ORM框架SQLAlchemy的使用
Posted follow your heart.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ORM框架SQLAlchemy的使用相关的知识,希望对你有一定的参考价值。
ORM和SQLAlchemy简介
对象关系映射(Object Relational Mapping,简称ORM),简单的来说,ORM是将数据库中的表与面向对象语言中的类建立了一种对应的关系。然后我们操作数据库的时候,数据库中的表或者表中的某一行,直接通过操作类或者类的实例就可以完成了。

SQLAlchemy是Python社区最知名的ORM工具之一,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型。
SQLAlchemy是建立在数据库API之上,使用关系对象映射进行数据库操作,简单的来说,就是将对象转换成数据行,类转换成数据表,然后使用数据库API执行SQL并获取执行结果。
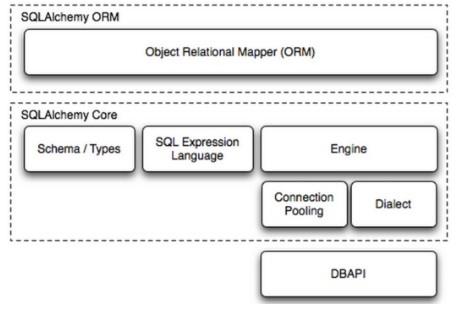
SQLAlchemy本身是无法是操作数据库的,必须借助第三方插件,比如mysqldb,pymysql。
SQLAlchemy的安装
python3.x自带pip3,可以直接安装:
C:\\Windows\\system32>pip3 install sqlalchemy
连接和创建
在MySQL服务器上,首先需要自己创建数据库:
mysql> create database db6;
Query OK, 1 row affected (0.00 sec)
连接数据库:
from sqlalchemy import create_engine engine = create_engine(\'mysql+pymysql://root:LBLB1212@@@localhost:3306/db6\') print(engine) #运行结果 Engine(mysql+pymysql://root:***@localhost:3306/db6)
如果出现以上的结果,说明已经连接成功了,这里使用的pymysql,不同的数据库或者第三方插件,create_engine的字符串是不同的:
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...] 更多可见官方文档:http://docs.sqlalchemy.org/en/latest/dialects/index.html
现在连接已经成功了,那么现在需要将数据表的结构用ORM的语言描述出来,SQLAlchemy提供了一套Declarative系统来完成这个任务,比如这里我们需要创建一个userinfo表,看看它是怎么实现的:
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column,CHAR,Integer engine = create_engine(\'mysql+pymysql://root:LBLB1212@@@localhost:3306/db6?charset=utf8\',max_overflow=5) Base = declarative_base() class userinfo(Base): __tablename__ = \'userinfo\' id = Column(Integer,primary_key=True) #primary_key=True代表创建主键 username = Column(CHAR(20),nullable=False,index=True) #nullable=False代表不能为空,index=True代表创建索引 password = Column(CHAR(20),nullable=False) email = Column(CHAR(64),nullable=False,index=True) def init_db(): Base.metadata.create_all(engine) if __name__ == \'__main__\': init_db()
__tablename__指定表名,使用Column来创建列,可以在sqlalchemy中导入各种数据类型(CHAR,VARCHAR,Integer,String等),使用方法create_all创建文件中所有的表。在MySQL服务器上查看上面创建的表:
mysql> show create table userinfo \\G; *************************** 1. row *************************** Table: userinfo Create Table: CREATE TABLE `userinfo` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` char(20) NOT NULL, `password` char(20) NOT NULL, `email` char(64) NOT NULL, PRIMARY KEY (`id`), KEY `ix_userinfo_username` (`username`), KEY `ix_userinfo_email` (`email`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 1 row in set (0.00 sec)
本质上来说类相当于是表,类实例化后的对象相当于是数据行。
删除表使用:
Base.metadata.drop_all(engine)
数据行的增删改查操作
现在创建两个表,用户表(user)和用户类型(usertype)表:
from sqlalchemy import create_engine,ForeignKey from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column,CHAR,Integer engine = create_engine(\'mysql+pymysql://root:LBLB1212@@@localhost:3306/db6?charset=utf8\',max_overflow=5) Base = declarative_base() class Usertype(Base): __tablename__ = \'usertype\' type_id = Column(Integer, primary_key=True, autoincrement=True) type = Column(CHAR(20),nullable=False) class User(Base): __tablename__ = \'user\' id = Column(Integer,primary_key=True,autoincrement=True) username = Column(CHAR(20),nullable=False,index=True) password = Column(CHAR(20),nullable=False) user_type_id = Column(Integer,ForeignKey(\'usertype.type_id\')) #ForeignKey创建外键 def init_db(): Base.metadata.create_all(engine) def drop_db(): Base.metadata.drop_all(engine) if __name__ == \'__main__\': init_db()
