RabbitMQ笔记十三:使用@RabbitListener注解消费消息
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RabbitMQ笔记十三:使用@RabbitListener注解消费消息相关的知识,希望对你有一定的参考价值。
参考技术A之前的博客中我们可以在spring容器中构建 SimpleMessageListenerContainer 来消费消息,我们也可以使用 @RabbitListener 来消费消息。
定义消息处理器, @RabbitListener 注解标记的方法
应用启动类, @EnableRabbit 启用 @RabbitListener
测试:
控制台打印:
如果发送的消息 content_type 的属性是 text ,那么接收的消息处理方法的参数就必须是 String 类型,如果是 byte[] 类型就会报错。
控制台报错
总结
如果消息属性中没有指定 content_type ,则接收消息的处理方法接收类型是 byte[] ,如果消息属性中指定 content_type为text ,则接收消息的处理方法的参数类型是 String 类型。不管有没有指定 content_type ,处理消息方法的参数类型是Message都不会报错。
步骤
具体的消息处理方法的参数是跟 MessageConverter 转换后的java对象有关。
如果想要设置 MessageConverte r,则需要在 RabbitListenerContainerFactory 的实例中去设置,( setMessageConverter 方法)
获取单一个Header的属性,Header还有其他的一些属性,比如 required , defaultvalue 等属性,顾名思义:
配置文件:
启动类:
定义mq中不存在的 Queue , exchange 和 route key
从上面的我们知道声明必须容器中要有 RabbitAdmin 和 RabbitTemplate 实例
应用启动类
测试验证
控制台打印:
说明自动声明的绑定中的队列被自动默认监听。 @RabbitListener 注解中的 bindings 和 queues 参数不能同时指定,否则会报错。
@RabbitListener 可以标注在类上面,当使用在类上面的时候,需要配合 @RabbitHandler 注解一起使用, @RabbitListener 标注在类上面表示当有收到消息的时候,就交给带有 @RabbitHandler 的方法处理,具体找哪个方法处理,需要跟进 MessageConverter 转换后的java对象。
配置:
处理器方法
应用启动类:
发送不包含content_type属性的消息和content_type属性为text的消息,控制台打印:
@RabbitListener 注解的 containerFactory 属性可以指定一个 RabbitListenerContainerFactory 的bean,默认是找名字为 rabbitListenerContainerFactory 的实例。
当我们将 ConsumerConfig 类中的 RabbitListenerContainerFactory 实例的对象名改掉的时候,发现就会报错。
此时控制台上报错,
此时如果配置一下 @RabbitListener 注解的 containerFactory 属性便不会报错。
我们再去改造一下在 RabbitListenerContainerFactory 实例中定义消息类型转换器
User对象:
在处理器中增加参数是User的方法:
Spring Boot(十三)RabbitMQ安装与集成
一、前言
