ElasticSearch入门:Index
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch入门:Index相关的知识,希望对你有一定的参考价值。
参考技术A 之前进行了Es集群的搭建,这次总结下Es的IndexApi,这里主要会和Solr进行部分对比来描述,如果对Solr不熟悉的可以自行略过。Es采用REST FULL的Api,这让Es具有很好的可读性,调用一目了然,当然RESTFuL的API不建议用到生产环境,原因是这种API接口基本都是短链接,这样消耗比较大,最好使用的时候,用长连接的接口进行包装,这样每次查询都是基于长连接的请求,能很好的减小服务端的开销。
一个索引请求:
这是一个ES建索引的Http接口的请求。首先,我们能很好的理解这种RESTFUL的接口,PUT代表将数据put到ES上,后面的twitter是指索引的名字,和Solr中的Collection类似。tweet是一种数据结构的描述,一个索引可能有多个type,在一个索引中所有的type的并集为这个索引的Schema。这一点是Solr中所不具有的,因为Solr是采用严格的Schema格式去限制索引的,而Es中则比较松散。
上面请求返回:
_index为索引名
_type为索引中type名称
_id为索引主键id,id是在最后指定的。如果不指定ID,ES会抛出错误,如果希望自动生成,那么需要将PUT替换为POST。如果在二级索引这种场景下,id可以和落地存储(Mongo、mysql)中数据Id一致。
_version:为版本号,版本号标识数据的版本,因为Lucene的数据merge是在Segment合并的时候进行的,所以需要version保证不会检索到过期的数据。另一方面Version可以用来避免数据并发问题,对于版本号大于之前的数据可以增加,对于小于之前数据的version会抛出异常。
created为索引标识,标识是否成功。
此时我们看一下tweet的Mapping:
此时的Mapping中我们能看到,有type,post_date和user,当然这不是绝对的,因为mapping在后面改变后会发生改变,我们重新索引下另一条doc:
我们再看下tweet的mapping:
可以看见神奇的增加了一个sex列,惊讶~~~
这一点与Solr是完全不同的,Solr是基于配置的,Solr创建好Schema之后便不能再扩充,但是ES能够灵活的改变Schema,我个人认为这是优势也是劣势,优势在于可以灵活的变更,劣势是没有约束性,可以无限的进行改变,不容易维护。
其实看到这里,熟悉Solr的人总会有个疑问,Solr和ES都是基于Lucene的。但是ES是如何抽象出type这个概念的呢?
我们在同一个索引下再创建一个Type:
这里我们创建了tweet1,同时改变了tweet1的索引结构,接下来我们看看存储结构:
Es的存储路径默认在es文件下的data目录,我们查看:data/elasticsearch/nodes/0/indices
发现一个twitter文件夹,那么这就证明不同的type是在一个索引下的,接下来我们任意选一个Shard查看:
我们发现这和Lucene的索引结构没什么区别,那么Type应该是在索引内部抽抽象出来的。
我们接下来用Head看一下,索引结构到底是什么样的。
除了Head之外,也可以用luke,但是Luke更新很慢,需要自己编译。
看到这个视图,就一目了然了,整个索引在内部抽象出了一个type索引字段,整个index的Schema是左右的type的所有字段的并集。Solr的索引实际上相当于Es的index+一个type。
但是我感觉这种机制不能应用在生产环境上,用type划分索引会导致索引结构庞大会影响检索效率,最好能一个index只含有一个type最好。
这种自动创建索引Schema的机制,可以通过下面方式关闭:
Automatic index creation can be disabled by setting action.auto_create_index to falsein the config file of all nodes. Automatic mapping creation can be disabled by setting index.mapper.dynamic tofalse in the config files of all nodes (or on the specific index settings).
ES对于Java提供了两种Client的接入:
其中NodeClient思想是启动一个Node加入到现有的ES集群中,但是此Node不存储数据,不接收HTTP的请求,这样的好处是能够及时的发现集群中节点的状态变化,同时避免请求的转发(因为Client就是一个Node)。但是坏处是要求节点必须能加入到集群,所以必须在同一个局域网内。另一点是,Client Node的停起会对集群有干扰。、
而Transport Client的方式则是作为一个独立的Client对ES的集群进行请求,类似于SolrJ。但是这种模式不能很好的确定集群中的节点当前是否可用(不是节点宕机,有可能是在recover)。同时还可能引发二次跳转(目标是请求Node2,但是请求发到Node1上,需要从Node1跳转到Node2上)。
因为NodeClient在生产中不是很常用,所以学习下Transport Client:
这里的Source是一个重载方法,既可以使用Map还可以使用String(Json)。利用jsonBuilder也是一个比较好的方法。这样就可以用Client进行索引了,但是Client里面的机制还不清楚,但是这种Client和Server的实现总是很吸引人的,接下来再慢慢学习!
