数据库mysql操作(查询)
Posted bethansy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库mysql操作(查询)相关的知识,希望对你有一定的参考价值。
1、根据条件查询数据库中数据,并返回数据条数
去掉count就会返回数据库中符合条件的所有数据
SELECT COUNT(*) FROM sentiment_info WHERE sentiment_source=\'海丝商报\' AND sentiment_type=\'要闻\' AND sentiment_source_id=\'1056162\'
其他查询操作:
select * from tab where id>1464 delete from tab where id>1464 # 删除数据
select * from tablename order by id+0 desc LIMT 1 # id+0将字符串的id变成int类型,desc是降序,LIMT1只取1条
select * from tab where id=(select max(id) from tab) # 子查询
最后一条语句和倒数第二条语句得到的结果是一样的,只是倒数第二条的id可能是字符串格式
我想在python中也得到返回数据条数,即执行sql语句的都返回结果21,
>>> import pymysql >>> conn = pymysql.connect(host=\'localhost\', user=\'root\', passwd=\'123\', db=\'tianyan\', port=3306, charset=\'utf8\') >>> cur = conn.cursor() >>> sql="SELECT COUNT(*) FROM sentiment_info WHERE sentiment_source=\'海丝商报\' AND sentiment_type=\'要闻\' AND sentiment_source_id=\'1056162\'" >>> c=cur.execute(sql) >>> c 1 >>> cur.execute(sql) 1 >>> cur.fetchall() ((21,),)
执行sql语句得到的返回结果只能是0或者1,可以看到通过fetchall()来得到,最终只要max(max(cur.fetchall())) 既可以得到21.但是我想应该有个更简介的方式,如果需要传值的话采用下面的操作方式
>>> sql = """SELECT COUNT(*) FROM sentiment_info WHERE sentiment_source=\'海丝商报\' AND sentiment_type=\'要闻\'AND sentiment_source_id=\'%s\'""" %content_id >>> sql "SELECT COUNT(*) FROM sentiment_info WHERE sentiment_source=\'海丝商报\' AND sentiment_type=\'要闻\'AND sentiment_source_id=\'1056121\'" >>> cur.execute(sql) 1
2、建立一个数据库表
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for ent_basic
-- ----------------------------
DROP TABLE IF EXISTS `ent_basic`;
CREATE TABLE `ent_basic` (
`ent_uid` varchar(100) DEFAULT NULL,
`ent_code` varchar(100) DEFAULT NULL COMMENT \'企业代码\',
`ent_category` tinyint(4) DEFAULT \'1\' COMMENT \'企业类别:生产型,流通型\',
`row_id` bigint(20) NOT NULL AUTO_INCREMENT,
`created_dt` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`created_by` varchar(30) NOT NULL DEFAULT \'sys\',
`last_upd_dt` timestamp NOT NULL DEFAULT \'0000-00-00 00:00:00\' ON UPDATE CURRENT_TIMESTAMP,
`last_upd_by` varchar(30) NOT NULL DEFAULT \'sys\',
`ent_social_no` varchar(100) DEFAULT NULL COMMENT \'社会信用代码\',
`entStatus` varchar(45) DEFAULT NULL COMMENT \'状态:存续、注销、在业\',
`ent_scale` varchar(50) DEFAULT NULL COMMENT \'公司规模\',
`crawler_ver` varchar(50) DEFAULT NULL COMMENT \'爬取版本(时间戳)\',
`is_import` int(1) DEFAULT NULL COMMENT \'是否导入1是,其他不是\',
PRIMARY KEY (`row_id`),
UNIQUE KEY `ent_basic_uni_key_regno` (`ent_reg_no`) USING BTREE,
KEY `index_search` (`ent_name`,`ent_reg_no`)
) ENGINE=InnoDB AUTO_INCREMENT=817190 DEFAULT CHARSET=utf8;
重命名表:rename oldname newname
3、修改字段的类型