RabbitMQ是一个开源的消息代理软件(面向消息的中间件),它的核心作用就是创建消息队列,异步接收和发送消息,MQ的全程是:Message Queue中文的意思是消息队列。
## 1.1 使用场景 - 削峰填谷:用于应对间歇性流量提升对于系统的“破坏”,比如秒杀活动,可以把请求先发送到消息队列在平滑的交由系统去处理,当访问量大于一定数量的时候,还可以直接屏蔽后续操作,给前台的用户友好的显示; - 延迟处理:可以进行事件后置,比如订单超时业务,用户下单30分钟未支付取消订单; - 系统解耦:消息队列也可以帮开发人员完成业务的解耦,比如用户上传头像的功能,最初的设计是用户上传完之后才能发帖,后面有增加了经验系统,需要在上传头像之后增加经验值,到后来又上线了金币系统,上传头像之后可以增加金币,像这种需求的不断升级,如果在业务代码里面写死每次该业务代码是很不优雅的,这个时候如果使用消息队列,那么只需要增加一个订阅器用于介绍用户上传头像的消息,再执行经验的增加和金币的增加是非常简单的,并且在不改动业务模块业务代码的基础上可以轻松实现,如果后期需要撤销某个模块了,只需要删除订阅器即可,就这样就降低了系统开发的耦合性; ## 1.2 为什么使用RabbitMQ? 现在市面上比较主流的消息队列还有Kafka、RocketMQ、RabbitMQ,它们的介绍和区别如下: - Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache定级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。 - RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。 - RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。 **简单总结:** Kafka的性能最好,适用于对消息吞吐量达,对消息丢失不敏感的系统;RocketMQ借鉴了Kafka并提高了消息的可靠性,修复了Kafka的不足;RabbitMQ性能略低于Kafka,并实现了AMQP(Advanced Message Queuing Protocol)高级消息队列协议的标准,有非常好的稳定性。 **支持语言对比** - RocketMQ 支持语言:Java、C++、Golang - Kafka 支持语言:Java、Scala - RabbitMQ 支持语言:C#、Java、Js/NodeJs、Python、Ruby、Erlang、Perl、Clojure、Golang ## 1.3 RabbitMQ特点 RabbitMQ的特点是易用、扩展性好(集群访问)、高可用,具体如下: - 可靠性:持久化、消息确认、事务等保证了消息的可靠性; - 伸缩性:集群服务,可以很方便的添加服务器来提高系统的负载; - 高可用:集群状态下部分节点出现问题依然可以运行; - 多语言支持:RabbitMQ几乎支持了所有的语言,比如Java、.Net、Nodejs、Golang等; - 易用的管理页面:RabbitMQ提供了易用了网页版的管理监控系统,可以很方便的完成RabbitMQ的控制和查看; - 插件机制:RabbitMQ提供了许多插件,可以丰富和扩展Rabbit的功能,用户也可编写自己的插件; ## 1.4 RabbitMQ基础知识 在了解消息通讯之前首先要了解3个概念:生产者、消费者和代理。 生产者:消息的创建者,负责创建和推送数据到消息服务器; 消费者:消息的接收方,用于处理数据和确认消息; 代理:就是RabbitMQ本身,用于扮演“快递”的角色,本身不生产消息,只是扮演“快递”的角色。 ### (一)消息发送原理 首先你必须连接到Rabbit才能发布和消费消息,那怎么连接和发送消息的呢? 