执行之后,到数据库上查看是否已经创建:


mysql> desc user; +--------------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------------+----------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | username | char(20) | NO | MUL | NULL | | | password | char(20) | NO | | NULL | | | user_type_id | int(11) | YES | MUL | NULL | | +--------------+----------+------+-----+---------+----------------+ 4 rows in set (0.00 sec) mysql> desc usertype; +---------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------+----------+------+-----+---------+----------------+ | type_id | int(11) | NO | PRI | NULL | auto_increment | | type | char(20) | NO | | NULL | | +---------+----------+------+-----+---------+----------------+ 2 rows in set (0.00 sec)
在对数据表操作之前,这里必须要建立session:
from sqlalchemy.orm import sessionmaker Session = sessionmaker(bind=engine) session = Session()
1.新增操作
现在要向表中插入数据,上面说过实例化类就可以得到一个对象而这个对象也就是一个数据行:
#插入单个数据行 obj1=Usertype(type="普通用户") session.add(obj1) session.commit() #必须记得要提交
也可以使用下面的方法插入多个数据行:
objs = [ Usertype(type="超级用户"), Usertype(type="白金用户"), Usertype(type="黄金用户"), ] session.add_all(objs) session.commit()
再来在数据库上查看用户类型表:
mysql> select * from usertype; +---------+--------------+ | type_id | type | +---------+--------------+ | 1 | 普通用户 | | 2 | 超级用户 | | 3 | 白金用户 | | 4 | 黄金用户 | +---------+--------------+ 4 rows in set (0.02 sec)
最后在用户表中插入用户:
objs = [ User(username=\'frank\',password=\'111123\',user_type_id=2), User(username=\'rose\',password=\'312231\',user_type_id=1), User(username=\'jack\',password=\'112311\',user_type_id=1), User(username=\'tom\',password=\'123231\',user_type_id=3), User(username=\'jeff\',password=\'121213\',user_type_id=3), User(username=\'alex\',password=\'123323\',user_type_id=4), User(username=\'christ\',password=\'122123\',user_type_id=1), User(username=\'duke\',password=\'123111\',user_type_id=4), ] session.add_all(objs) session.commit()
2.查询操作
使用query()方法进行查询,先来看一下下面的例子:
res = session.query(User) print(res) #运行结果 SELECT user.id AS user_id, user.username AS user_username, user.password AS user_password, user.user_type_id AS user_user_type_id FROM user
根据以上例子会发现返回值为SQL语句,再来看一下下面的例子:
res = session.query(User).all() print(res) #运行结果 [<__main__.User object at 0x0000029777820400>, <__main__.User object at 0x0000029777820470>, <__main__.User object at 0x00000297778204E0>, <__main__.User object at 0x0000029777820550>, <__main__.User object at 0x00000297778205C0>, <__main__.User object at 0x0000029777820630>, <__main__.User object at 0x00000297778206A0>, <__main__.User object at 0x00000297777C1F98>]