例如将数据表sentiment_info 中字段sentiment_content的字符集由text修改为utf8
alter table `sentiment_info` modify column `sentiment_content` text character set utf8 not null;
alter table tablename change id id int not null auto_increment primary key # 将id字段定义为自增字段
4、Python中向mysql插入多条语句
>>> T=((\'1\',\'纵横通信\'),(\'2\',\'恒为科技\'),(\'3\',\'中孚信息\')) >>> conn <pymysql.connections.Connection object at 0x000000000525A438> >>> cur <pymysql.cursors.Cursor object at 0x0000000005281DD8> >>> cur.executemany("insert into ent_competor (id, product) values(%s,%s)",T)
>>> 3
返回结果为3,说明插入成功。注意插入数据库的数据必须是元组形式,先换格式,再讲data插入。其中id字段如果作为主键以后,id的值不能重复,否则会报错,也不能为空,必须要插入
>>> result [[\'2\', \'纵横通信\', \'浙江\', \'IPO上市\', \'企业服务\', \'延伸网络技术服务提供商\', \'2006-12-28\', \'\'], [\'2\', \'恒为科技\', \'上海\', \'IPO上市\', \'企业服务\', \'信息安全服务提供商\', \'2003-03-31\', \'\'], [\'2\', \'中孚信息\', \'山东\', \'IPO上市\', \'企业服务\', \'信息安全服务提供商\', \'2002-03-12\', \'\'], [\'2\', \'熙菱信息\', \'新疆\', \'IPO上市\', \'企业服务\', \'信息安全领域产品提供商\', \'\', \'\'], [\'2\', \'华创网安\', \'北京\', \'定向增发\', \'企业服务\', \'网络安全及舆情监测服务商\', \'2010-04-16\', \'\'], [\'2\', \'辰安科技\', \'北京\', \'IPO上市\', \'企业服务\', \'公共安全服务提供商\', \'2015-05-19\', \'\'], [\'2\', \'绿盟科技\', \'北京\', \'IPO上市\', \'企业服务\', \'企业级信息安全服务商\', \'2000-04-25\', \'\'], [\'2\', \'任子行\', \'广东\', \'IPO上市\', \'企业服务\', \'网络信息安全服务商\', \'2000-05-31\', \'\'], [\'2\', \'美亚柏科\', \'福建\', \'IPO上市\', \'企业服务\', \'数据取证及网络安全服务商\', \'1999-09-22\', \'\'], [\'2\', \'证通电子\', \'广东\', \'IPO上市\', \'企业服务\', \'金融支付信息安全设备提供商\', \'1993-09-04\', \'\']] >>> data = list(map(tuple, result)) >>> data [(\'2\', \'纵横通信\', \'浙江\', \'IPO上市\', \'企业服务\', \'延伸网络技术服务提供商\', \'2006-12-28\', \'\'), (\'2\', \'恒为科技\', \'上海\', \'IPO上市\', \'企业服务\', \'信息安全服务提供商\', \'2003-03-31\', \'\'), (\'2\', \'中孚信息\', \'山东\', \'IPO上市\', \'企业服务\', \'信息安全服务提供商\', \'2002-03-12\', \'\'), (\'2\', \'熙菱信息\', \'新疆\', \'IPO上市\', \'企业服务\', \'信息安全领域产品提供商\', \'\', \'\'), (\'2\', \'华创网安\', \'北京\', \'定向增发\', \'企业服务\', \'网络安全及舆情监测服务商\', \'2010-04-16\', \'\'), (\'2\', \'辰安科技\', \'北京\', \'IPO上市\', \'企业服务\', \'公共安全服务提供商\', \'2015-05-19\', \'\'), (\'2\', \'绿盟科技\', \'北京\', \'IPO上市\', \'企业服务\', \'企业级信息安全服务商\', \'2000-04-25\', \'\'), (\'2\', \'任子行\', \'广东\', \'IPO上市\', \'企业服务\', \'网络信息安全服务商\', \'2000-05-31\', \'\'), (\'2\', \'美亚柏科\', \'福建\', \'IPO上市\', \'企业服务\', \'数据取证及网络安全服务商\', \'1999-09-22\', \'\'), (\'2\', \'证通电子\', \'广东\', \'IPO上市\', \'企业服务\', \'金融支付信息安全设备提供商\', \'1993-09-04\', \'\')]
4.2 将一个一个dataframe数据表一次性入库到数据库中
from sqlalchemy import create_engine
sql = \'\'\'
select Idx,cx,ch,speed,mileage,Iouttemperature,IIouttemperature,axletemperatures,DataTime from dbo.YZD_Temp_Data
\'\'\'
cur.execute(sql)
