时; |
3.引入flink的maven依赖:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.4</version>
</dependency>
</dependencies>【1】flink批处理离线数据(数据有限)
【1.1】代码
1)数据源,我们保存在本地文本文件中,命名为 hello.txt
hello world
hello flink
how are you
thank you
hello zhangsan
hello lisi2)批处理代码:
/**
* @Description 批处理,word count程序(离线数据)
* @author xiao tang
* @version 1.0.0
* @createTime 2022年04月09日
*/
public class WordCount
public static void main(String[] args) throws Exception
// 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 从文件中读取数据
String inputPath = "D:\\\\workbench_idea\\\\diydata\\\\flinkdemo2\\\\src\\\\main\\\\resources\\\\hello.txt";
DataSource<String> dataSource = env.readTextFile(inputPath);
// 对数据集处理,按照空格分词展开,转为 (word,1) 二元组统计
DataSet<Tuple2<String, Integer>> resultSet = dataSource.flatMap(new MyFlatMapper())
.groupBy(0) // 按照第1个位置的word分组
.sum(1); // 将第2个位置上的数据求和
resultSet.print();
public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>>
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception
// 按照空格分词
String[] words = value.split(" ");
// 遍历所有word,包装成word 输出
Arrays.stream(words).forEach(x->
collector.collect(new Tuple2<>(x, 1));
);
批处理打印结果:
(you,2)
(flink,1)
(world,1)
(hello,4)
(lisi,1)
(zhangsan,1)
(are,1)
(thank,1)
(how,1)
批处理的结果是最终结果;
【2】flink流处理离线数据(数据有限)
/**
* @Description 流数据(无限数据)
* @author xiao tang
* @version 1.0.0
* @createTime 2022年04月09日
*/
public class StreamWordCount
public static void main(String[] args) throws Exception
// 流处理执行环境
StreamExecutionEnvironment streamEnv = StreamExecutionEnvironment.getExecutionEnvironment();
streamEnv.setParallelism(2); // 设置并行度
// 从文件中读取数据
String inputPath = "D:\\\\workbench_idea\\\\diydata\\\\flinkdemo2\\\\src\\\\main\\\\resources\\\\hello.txt";
DataStream<String> dataStream = streamEnv.readTextFile(inputPath);
// 定义流操作
DataStream<Tuple2<String, Integer>> resultStream = dataStream.flatMap(new WordCount.MyFlatMapper())
.keyBy(0)
.sum(1);
// 打印结果
resultStream.print();
// 执行任务(流终止操作)
streamEnv.execute();
打印结果:
2> (world,1)
1> (thank,1)
2> (flink,1)
1> (hello,1)
2> (how,1)
2> (you,1)
1> (hello,2)
2> (you,2)
1> (hello,3)
2> (zhangsan,1)
1> (hello,4)
2> (lisi,1)
1> (are,1)
流处理的结果是一个动态变化的有状态的结果;
有状态的意思说白了就是:后面的处理结果依赖前面的处理结果,如对hello计数为3,它是在前面hello计数为2的基础上做的处理;
【3】flink流处理在线数据(数据无限)
我们引入了 netcat(nc),底层使用socket模拟向某端口写入数据;
然后 flink监控该端口的数据,并做处理;
【3.1】 flink处理类
处理类监听了 nc所在机器的的端口,即 192.168.163.201:7777;
/**
* @Description socket文本流词计数
* @author xiao tang
* @version 1.0.0
* @createTime 2022年04月09日
*/
public class SocketTextStreamWordCount
public static void main(String[] args) throws Exception
// 流处理执行环境
StreamExecutionEnvironment streamEnv = StreamExecutionEnvironment.getExecutionEnvironment();
streamEnv.setParallelism(2); // 设置并行度
// 从 flinkjava parametertool 获取参数(或有)
// ParameterTool parameterTool = ParameterTool.fromArgs(args);
// String host = parameterTool.get("host");
// int port = parameterTool.getInt("port");
// 从socket文本流读取数据
DataStream<String> inputDataStream = streamEnv.socketTextStream("192.168.163.201", 7777);
// 定义流操作
DataStream<Tuple2<String, Integer>> resultStream = inputDataStream.flatMap(new WordCount.MyFlatMapper())
.keyBy(0)
.sum(1);
// 打印结果
resultStream.print();
// 执行任务(流终止操作)
streamEnv.execute();
演示效果:
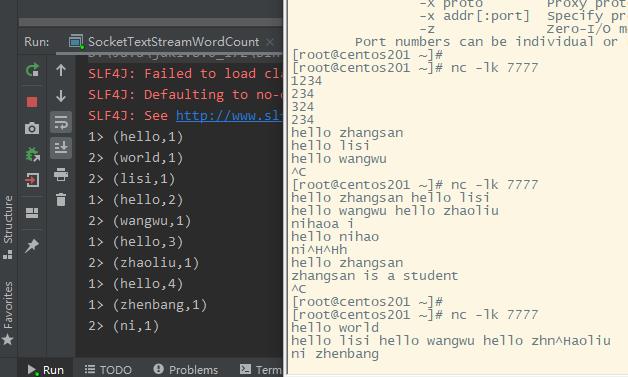
以上是关于FLink的窗口机制与流处理Join的方案的主要内容,如果未能解决你的问题,请参考以下文章