返回的User的对象列表,这也就是每一个数据行,一个数据行对应一个User对象,可以使用fro循环遍历:
for row in res: print(row.id,row.username,row.password,row.user_type_id) #运行结果 1 frank 111123 2 2 rose 312231 1 3 jack 112311 1 4 tom 123231 3 5 jeff 121213 3 6 alex 123323 4 7 christ 122123 1 8 duke 123111 4
下面来看一下SQL中各种查询在SQLAlchemy是怎么实现的:
a.普通的条件查询
1.SQL中的多个条件查询 res = session.query(User).filter(User.id > 5,User.username == \'duke\').all() #使用filter,里面为条件表达式,默认多个表达式之间为与关系 print(res[0].id,res[0].username) #res ==> [<__main__.User object at 0x000002845B140668>] #运行结果 8 duke 2.SQL中的BETWEEN语句 res = session.query(User).filter(User.id.between(3,5)).all() for row in res: print(row.id,row.username,row.password,row.user_type_id) #运行结果 3 jack 112311 1 4 tom 123231 3 5 jeff 121213 3 3.SQL中的IN res = session.query(User).filter(User.id.in_([1,5])).all() for row in res: print(row.id,row.username,row.password,row.user_type_id) #运行结果 1 frank 111123 2 5 jeff 121213 3 #取反没在User前面加一个波浪号 res = session.query(User).filter(~User.id.in_([1,2,3,4,5])).all() for row in res: print(row.id,row.username,row.password,row.user_type_id) 4.子查询的3中类型 4.1类似SQL中select * from table_name where id in (select id from tablename where name=\'frank\') res = session.query(User).filter(User.id.in_(session.query(User.id).filter(User.username == \'frank\'))).all() print(res[0].username) #运行结果 frank 4.2类似SQL中select * from (select * from tablename where id >4) as B,相当于在临时表中查询 q1=session.query(User).filter(User.id>4).subquery() res = session.query(q1).all() print(res) #运行结果 [(5, \'jeff\', \'121213\', 3), (6, \'alex\', \'123323\', 4), (7, \'christ\', \'122123\', 1), (8, \'duke\', \'123111\', 4)] 4.3类似于SQL中的select id,(select type from usertype where usertype.type_id=user.user_type_id) from user where id > 5,子查询在select中 res = session.query(User.id,session.query(Usertype.type).filter(User.user_type_id==Usertype.type_id).as_scalar()).filter(User.id>5).all() print(res) #运行结果 [(6, \'黄金用户\'), (7, \'普通用户\'), (8, \'黄金用户\')] 5.默认情况下,多个条件之间是与关系,那么如何改成或呢? from sqlalchemy import or_,and_ res = session.query(User.id,User.username).filter (or_(User.id == 3, User.username ==\'frank\')).all() print(res) #运行结果 [(1, \'frank\'), (3, \'jack\')] 最后这里的filter也可以使用filter_by,但是里面表达式却不是判断的表达式: res = session.query(User.id,User.username).filter_by(username=\'frank\').all() print(res) #运行结果 [(1, \'frank\')]
b.通配符
SQL中的LIKE操作 1.%:代表任何数目任意字符,比如这里要查找名字中含有\'e\'字符的: res = session.query(User.id,User.username).filter(User.username.like(\'%e%\')).all() print(res) #运行结果 [(6, \'alex\'), (8, \'duke\'), (5, \'jeff\'), (2, \'rose\')] 2._:代表任意单个字符,比如这里要查找第二个字符为\'r\'的用户信息: res = session.query(User.id,User.username).filter(User.username.like(\'_r%\')).all() print(res) #运行结果 [(1, \'frank\')]
c.限制行数
SQL中的limit操作 res=session.query(User)[1:3] for row in res: print(row.id,row.username,row.password,row.user_type_id) #运行结果 2 rose 312231 1 3 jack 112311 1
d.排序
