HadoopHadoop IO之数据完整性
Posted LanceToBigData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HadoopHadoop IO之数据完整性相关的知识,希望对你有一定的参考价值。
前言
上一篇我分享了Hadoop的压缩和编解码器,在我们开发的过程中其实是经常会用到的,所以一定要去掌握。这一篇给大家介绍的是Hadoop的数据完整性!
Hadoop用户在使用HDFS储存和处理数据不会丢失或者损坏,在磁盘或者网络上的每一个I/O操作不太可能将错误引入自己正在读/写的数据中,但是如果
在处理的数据量非常大到Hadoop的处理极限时,数据被损坏的概率还是挺大的。
一、数据完整性概述
检测数据是否损坏的常用措施是:在数据第一次引入系统时计算校验和并在数据通过一个不可靠的同道进行传输时再一次计算校验和,这样就能发现数据是否
损坏。如果计算所得的新校验和原来的校验不匹配,那么表明数据已经损坏。
注意:该技术并不能修复数据,它只能检测出数据错误。(校验和数据也可能损坏,但是由于校验和文件小,所以损坏的可能性小)
常用的错误检测码是:CRC-32(循环冗余校验),使用CRC-32算法任何大小的数据输入均计算得到一个32位的整数校验码。
二、HDFS的数据完整性
2.1、本地文件上传到HDFS集群时的校验
下面我画了一个图好理解:
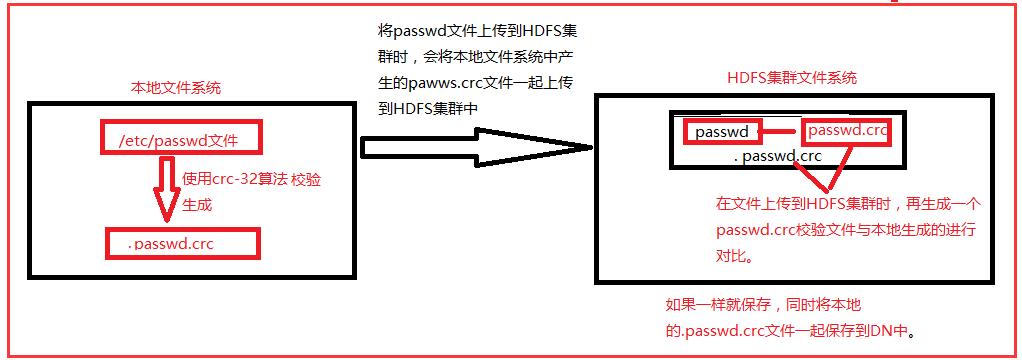
比如说我们要本地的passwd文件上传到HDFS集群中,会在本地通过CRC-32算法产生一个对passwd文件的一个校验文件:.passwd.crc。在我们将passwd上传到HDFS集群的时候,
会将本地文件系统中产生的.passwd.crc文件一起写入到HDFS集群当中。在HDFS集群中接收到数据以后也会产生一个校验文件和本地的校验文件进行比较,如果相同则会存储,
并且也会存储本地的.passwd.crc文件到数据节点中。如果不相同则不存储。
2.2、HDFS集群文件读取到本地
这里我就不画图了。
当我们客户端要去读取HDFS集群上的数据时,因为数据都是存储在DataNode当中的,所以会NameNode会告诉客户端去哪个数据块中去寻找数据,找到之后存储数据的DataNode会使用
CRC-32算法产生一个校验文件和最开始写入数据一起上传上来的校验文件进行对比。如果不相同说明数据已经损坏了,此时DataNode就会报告NameNode数据已经损坏了。这时候NameNode
就会告诉客户端这个数据块的数据不能用了,你去别的数据块中去寻找数据,这样客户端就能找到完整恩地数据。(对于损坏的数据,NameNode会重新去拷贝,进行重新的备份。)
三、涉及数据一致性的类:LocalFileSystem和RawFileSystem
3.1、概述
Hadoop的LocalFileSystem执行客户端的校验和验证。当在你写入一个filename的文件时,文件系统客户端会明确地在包含每一个文件校验和的同一个
目录内新建一个名为.filename.crc的隐藏文件。
简单的说:
当你把文件上传到HDFS集群中时,你要对文件在本地进行CRC校验就使用LocalFileSystem。
你不想对文件进行校验时就是用RawFileSystem。
3.2、编写程序验证
我们知道LocalFileSystem和RawFileSystem都是FileSystem的子类
注意:这里是在本地中对文件进行CRC检验。
1)DataIntegrity_Put_0010(上传)
import java.io.OutputStream; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.LocalFileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.RawLocalFileSystem; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class DataIntegrity_Put_0010 extends Configured implements Tool{ private FileSystem fs; private OutputStream os; @Override public int run(String[] args) throws Exception{ Configuration conf=getConf(); //不做数据校验 fs=new RawLocalFileSystem(); //因为是直接new的对象,所以这里使用这个方法去传递配置文件 fs.initialize(URI.create(args[0]),conf); os=fs.create(new Path(args[0])); os.write("123456".getBytes()); os.close(); //做数据校验 fs=new LocalFileSystem(fs); os=fs.create(new Path(args[1])); os.write("09876".getBytes()); os.close(); return 0; } public static void main(String[] args) throws Exception{ System.exit( ToolRunner.run( new DataIntegrity_Put_0010(), args)); } }
测试:
在安装了集群客户端的Linux服务器中执行:

