Redis4.0 Cluster — Centos7
Posted 蜗牛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis4.0 Cluster — Centos7相关的知识,希望对你有一定的参考价值。
本文版权归博客园和作者吴双本人共同所有 转载和爬虫请注明原文地址 www.cnblogs.com/tdws
一.基础安装
wget http://download.redis.io/releases/redis-4.0.0.tar.gz tar xzf redis-4.0.0.tar.gz cd redis-4.0.0 cd src make make test //有问题可参考 http://www.cnblogs.com/tdws/p/6360024.html ./redis-server ../redis.conf ps -ef |grep redis 查看redis进程 netstat -lntp | grep 6380 查询指定端口监听 kill -9 进程id 强制杀死redis进程
二. 4.0版本初步了解
Redis4.0中增加了UNLINK 命令(替换del命令),这个命令在删除体积较大的键时,命令在后台线程里面执行,还有异步的flushdb和flushall命令分别是
flushdb async
flushall async
尽可能的避免了服务器阻塞。
增加了交换数据库命令,比如SWAPDB 0 1 ,交换0库和1库
增加了memory命令,可以视察内存使用情况,通过help命令可以看到
127.0.0.1:6379> memory help
1) "MEMORY USAGE <key> [SAMPLES <count>] - Estimate memory usage of key"
2) "MEMORY STATS - Show memory usage details"
3) "MEMORY PURGE - Ask the allocator to release memory"
4) "MEMORY MALLOC-STATS - Show allocator internal stats"
MEMORY USAGE <key> 预估指定key所需内存
MEMORY STATS 视察内存使用详情
MEMORY PURGE 向分配器索要释放更多内存
MEMORY MALLOC-STATS 视察分配器内部状态
另外还有一系列优化比如 LRU和PSYNC,还有模块系统。
三.Cluster
虽然一主一从加哨兵可以解决普通场景下服务可用的问题,但是两个节点分别存储所有的缓存数据,这不仅导致容量受限,更是让我们受限于机器配置最差的那一台,这就是木桶效应。硬件垂直扩容并不能解决日益庞大的缓存数据量和提供能搞得可用性。
在古老的Redis版本中,水平扩容的能力来自于发送命令的客户端,由客户端路由不同的key给到不同的节点,下次读取的时候,也按照相同方式路由key到指定节点拿到数据。如果接下来还希望增加扩容节点的话,就要对历史缓存数据做迁移,迁移过程中为保证数据一致性也要付出一定代价。为了解决节点的不断扩容,设计初期可以预先设置很多节点,以备日后使用,所有设计的节点都参与到分片当中,鉴于初期数据较少,可单台服务器多个节点,在日后数据增多的情况下,只需要迁移节点到新的服务器。而不需要对数据进行重新分配等操作。但是这种做法依然让我们觉得难维护,难迁移,难应对故障,迁移过程中也很难保证数据一致性,比如50个节点,任意一个节点想要停止并迁移服务器,都会引发数据不一致或者出现故障,只能停止集群,等待迁移完成后,集群上线。
Redis3.0提供了Cluster集群。这个集群的概念和前面提到的集群有所不同。前面的集群仅代表,多个节点间没有相互的关系,只是根据客户端路由分配key到不同的节点,所有节点共同分配所有数据。3.0的Cluster功能,拥有和单机实例相同的性能,几乎支持所有命令,对于涉及多个键的命令,比如MGET,如果每一个键都在同一个节点则可以正常返回数据,否则提示错误。另外集群中限制了0号数据库,如果切换数据库则会提示错误。
哨兵和集群是两个独立的功能,但从特性来看哨兵可以视为集群的子集。当不需要数据分片或者已经利用客户端分片的场景下哨兵已经足够使用,如果需要水平扩容,Cluster是非常好的选择。
每个集群至少三台主节点。
到redis-4.0.0目录下 修改redis.conf
修改所有redis.conf文件 在GENERAL一般设置中找到daemonize 将其设置为yes 我们将后台运行redis
protect mode为no
bind ip为0.0.0.0
集群搭建成功前不要设置连接密码。
设置maxmemory 100m
cluster-enabled设置为yes
注意cluster-config-file配置不同的名称。我刚开始给每个节点都配置nodes.conf , 结果弄了几个小时都不行,一直在waiting claster join. WTF??? 工作目录明明都是自己的文件夹呀,后来在stackoverflow上 看到有人相同情况,我就改下配置文件名试了一下,还真可以了....
