Oracle分析函数-排序排列(rankdense_rankrow_number)
Posted 一枚程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle分析函数-排序排列(rankdense_rankrow_number)相关的知识,希望对你有一定的参考价值。
(1)rank函数返回一个唯一的值,除非遇到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。
(2)dense_rank函数返回一个唯一的值,除非当碰到相同数据时,此时所有相同数据的排名都是一样的。
(3)row_number函数返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
(4)ntile是要把查询得到的结果平均分为几组,如果不平均则分给第一组。
例如:
create table s_score ( s_id number(6) ,score number(4,2) ); insert into s_score values(001,98); insert into s_score values(002,66.5); insert into s_score values(003,99); insert into s_score values(004,98); insert into s_score values(005,98); insert into s_score values(006,80); select s_id ,score ,rank() over(order by score desc) rank --按照成绩排名,纯排名 ,dense_rank() over(order by score desc) dense_rank --按照成绩排名,相同成绩排名一致 ,row_number() over(order by score desc) row_number --按照成绩依次排名 ,ntile(3) over (order by score desc) group_s --按照分数划分成绩梯队 from s_score;
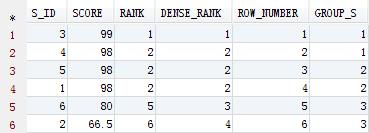
排名/排序的时候,有时候,我们会想到利用伪列row_num,利用row_num确实可以解决某些场景下的问题(但是相对也比较复杂),而且有些场景下的问题却很难解决。
例:取成绩前三名,并且前三名含有并列的情况。通过上面例子,我们可以直观的看到,结果应该有5条记录:
select s_id ,score ,dense_rank from ( select s_id ,score ,rank() over(order by score desc) rank ,dense_rank() over(order by score desc) dense_rank ,row_number() over(order by score desc) row_number from s_score ) t where dense_rank <= 3; S_ID SCORE DENSE_RANK ------- ------ ---------- 3 99.00 1 1 98.00 2 5 98.00 2 4 98.00 2 6 80.00 3
如果只是简单的想到去用rownum <= 3 得到的结果显然不可能是正确的。
组内的排名或者排序是经常遇到的一种场景。
例如,取每个销售部门内,销售业绩最好的前三名。取每个班级内成绩排名信息等等..
取每个班级内每门课成绩排名第一的同学信息:
drop table S_SCORE; create table S_SCORE ( S_ID NUMBER(6), CLASS_ID VARCHAR2(2), COURSE VARCHAR2(20), SCORE NUMBER(5,2) ); INSERT INTO S_SCORE VALUES(1001,\'A\',\'MATH\',\'67\'); INSERT INTO S_SCORE VALUES(1004,\'B\',\'MATH\',\'88\'); INSERT INTO S_SCORE VALUES(1002,\'A\',\'MATH\',\'99\'); INSERT INTO S_SCORE VALUES(1003,\'A\',\'MATH\',\'55\'); INSERT INTO S_SCORE VALUES(1001,\'B\',\'MATH\',\'88\'); INSERT INTO S_SCORE VALUES(1001,\'B\',\'MATH\',\'70\'); INSERT INTO S_SCORE VALUES(1001,\'A\',\'ORACLE\',\'97\'); INSERT INTO S_SCORE VALUES(1004,\'B\',\'ORACLE\',\'48\'); INSERT INTO S_SCORE VALUES(1002,\'A\',\'ORACLE\',\'79\'); INSERT INTO S_SCORE VALUES(1003,\'A\',\'ORACLE\',\'65\'); INSERT INTO S_SCORE VALUES(1001,\'B\',\'ORACLE\',\'82\'); INSERT INTO S_SCORE VALUES(1001,\'B\',\'ORACLE\',\'78\'); select s_id ,class_id ,course ,score ,dense_rank() over (partition by class_id,course order by score desc) drk from S_SCORE; S_ID CLASS_ID COURSE SCORE DRK ------- -------- -------------------- ------- ---------- 1002 A MATH 99.00 1 1001 A MATH 67.00 2 1003 A MATH 55.00 3 1001 A ORACLE 97.00 1 1002 A ORACLE 79.00 2 1003 A ORACLE 65.00 3 1004 B MATH 88.00 1 1001 B MATH 88.00 1 1001 B MATH 70.00 2 1001 B ORACLE 82.00 1 1001 B ORACLE 78.00 2 1004 B ORACLE 48.00 3 select s_id ,class_id ,course ,score from ( select s_id ,class_id ,course ,score ,dense_rank() over (partition by class_id,course order by score desc) drk from S_SCORE ) t where drk = 1; S_ID CLASS_ID COURSE SCORE ------- -------- -------------------- ------- 1002 A MATH 99.00 1001 A ORACLE 97.00 1004 B MATH 88.00 1001 B MATH 88.00 1001 B ORACLE 82.00
rank()和dense_rank()用法相似,这里就不在举例说明了。可以将上面的例子中dense_rank()替换成rank()实现。
接下来,看一个使用row_number()的场景
例:查看每个部门最近一笔销售记录:
select * from criss_sales order by dept_id,sale_date desc; DEPT_ID SALE_DATE GOODS_TYPE SALE_CNT ------- ----------- ---------- ----------- D01 2014/5/4 G02 80 D01 2014/4/30 G03 800 D01 2014/4/8 G01 200 D01 2014/3/4 G00 700 D02 2014/5/2 G03 900 D02 2014/4/27 G01 300 D02 2014/4/8 G02 100 D02 2014/3/6 G00 500
即,我们希望得到这两条记录:
D01 2014/5/4 G02 80 D02 2014/5/2 G03 900
select dept_id ,sale_date ,goods_type ,sale_cnt ,row_number() over (partition by dept_id order by sale_date desc) from criss_sales; DEPT_ID SALE_DATE GOODS_TYPE SALE_CNT ROW_NUMBER()OVER(PARTITIONBYDE ------- ----------- ---------- ----------- ------------------------------ D01 2014/5/4 G02 80 1 D01 2014/4/30 G03 800 2 D01 2014/4/8 G01 200 3 D01 2014/3/4 G00 700 4 D02 2014/5/2 G03 900 1 D02 2014/4/27 G01 300 2 D02 2014/4/8 G02 100 3 D02 2014/3/6 G00 500 4 select dept_id ,sale_date ,goods_type ,sale_cnt from ( select dept_id ,sale_date ,goods_type ,sale_cnt ,row_number() over (partition by dept_id order by sale_date desc) rn from criss_sales ) t where rn = 1; DEPT_ID SALE_DATE GOODS_TYPE SALE_CNT ------- ----------- ---------- ----------- D01 2014/5/4 G02 80 D02 2014/5/2 G03 900
有时会有这样的需求:如果数据排序后分为三部分,业务人员只关心其中的一部分,如何将这中间的三分之一数据拿出来呢?
这时比较好的选择,就是使用ntile函数:
select dept_id ,sale_date ,goods_type ,sale_cnt ,ntile(3) over (order by sale_cnt desc nulls last) all_cmp ,ntile(3) over (partition by dept_id order by sale_cnt desc nulls last) all_dept from criss_sales;
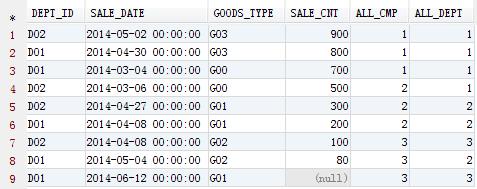
可以看到,Ntile函数为各个记录在记录集中的排名计算比例,返回每条记录所在集合比例位置的值。
例如我们关心全公司前三分之一部分的数据,只需选择 ALL_CMP = 1 的数据就可以了;
如果只是关心全公司中间的三分之一数据,只需选择 ALL_CMP = 2 的数据就可以了。
以上是关于Oracle分析函数-排序排列(rankdense_rankrow_number)的主要内容,如果未能解决你的问题,请参考以下文章
R语言dplyr包排序及序号函数实战(row_numberntilemin_rankdense_rankpercent_rankcume_dist)
MySQL8.0窗口函数之排名函数(rankdense_rank)的使用