SQL中的排序操作 res = session.query(User.id,User.username).filter(User.id>4).order_by(User.id.desc()).all() print(res) res = session.query(User.id,User.username,User.user_type_id).filter(User.id>4).order_by(User.id.desc(),User.user_type_id.asc()).all() print(res) #运行结果 [(8, \'duke\'), (7, \'christ\'), (6, \'alex\'), (5, \'jeff\')] [(8, \'duke\', 4), (7, \'christ\', 1), (6, \'alex\', 4), (5, \'jeff\', 3)]
e.分组
在SQL中,可以使用很多的内置函数,在SQLAlchemy中可以使用以下方式使用内置函数 from sqlalchemy.sql import func 现在来看一下SQL中分组是怎么实现的: res = session.query(User.user_type_id,func.sum(User.id)).group_by(User.user_type_id).all() print(res) #运行结果 [(1, Decimal(\'12\')), (2, Decimal(\'1\')), (3, Decimal(\'9\')), (4, Decimal(\'14\'))] 使用having进行筛选 res = session.query(User.user_type_id,func.sum(User.id)).group_by(User.user_type_id).having(func.sum(User.id)>10).all() print(res) #运行结果 [(1, Decimal(\'12\')), (4, Decimal(\'14\'))]
f.连表
1.普通的连表 res = session.query(User.username,Usertype.type).filter(User.user_type_id == Usertype.type_id) print(res) #运行结果 SELECT user.username AS user_username, usertype.type AS usertype_type FROM user, usertype WHERE user.user_type_id = usertype.type_id 2.SQL的INNER方式连表 res = session.query(User).join(Usertype) print(res) #运行结果 SELECT user.id AS user_id, user.username AS user_username, user.password AS user_password, user.user_type_id AS user_user_type_id FROM user INNER JOIN usertype ON usertype.type_id = user.user_type_id 3.SQL的左连接(右连接直接将User和Usertype换个位置即可) res = session.query(User).join(Usertype,isouter=True) print(res) #运行结果 SELECT user.id AS user_id, user.username AS user_username, user.password AS user_password, user.user_type_id AS user_user_type_id FROM user LEFT OUTER JOIN usertype ON usertype.type_id = user.user_type_id
g.组合
SQL中的UNION 1.去重 q1 = session.query(User.id,User.user_type_id).filter(User.id>4) q2 = session.query(Usertype.type_id,Usertype.type).filter(Usertype.type_id<3) res = q1.union(q2).all() print(res) #运行结果 [(5, \'3\'), (6, \'4\'), (7, \'1\'), (8, \'4\'), (1, \'普通用户\'), (2, \'超级用户\')] 2.不去重 q1 = session.query(User.id,User.user_type_id).filter(User.id>4) q2 = session.query(Usertype.type_id,Usertype.type).filter(Usertype.type_id<3) res = q1.union_all(q2).all() print(res) #运行结果 [(5, \'3\'), (6, \'4\'), (7, \'1\'), (8, \'4\'), (1, \'普通用户\'), (2, \'超级用户\')]
3.删除操作
删除动作是基于查询操作的,例如删除用户ID为8的用户信息 res=session.query(User).filter(User.id == 8).delete() print(res) #返回1,代表有数据可删除 session.commit() #一定记得要commit,否则删除不会成功
在数据库上查看,已经被删除:
mysql> select * from user; +----+----------+----------+--------------+ | id | username | password | user_type_id | +----+----------+----------+--------------+ | 1 | frank | 111123 | 2 | | 2 | rose | 312231 | 1 | | 3 | jack | 112311 | 1 | | 4 | tom | 123231 | 3 | | 5 | jeff | 121213 | 3 | | 6 | alex | 123323 | 4 | | 7 | christ | 122123 | 1 | +----+----------+----------+--------------+ 7 rows in set (0.00 sec)
4.修改操作