你的应用程序和Rabbit Server之间会创建一个TCP连接,一旦TCP打开,并通过了认证,认证就是你试图连接Rabbit之前发送的Rabbit服务器连接信息和用户名和密码,有点像程序连接数据库,使用Java有两种连接认证的方式,后面代码会详细介绍,一旦认证通过你的应用程序和Rabbit就创建了一条AMQP信道(Channel)。 信道是创建在“真实”TCP上的虚拟连接,AMQP命令都是通过信道发送出去的,每个信道都会有一个唯一的ID,不论是发布消息,订阅队列或者接收消息都是通过信道完成的。 ### (二)为什么不通过TCP直接发送命令? 对于操作系统来说创建和销毁TCP会话是非常昂贵的开销,假设高峰期每秒有成千上万条连接,每个连接都要创建一条TCP会话,这就造成了TCP连接的巨大浪费,而且操作系统每秒能创建的TCP也是有限的,因此很快就会遇到系统瓶颈。 如果我们每个请求都使用一条TCP连接,既满足了性能的需要,又能确保每个连接的私密性,这就是引入信道概念的原因。  ### (三)RabbitMQ名称解释 **ConnectionFactory(连接管理器):** 应用程序与Rabbit之间建立连接的管理器,程序代码中使用; **Channel(信道):** 消息推送使用的通道; **Exchange(交换器):** 用于接受、分配消息; **Queue(队列):** 用于存储生产者的消息; **RoutingKey(路由键):** 用于把生成者的数据分配到交换器上; **BindingKey(绑定键):** 用于把交换器的消息绑定到队列上; 看到上面的解释,最难理解的路由键和绑定键了,那么他们具体怎么发挥作用的,请看下图: 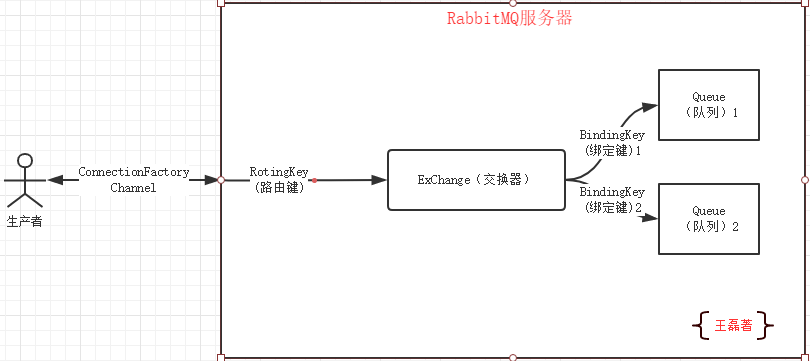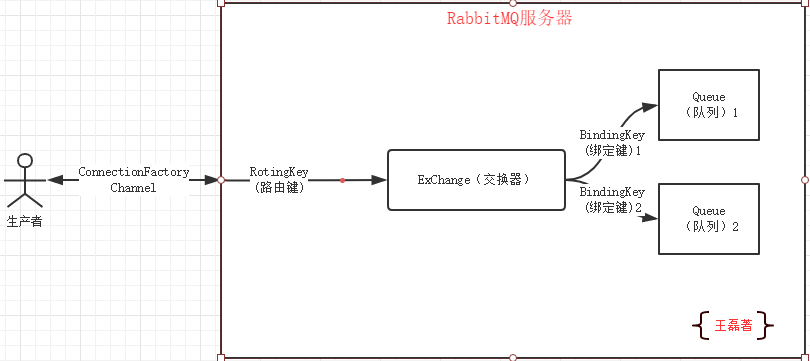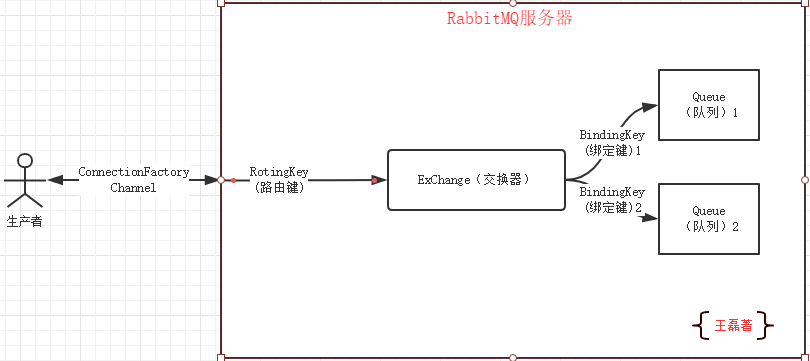 ## 1.5 交换器分类 RabbitMQ的Exchange(交换器)分为四类: - direct(默认) - headers - fanout - topic 其中headers交换器允许你匹配AMQP消息的header而非路由键,除此之外headers交换器和direct交换器完全一致,但性能却很差,几乎用不到,所以我们这里不做解释。 ### 1.5.1 direct交换器 direct为默认的交换器类型,也非常的简单,如果路由键匹配的话,消息就投递到相应的队列,如下图: 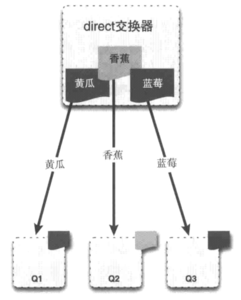 ### 1.5.2 fanout交换器 fanout有别于direct交换器,fanout是一种发布/订阅模式的交换器,当你发送一条消息的时候,交换器会把消息广播到所有附加到这个交换器的队列上。 **注意:** 对于fanout交换器来说routingKey(路由键)是无效的,这个参数是被忽略的。 ### 1.5.3 topic交换器 topic交换器运行和fanout类似,但是可以更灵活的匹配自己想要订阅的信息,这个时候routingKey路由键就排上用场了,使用路由键进行消息(规则)匹配。 topic路由器的关键在于定义路由键,定义routingKey名称不能超过255字节,使用“.”作为分隔符,例如:com.mq.rabbit.error。 **匹配规则** 匹配表达式可以用“*”和“#”匹配任何字符,具体规则如下: - “*”匹配一个分段(用“.”分割)的内容; - “#”匹配所有字符; 例如发布了一个“cn.mq.rabbit.error”的消息: 能匹配上的路由键: - `cn.mq.rabbit.*` - `cn.mq.rabbit.#` - `#.error` - `cn.mq.