df = pd.DataFrame(cur.fetchall())
engine = create_engine(\'mysql+pymysql://root:yunda@10.2.3.72:3308/zxb\')
try:
pd.io.sql.to_sql(df, \'tempdata_pre\', engine, schema=\'zxb\', index=False, if_exists=\'append\')
except Exception as e:
print(e)
\'\'\'对查询到的中文数据进行编码处理 \'\'\'
cur.execute(sql)
data = cur.fetchall()
for i in range(len(data)):
data[i] = list(data[i])
if data[i][4] != None:
data[i][4] = data[i][4].encode(\'latin-1\').decode(\'gbk\')
res = pd.DataFrame(data, columns=list(zip(*cur.description))[0])
5、mysql中截取某字段的其中一部分作为新的字段
(1)首先在数据库中手动添加新字段,然后再更新新字段。
(2)样例
内容 姓名
小明是个老师 无
小张是个学生 无
================
要实现的结果是
内容 姓名
小明是个老师 小明
小张是个嘘声 小张
谢谢,很着急,在线等
UPDATE tab SET 姓名 = SUBSTRING(内容, 1, 2) # 取内容的前两个字符赋值给姓名字段
SELECT 内容, SUBSTRING(内容, 1, 4) FROM tab
6、数据库中删除某列长度小于4096的所有行
delete from table where length(column)<4096
7、计算某个字符串字段(column)中逗号的个数
select length(column)-length(replace(column,\',\',\'\'))as A from test
DELETE from test WHERE datatime IN( SELECT B.* from (
select datatime from test WHERE length(`DATA`)-length(replace(`DATA`,\',\',\'\')) < 4095) as B)
如果计算某个字符串字段逗号个数小于4096个点,需要找一个主键字段进行匹配,由于表中没有主键,其中datatime也是独一无二的拿来代替主键进行定位。
查询出来的中间表需要给他一个名称作为新表,一个表是不能同时进行查询和和删除操作的
8、两个表根据某个字段进行拼接 左连接,右连接,全连接
select yzd_Im_Origin.cx ,yzd_Im_Origin.alarmtag from dbo.yzd_Im_Origin left join yzd_sv_trend on yzd_sv_trend.DataTime = yzd_Im_Origin.DataTime
9 、将表1的数据插入到表2中
(1)如果两个表结构一致
insert into yzd_bearing_label_new SELECT * from yzd_bearing_label_1
(2)如果两个表结构不一致
INSERT into yzd_bearing_label_new (`Cx`,`Ch`,`Routes`) select `Cx`,`Ch`,`Routes` from yzd_bearing_label_1
(3)或者导出.sql文件,在需要添加的表的数据库运行sql,复制到查询语句中去运行
(4)将服务器上的数据导入到本地中
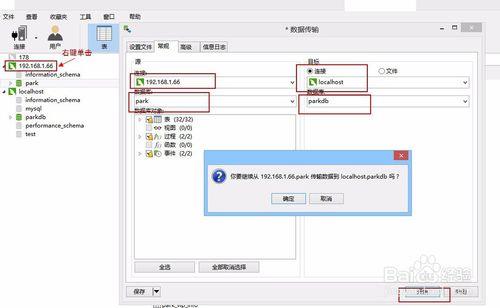
10、更新数据库某个字段的值
sql = \'\'\'update shujufenxi_temp_sv set axletemp= %s ,temprise=%s where ch=\'%s\' and cx=\'%s\' and axleplace=%d and datatime=\'%s\' \'\'\'\\
%(data1[\'axletemp\'][i],data1[\'temprise\'][i],data1[\'ch\'][i],data1[\'cx\'][i],int(data1[\'axleplace\'][i]),data1[\'maxdata\'][i])
(1)更新多个字段采用逗号分隔
(2)这个问题暂时没有解决,想要一次性批量更新数据库表某个字段的值
描述:
数据库中有一个data表,包含以下字段,其中其中温度一列数据为空:冲击值,车型,车号,时间,温度
python从另一个渠道获取得到了另一份数据,包含字段:时间,车型,车号,温度
目标:想要将python存储区间的温度数据更新data表中,限定条件就是对应的时间、车型、车号匹配起来,能不能不一条条进行匹配,能不能批量操作
11、联结
内部联结:SELECT customer.cust_id,orders.order_num FROM customers INNER JOIN orders ON customer.cust_id=orders.cust_id
≈ SELECT customer.cust_id,orders.order_num FROM customers, orders where customer.cust_id =orders.cust_id
外部联结:SELECT customer.cust_id,orders.order_num FROM customers LEFT OUTER JOIN orders ON customer.cust_id=orders.cust_id
≈ SELECT customer.cust_id,orders.order_num FROM customers, orders where customer.cust_id *=orders.cust_id
