正则表达式.+可以匹配空格,但是[.\w]+却不匹配,为啥?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式.+可以匹配空格,但是[.\w]+却不匹配,为啥?相关的知识,希望对你有一定的参考价值。
>>>importre...print(re.match(r'[.\w]',''))#匹配单空格...print(re.match(r'.',''))...print(re.match(r'(.|\w)',''))...None<re.Matchobject;span=(0,1),match=''><re.Matchobject... >>>import re ...print(re.match(r'[.\w]', ' ')) # 匹配单空格 ...print(re.match(r'.', ' ')) ...print(re.match(r'(.|\w)', ' ')) ... None <re.Match object; span=(0, 1), match=' '> <re.Match object; span=(0, 1), match=' '> [\w.]应匹配\w或.。为什么[\w.]无法捕获空格? 展开
参考技术A 在正则表达式中.表示除换行外的所有字符,所以.+可以匹配空格[]中括号表示字符集,在中括号中".*?+"等特殊字符就表示其自身,所以[.\w]就表示小数点字符加上\w表示的字符组成的字符集,并不包括空格
正则表达式 学习笔记
1、^
字符串的起始位置
2、$
字符串的结束位置
3、\\b
匹配单词的边界,但是不消耗任何一个字符串的位置,只是用来判断而已,比如:
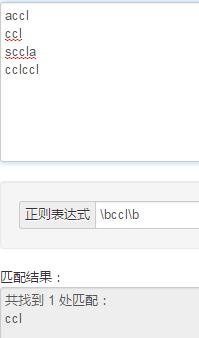
4、\\d
数字
5、\\D
任意非数字
6、\\w
数字、字母、下划线
7、\\W
任意非数字、字母、下划线
8、\\s
空格
9、\\S
任意非空格
10、.
匹配除换行符以外的任意字符
11、[abc]
字符组,匹配括号里面存在的字符
12、*
重复0次或多次
13、+
重复一次或多次
14、?
重复0次或1次
15、{n}
重复n次
16、{n, m}
重复n-m次
17、{n, }
重复n到更多次
18、懒惰限定符
(1) *?
重复任意次,但尽可能少重复 。如: "acbacb" 正则 "a.*?b" 只会取到第一个"acb" 原本可以全部取到但加了限定符后,只会匹配尽可能少的字符 ,而"acbacb"最少字符的结果就是"acb"
(2) +?
重复1次或更多次,但尽可能的少重复。
(3) ??
重复0次或1次,但尽可能少重复.如: "aaacb" 正则 "a.??b" 只会取到最后的三个字符"acb"
(4) {n,m}?
重复n到m次,但尽可能少重复.如:"aaaaaaaa" 正则 "a{0,m}" 因为最少是0次所以取到结果为空
(5) {n,}?
重复n次以上,但尽可能少重复.如:"aaaaaaa" 正则 "a{1,}" 最少是1次所以取到结果为 "a"
19、捕获分组
(1)分组 ()
用()进行分组,对于分组来说,表达式永远是算作第一组,可以使用\\1来向后引用,简化表达式,三十这里要注意,不能(\\1),因为这样的话引用的是文本内容,而不是正则表达式,也就是说,当一个组中的内容匹配成功之后,向后引用,引用的就是匹配成功之后的内容,而不是表达式
(2)不捕获 ?:
不捕获就是在分组的前面加上 ?: ,可以在不需要捕获分组的表达式中试用,加快表达式的执行速度。
(3)断言 (?<=)
断言就是只某个字符串的前面或后面,将会出现满足某种规律的字符串,匹配的内容不包括断言的内容
断言分为两种方式:
《1》正后发断言 (?<=匹配的字符串)
《2》正先行断言 (?=匹配的字符串)
!表示正好相反的意思,就是把=换成了!,看表格解释,X代表字符
|
(?=X ) |
零宽度正先行断言。仅当子表达式 X 在 此位置的右侧匹配时才继续匹配。例如,\\w+(?=\\d) 与后跟数字的单词匹配,而不与该数字匹配。此构造不会回溯。 |
|
(?!X) |
零宽度负先行断言。仅当子表达式 X 不在 此位置的右侧匹配时才继续匹配。例如,例如,\\w+(?!\\d) 与后不跟数字的单词匹配,而不与该数字匹配 。 |
|
(?<=X) |
零宽度正后发断言。仅当子表达式 X 在 此位置的左侧匹配时才继续匹配。例如,(?<=19)99 与跟在 19 后面的 99 的实例匹配。此构造不会回溯。 "How are you doing" 正则"(?<txt>(?<=How).+)" 这里取"How"之后所有的字符,并定义了一个捕获分组名字为 "txt" 而"txt"这个组里的值为" are you doing"; |
|
(?<!X) |
零宽度负后发断言。仅当子表达式 X 不在此位置的左侧匹配时才继续匹配。例如,(?<!19)99 与不跟在 19 后面的 99 的实例匹配 |
(4)捕获分组
(exp)匹配exp,并捕获文本到自动命名的组里
(?:exp)匹配exp,不捕获匹配的文本,也不给此分组分配组号
(?<name>exp)匹配exp,并捕获文本到名称为name的组里
以上是关于正则表达式.+可以匹配空格,但是[.\w]+却不匹配,为啥?的主要内容,如果未能解决你的问题,请参考以下文章