查看:没有看到b.txt有校验文件呀。因为它是隐藏文件

我们使用ls -l a查看隐藏文件:
对于a.txt因为使用的是RawFileSystem,所以没有产生.a.txt.crc的校验文件

对于b.txt

查看.a.txt.crc文件:它是一个二进制文件

以上就是我们将文件上传到本地的文件系统时产生crc校验文件,其实就是模拟了文件上传到HDFS集群时的状态。.
2)DataIntegrity_Get_0010(读取)
import java.io.InputStream; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.LocalFileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.RawLocalFileSystem; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class DataIntegrity_Get_0010 extends Configured implements Tool{ private FileSystem fs; private InputStream is; @Override public int run(String[] args) throws Exception{ Configuration conf=getConf(); fs=new RawLocalFileSystem(); fs.initialize(URI.create(args[0]),conf); is=fs.open(new Path(args[0])); byte[] buff=new byte[1024]; int len=is.read(buff); System.out.println(new String(buff,0,len)); is.close(); fs=new LocalFileSystem(fs); is=fs.open(new Path(args[1])); byte[] buff1=new byte[1024]; int len1=is.read(buff1); System.out.println(new String(buff1,0,len1)); is.close(); return 0; } public static void main(String[] args) throws Exception{ System.exit(ToolRunner.run(new DataIntegrity_Get_0010(),args)); } }
测试:
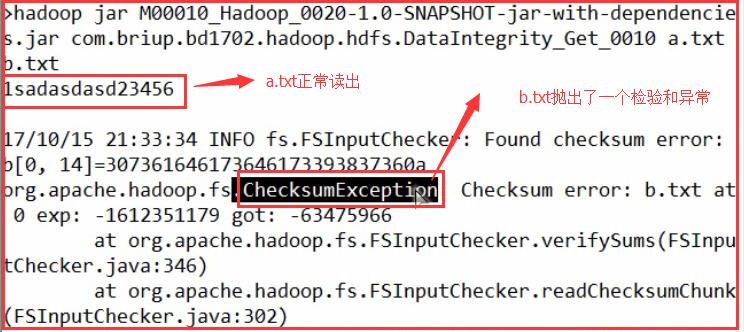
执行并产生结果:

当我们把没有做校验的a.txt修改一下:

再次运行程序是没有问题的,显示的是修改后的a.txt的数据。
当我们把做了校验的b.txt修改一下:

再次运行程序:

结果:
喜欢就点个“推荐”!
以上是关于HadoopHadoop IO之数据完整性的主要内容,如果未能解决你的问题,请参考以下文章