右外部联结:=*
全外部联结 SELECT customer.cust_id,orders.order_num FROM customers FULL OUTER JOIN orders ON customer.cust_id=orders.cust_id
带聚集函数的联结:
SELECT customer.cust_id,COUNT(orders.order_num) as num_ord FROM customers INNER JOIN orders ON customer.cust_id=orders.cust_id GROUP BY customers.cust_id
12、组合查询--UNION
试用范围:(1)单个表执行多个查询,例如多个where都可以用union连接;(2)不同表返回类似结构数据
规则:(1)必须由两条或两条以上select语句组成,语句间用union分隔
(2)union连接的每个查询必须包含相同的列、表达式或聚集函数,列序无要求
(3)列类型需要兼容
(4)重复的行会被取消
SELECT cust_contact,cust_email FROM Customers WHERE cust_state IN (\'IL\',\'IN\',\'ML\')
UNION
SELECT cust_contact,cust_email FROM Customers WHERE cust_name =\'Fun4All\'
≈
SELECT cust_contact,cust_email FROM Customers WHERE cust_state IN (\'IL\',\'IN\',\'ML\')
OR cust_name =\'Fun4All\'
13、插入数据
13.1 方式
(1)插入完整的行;
INSERT INTO Customer Values(\' \',\' \',\' \',\' \',\' \') 这种不定义顺序的其实不好,必须是全表插,也可以写成下面的形式
(2)插入行的一部分
INSERT INTO Customer(id,name,address,city,state) Values(\' \',\' \',\' \',\' \',\' \')
(3)插入某些查询结果
INSERT INTO Customer(id,name,address,city,state) SELECT id,name,address,city,state from CustNew
INSERT SELECT 可用单条INSERT插入多行
(4)从一个表复制到另一个表 SELECT INTO
SELECT * INTO CustCopy FROM Customer ≈ CREATE TABLE CustCopy AS SELECT * FROM Customer
13.2 在原表的基础上插入一个自增字段
alter table tablename add id int # 添加字段 alter table tablename change id id int not null auto_increment primary key # 将id字段定义为自增字段
14、更新和删除数据
14.1 更新
(1)更新表中特定的行
UPDATE Customer SET cust_email=‘kimthestore.com’ where cust_id=‘10005’
(2)更新表中所有的行
UPDATE Customer SET cust_email=‘kimthestore.com’
14.2 删除
删除行:delete from table where id=‘’
删列:ALTER TABLE tablename DROP COLUMN columnname
删除表:
(1)把整个表都删除:drop table 表名
(2)删除表中的所有数据:清空全部数据,不写日志,不可恢复,速度极快
truncate table 表名; 清空全部数据,写日志,数据可恢复,速度慢 delete from 表名14.3 删除表中的重复数据,并保留唯一一条记录
(1)所有字段完全一样
从table表中查询到非重复数据,复制到新表中,然后删除原表
CREATE TABLE TABLECopy AS SELECT DISTINCT * FROM TABLE
(2)删除某几个字段一样的数据,例如其中id不相同
select * from tab_relation where num in (select min(num) from tab_relation group by mb_id1, mb_id2, relation)
下面的语句删除重复数据直接保留一条数据,但是mysql数据库不支持这个语法,只有重新生成一个临时表了
delete from tab_relation where num not in (select min(num) from tab_relation group by mb_id1, mb_id2, relation)
15、函数
LEFT(): 返回字符串左边的字符
LENGTH() :返回字符串长度
LTRIM()/RIGHT():去掉串左边/右边的空格
UPPER()/LOWER():大小写转换
日期处理函数:DATEPART(yy,order_date)=2004
to_date(\'01-JAN-2004\') 将字符串转换成日期
聚集函数:GREATEST() /LEAST() 最大值最小值
AVG(),COUNT(),MAX(),MIN(),SUM() count(*)计算行数
分组:
使用groupby函数后,where前select后的字段必须使用聚合函数或者就是groupby的数据
16、mysql分组后取每组的前3行
https://blog.csdn.net/wangsg2014/article/details/58596980
以上是关于数据库mysql操作(查询)的主要内容,如果未能解决你的问题,请参考以下文章