elasticsearch入门
1.elasticsearch相关介绍
(1)Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
(2)Index:索引库,包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
(3)Type:类型,每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
(4)Document&field:文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
(5)Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
(6)Node:节点,集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
(7)shard(?ɑ?rd,分片):单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
(8)replica(?repl?k?,复制品):任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
2.elasticsearch安装
(1) 安装
解压即可
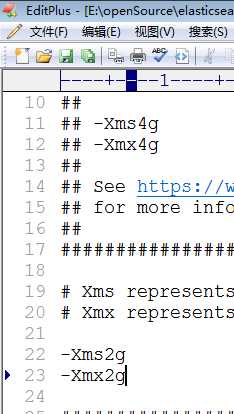
可以修改内存配置
(2) 启动
bin/elasticsearch.bat
(3)测试 -web端口
查询状态
3 集群健康状态
针对一个索引,Elasticsearch 中其实有专门的衡量索引健康状况的标志,分为三个等级:
green,绿色。这代表所有的主分片和副本分片都已分配。你的集群是 100% 可用的。
yellow,黄色。所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果更多的分片消失,你就会丢数据了。所以可把 yellow 想象成一个需要及时调查的警告。
red,红色。至少一个主分片以及它的全部副本都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。如果你只有一台主机的话,其实索引的健康状况也是 yellow,因为一台主机,集群没有其他的主机可以防止副本,所以说,这就是一个不健康的状态,因此集群也是十分有必要的
4.安装kibana客户端
1)下载
2)安装
解压即可
3)配置
配置服务器地址,编辑config/kibana.yml,设置elasticsearch.url的值为已启动的ES
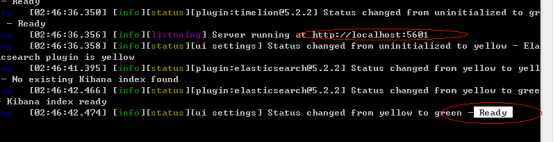
2) 启动
2) 测试
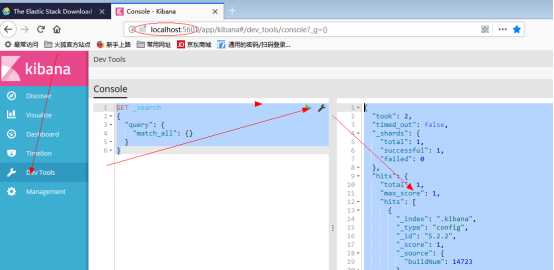
(3)crud
GET _search
{
"query": {
"match_all": {}
}
}
#新增一条数据到索引库crm中
GET crm/employee/1
{
"name":"xxxx",
"age":17
}
GET _search
#修改数据
POST crm/employee/1
{
"name":"jjjjj",
"age":20
}
#删除数据
DELETE crm/employee/1
#不输入id,会自动生成id
GET crm/employee
{
"name":"小飞",
"age":12
}
#使用生成的id查询,不输入id他会在添加一个
POST crm/employee
{
"name":"小飞机",
"age":22
}
#输入id进行修改
POST crm/employee/AW8i5TyiNXVYGBRIX5-H
{
"name":"小飞机",
"age":22
}
#获取漂亮格式,自带了的就没有了
GET crm/employee/AW8i5TyiNXVYGBRIX5-H?pretty
#获取指定的列
GET crm/employee/AW8i5TyiNXVYGBRIX5-H?_source=name
#局部更新,只更新名字
GET crm/employee/AW8i5TyiNXVYGBRIX5-H/_update
{
"doc":{
"name":"大飞机"
}
}
#批量操作
POST _bulk
{ "delete": { "_index": "itsource", "_type": "employee", "_id": "123" }}
{ "create": { "_index": "itsource", "_type": "blog", "_id": "123" }}
{ "title": "我发布的博客" }
{ "index": { "_index": "itsource", "_type": "blog" }}
{ "title": "我的第二博客" }
GET itsource/blog/_mget
{
"ids" : [ "123", "AW8iQAxERN4d1HhhqMML" ]
}
#准备分页查询数据
GET crm/students/1
{
"name":"龙"
}
GET crm/students/2
{
"name":"凤"
}
GET crm/students/3
{
"name":"呈"
}
GET crm/students/4
{
"name":"祥"
}
GET crm/students/5
{
"name":"天"
}
GET crm/students/6
{
"name":"下"
}
GET crm/students/7
{
"name":"大"
}
GET crm/students/8
{
"name":"吉"
}
#分页查询
GET crm/students/_search?size=3
GET crm/students/_search?from=2&size=2
#dsl查询
GET crm/students/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 3,
"_source": ["name", "age"],
"sort": [{"age": "asc"}]
}
#dsl过滤查询
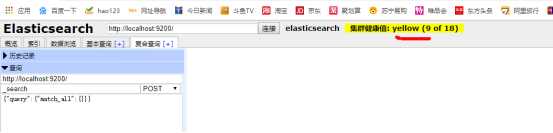
5. head工具入门+postman
进入head页面 进行安装
1)安装
下载
npm install --时间有点久
npm run start
2) 配置
跨域访问
修改 elasticsearch/config/elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
3) 使用
以上是关于ElasticSearch入门:Index的主要内容,如果未能解决你的问题,请参考以下文章