把redis-4.0.0文件夹复制6份
我准备了两台服务器,当然一台服务器也是可以玩转的。
六个节点分别启动,此时集群是不能正常工作的,因为他们还是六个独立的节点。下面我们要使用src目录下的redis-trib.rb来将他们加入到同一个集群当中。但是.rb由Ruby编写,我们需要安装环境,还需要gem redis包。yum install ruby下载的是2.0版本,并且得不到升级, 我们需要ruby2.2+,所以我们不使用。ruby安装指南http://blog.csdn.net/lixwjava/article/details/49231899
wget https://cache.ruby-lang.org/pub/ruby/2.2/ruby-2.2.7.tar.gz tar -zxvf ruby-2.2.7.tar.gz cd ruby-2.2.7 ./configure make make test make install 如果顺利的话就安装完ruby了
如果没有zlib 先安装一下 yum install zlib-devel yum install zlib 接下来进入ruby文件夹下ext/zlib中 安装ruby自身提供的zlib包 cd ext/zlib ruby ./extconf.rb make make install
另外需要安装openssl (不装也行) http://blog.csdn.net/yangxuan0261/article/details/52065158 如果没装,更换gem镜像为非ssl的中国ruby镜像https://ruby.taobao.org/
gem sources --add http://gems.ruby-china.org/ --remove https://rubygems.org/ gem sources -l gem install redis

在执行create cluster之前 请保证每个node的0库不包含任何key.如果有key 就对不纯洁的节点执行flushall和cluster reset 。每个Node都有一个特定的TCP端口,用来接收其他nodes的链接;此端口号为面向Client的端口号 + 10000,比如果客户端端口号为6379,那么次node的BUS端口号为16379,客户端端口号可以在配置文件中声明。由此可见,nodes之间的交互通讯是通过Bus端口进行,使用了特定的二进制协议,此端口通常应该只对nodes可用,可以借助防火墙技术来屏蔽其他非法访问。所以注意我们的所有节点端口+10000 也要保持开放
./redis-trib.rb create --replicas 1 47.92.93.157:6379 47.92.93.157:6380 47.92.93.157:6381 47.92.93.157:6382 47.92.93.157:6383 47.92.93.157:6384
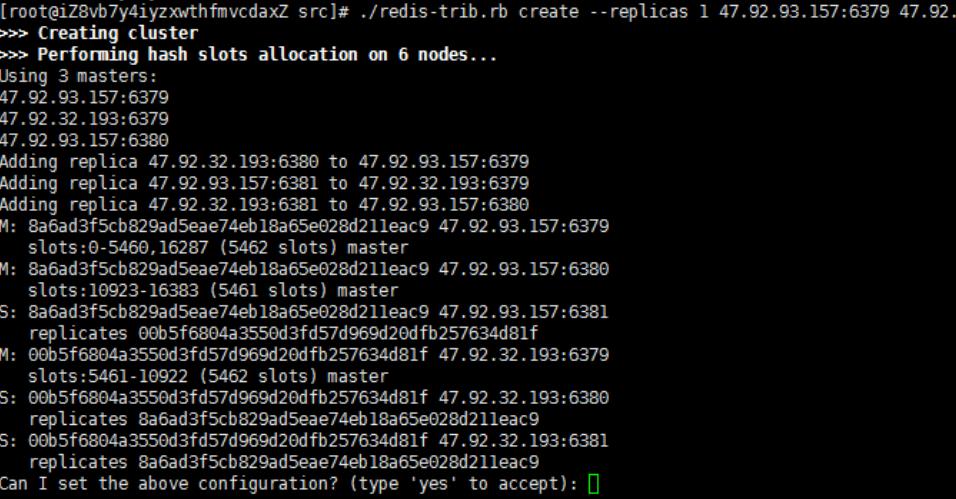
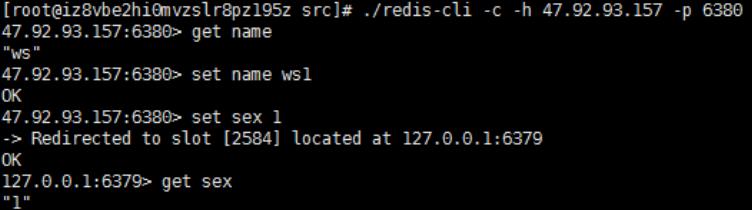
启动redis-cli 使用-c参数 连接集群,将会为我们做一些自动重定向工作。
设置集群密码:
config set masterauth abc config set requirepass abc
上面的配置 一定要每一个节点都配置执行一遍哦
config rewrite
以上是关于Redis4.0 Cluster — Centos7的主要内容,如果未能解决你的问题,请参考以下文章