#` - `#` 不能匹配上的路由键: - `cn.mq.*` - `*.error` - `*` ## 1.6 消息持久化 RabbitMQ队列和交换器有一个不可告人的秘密,就是默认情况下重启服务器会导致消息丢失,那么怎么保证Rabbit在重启的时候不丢失呢?答案就是消息持久化。 当你把消息发送到Rabbit服务器的时候,你需要选择你是否要进行持久化,但这并不能保证Rabbit能从崩溃中恢复,想要Rabbit消息能恢复必须满足3个条件: 1. 投递消息的时候durable设置为true,消息持久化,代码:channel.queueDeclare(x, true, false, false, null),参数2设置为true持久化; 2. 设置投递模式deliveryMode设置为2(持久),代码:channel.basicPublish(x, x, MessageProperties.PERSISTENT_TEXT_PLAIN,x),参数3设置为存储纯文本到磁盘; 3. 消息已经到达持久化交换器上; 4. 消息已经到达持久化的队列; **持久化工作原理** Rabbit会将你的持久化消息写入磁盘上的持久化日志文件,等消息被消费之后,Rabbit会把这条消息标识为等待垃圾回收。 **持久化的缺点** 消息持久化的优点显而易见,但缺点也很明显,那就是性能,因为要写入硬盘要比写入内存性能较低很多,从而降低了服务器的吞吐量,尽管使用SSD硬盘可以使事情得到缓解,但他仍然吸干了Rabbit的性能,当消息成千上万条要写入磁盘的时候,性能是很低的。 所以使用者要根据自己的情况,选择适合自己的方式。 学习更多RabbitMQ知识,访问:https://gitbook.cn/gitchat/activity/5b558d54c28306099b47ae9c # 二、在Docker中安装RabbitMQ **(1)下载镜像** https://hub.docker.com/r/library/rabbitmq/tags/ - alpine 轻量版 - management 带插件的版本 从镜像的大小也可以很直观的看出来alpine是轻量版。 使用命令: > docker pull rabbitmq:3.7.7-management 下载带management插件的版本。 **(2)运行RabbitMQ** 使用命令: > docker run -d --hostname myrabbit --name rabbit -p 15672:15672 -p 5672:5672 rabbitmq:3.7.7-management - -d 后台运行 - --hostname 主机名称 - --name 容器名称 - -p 15672:15672 http访问端口,映射本地端口到容器端口 - -p 5672:5672 amqp端口,映射本地端口到容器端口 正常启动之后,访问:http://localhost:15672/ 登录网页管理页面,用户名密码:guest/guest,登录成功如下图:  # 三、RabbitMQ集成 ## 3.1 添加依赖 如果用Idea创建新项目,可以直接在创建Spring Boot的时候,点击“Integration”面板,选择RabbitMQ集成,如下图:  如果是老Maven项目,直接在pom.xml添加如下代码: ```xml以上是关于RabbitMQ笔记十三:使用@RabbitListener注解消费消息的主要内容,如果未能解决你的问题,请参考以下文章
RabbitMQ消息队列(十三)-VirtualHost与权限管理
RabbitMQ入门教程(十三):虚拟主机vhost与权限管理
Spring Boot (十三): Spring Boot 整合 RabbitMQ