Centos 7 安装hadoop
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Centos 7 安装hadoop相关的知识,希望对你有一定的参考价值。
安装centos7
请参考 :centos7 安装
新增hadoop用户
A.添加用户 Hadoop
执行命令:useradd hadoop
B. 设置用户密码
执行命令:passwd Hadoop 设置密码。
C. 给该用户赋予sudo命令权限
执行命令:chmod u+w /etc/sudoers
D. 在sudoers添加用户信息
执行命令:vim /etc/sudoers,并且在如下位置添加 Hadoop ALL =(ALL) ALL。如下图:

注:如果遇到vim不可用,需要安装,输入命令:yum install vim 即可。
E.更改权限:chmod u-w /etc/sudoers
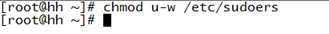
SSH免密码登录
A. 关闭防火墙
配置SSH免密码登录前,需要关闭防火墙。
查看防火墙状态:如果开启状态,需要关闭。
执行命令:firewall-cmd --state
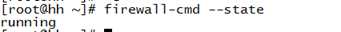
执行命令:service iptables stop
也可以执行命令:chkconfig iptables off 来永久关闭
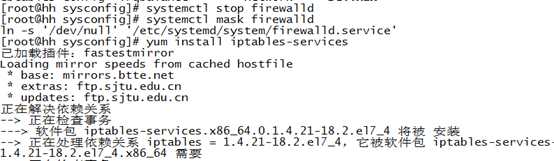
注:如果遇到如下图错误,

可以执行命令:yum install iptables-services 来安装相关组件
如果yum 安装命令不可用,则是因为/etc/sysconfig 不存在iptables,centos7可以这样解决:
A1. 停止并屏蔽firewalld服务
执行命令:systemctl stop firewalld
systemctl mask firewalld
此时使用yum来安装组件包了。
A2. 安装iptables-services软件包
执行命令:yum install iptables-services
A3. 启用iptables服务
执行命令:systemctl start iptables
此时可以再次执行关闭防火墙命令(service iptables stop
),并且进行状态验证,如下图:

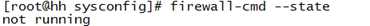
B. 安装SSH(使用Hadoop用户)
首先,检查SSH是否安装
执行命令:rpm -qa | grep openssh,如下图:

安装缺失的软件:
执行命令:sudo yum install openssh*
注册服务,并开启SSH服务
执行命令:sudo systemctl enable sshd
sudo systemctl start sshd 或
service sshd start

生成SSH公钥
执行命令:ssh-keygen -t rsa
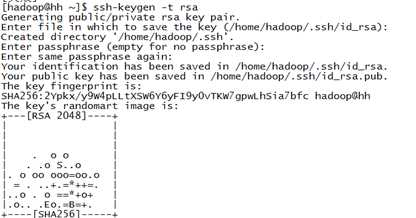
将公钥发至本机的authorized_keys的列表
执行命令:ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]

验证SSH免密码
执行命令:ssh hh,如果不用输入密码,则成功,如下图:
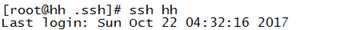
安装jdk
首先用SecureCRT的sftp传输下载好的jdk到centos7的/home/hadoop/softs目录
执行命令:cd /home/hadoop
mkdir softs
创建softs文件夹。
用sftp传输到指定目录,如下图:

将jdk压缩包移到 /usr/local/jdk 目录下
执行命令:mv /home/hadoop/softs/jdk1.7.0_80 /usr/local/jdk
配置环境变量,对/etc/profile 进行文件内容追加
执行命令:vi /etc/profile

之后,执行命令:source /etc/profile 使得配置生效。
检验java安装成功
执行命令:java -version ,如下图,则为成功:

安装hadop
1. 传输hadoop taz包到centos的 /home/hadoop/softs目录,使用sftp的put指令。如图:

2 . 解压hadoop 到/home/hadoop/bigdater 目录下
执行指令:cd /home/hadoop/bigdater
tar -zxvf /home/hadoop/softs/hadoop-2.5.0-cdh5.3.6.tar.gz
3 . 修改配置文件。配置文件主要在 /etc/hadoop 目录下,如图:
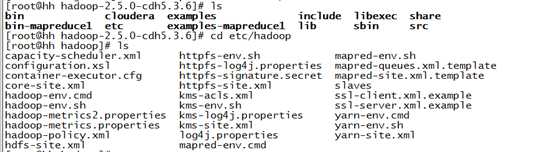
有很多配置文件,目前需要修改的配置文件的介绍在如下列表:
|
文件名称 |
格式 |
描述 |
|
hadoop-env.sh |
Bash脚本 |
记录Hadoop要用的环境变量 |
|
core-site.xml |
Hadoop配置xml |
Hadoop Core的配置项,例如HDFS和MapReduce常用的I/O设置等 |
|
hdfs-site.xml |
Hadoop配置xml |
HDFS守护进程的配置项,包括NameNode、SecondaryNameNode、DataNode等 |
|
yarn-site.xml |
Hadoop配置xml |
YARN守护进程额配置项,包括ResourceManager和NodeManager等 |
|
mapred-site.xml |
Hadoop配置xml |
MapReduce计算框架的配置项 |
|
slaves |
纯文本 |
运行DataNode和NodeManager的机器列表(每行一个) |
|
haoop-metrics.properties |
Properties 文件 |
控制metrics在Hadoop上如何发布的属性 |
|
Log4j.properties |
Properties 文件 |
系统日志文件,NameNode审计日志、DateNode子进程的任务日志的属性 |
首先配置hadoop-env.sh
执行命令:vi /etc/hadoop/hadoop-env.sh,并在底部添加,如下内容。
export JAVA_HOME=/usr/local/jdk/jdk1.7.0_80
export HAODDP_HOME=/home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6/
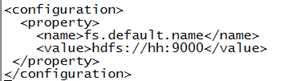
其次配置core-site.xml
执行命令:vi /etc/hadoop/core-site.xml,修改为如下所示:
其次配置hdfs-site.xml ,修改hdfs-site.xml 为:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
</property>
</configuration>
注:dfs.replication 设置hdfs副本为3.
ds.name.dir 设置NameNode的元数据存放路径。
dfs.data.dir 设置DataNode的存储数据路径
其次修改mapred-site.xml
默认情况下,/etc/hadoop/文件夹下有mapred.xml.template文件,我们要复制该文件,并命名为mapred.xml,该文件用于指定MapReduce使用的框架。
执行命令: 复制并重命名
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml,进入编辑,修改为:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
表明MapReduce计算框架基于Yarn工作。
其次修改yarn-site.xml,修改为:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>hh:8080</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hh:8082</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduces.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
最后修改slaves,修改为:hh(当前主机名)
配置hadoop环境变量到/etc/profile ,增加如下内容:
export HADOOP_HOME=/home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6
export PATH=$PATH:$HADOOP_HOME/bin
并且执行命令:source /etc/profile 重新加载配置。
格式化HDFS
执行命令:hadoop namenode -format
启动hadoop
a 赋予可执行权限(用hadoop用户)
执行命令:chmod +x -R /home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6/sbin/
b 启动脚本(hadoop用户,hh主节点都要执行)
执行命令:. /home/hadoop/bigdater/hadoop-2.5.0-cdh5.3.6/sbin/start-all.sh
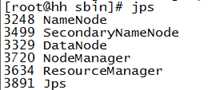
c 验证启动是否成功
执行命令:jps,如果出现如下图所示的信息,则说明hadoop启动成功:
以上是关于Centos 7 安装hadoop的主要内容,如果未能解决你的问题,请参考以下文章