1.直接修改条件筛选后的内容,如修改用户id为7的用户的用户类型为2 res = session.query(User).filter(User.id == 7).update({"user_type_id":2}) print(res) #返回1代表执行成功 session.commit() #记得commit 2.在字符串后拼接字符串 session.query(User).filter(User.id > 2).update({User.username: User.username + "GG"}, synchronize_session=False) session.commit() 3.累加数值 session.query(User).filter(User.id > 1).update({"user_type_id": User.user_type_id + 1}, synchronize_session="evaluate") synchronize_session=False,synchronize_session="evaluate"为固定用法
relationship建立关系
还是引用上面的两个类来阐述relationship的使用。
engine = create_engine(\'mysql+pymysql://root:LBLB1212@@@localhost:3306/db6?charset=utf8\',max_overflow=5) Base = declarative_base() class Usertype(Base): __tablename__ = \'usertype\' type_id = Column(Integer, primary_key=True, autoincrement=True) type = Column(CHAR(20),nullable=False) class User(Base): __tablename__ = \'user\' id = Column(Integer,primary_key=True,autoincrement=True) username = Column(CHAR(20),nullable=False,index=True) password = Column(CHAR(20),nullable=False) user_type_id = Column(Integer,ForeignKey(\'usertype.type_id\'))
如果想取得用户的用户名和用户类型,按照之前学过的,可以使用join操作来完成:
res = session.query(User.username,Usertype.type).join(Usertype,isouter=True).all() print(res) #运行结果 [(\'rose\', \'普通用户\'), (\'jack\', \'普通用户\'), (\'frank\', \'超级用户\'), (\'christ\', \'超级用户\'), (\'tom\', \'白金用户\'), (\'jeff\', \'白金用户\'), (\'alex\', \'黄金用户\')]
SQLAlchemy为用户提供了relationship方法,将两个表建立联系,使用方法如下:
from sqlalchemy.orm import sessionmaker,relationships #需要导入relationship class Usertype(Base): __tablename__ = \'usertype\' type_id = Column(Integer, primary_key=True, autoincrement=True) type = Column(CHAR(20),nullable=False) class User(Base): __tablename__ = \'user\' id = Column(Integer,primary_key=True,autoincrement=True) username = Column(CHAR(20),nullable=False,index=True) password = Column(CHAR(20),nullable=False) user_type_id = Column(Integer,ForeignKey(\'usertype.type_id\')) user_type = relationship("Usertype") #不会生成列,括号内为要建立关系的类名
现在User类下多了一个属性,来打印看一下是什么?
res = session.query(User).all() for row in res: print(row.username,row.user_type) #运行结果 frank <__main__.Usertype object at 0x0000022825C995C0> rose <__main__.Usertype object at 0x0000022825CB04E0> jack <__main__.Usertype object at 0x0000022825CB04E0> tom <__main__.Usertype object at 0x0000022825C99630> jeff <__main__.Usertype object at 0x0000022825C99630> alex <__main__.Usertype object at 0x0000022825C22FD0> christ <__main__.Usertype object at 0x0000022825CB04E0> duke <__main__.Usertype object at 0x0000022825C22FD0>
由上面的打印的结果可知,user_type为Usertype的对象,而Usertype的对象即表usertype的行,所以这里建立了relationship之后,可以直接在User对象中通过user_type属性获得指定用户的用户类型了,实现如下:
res = session.query(User).all() for row in res: print(row.username,row.user_type.type) #运行结果 frank 超级用户 rose 普通用户 jack 普通用户 tom 白金用户 jeff 白金用户 alex 黄金用户 christ 普通用户 duke 黄金用户
在上面的例子中,可以通过User对象获取其用户类型,但是不能通过Usertype对象获取用户的信息。下面举另外一个例子,获取不同类型用户下面的用户有哪些?
首先根据之前学的知识,可以使用子查询来实现:
res = session.query(Usertype) for row in res: print(row.type_id,row.type,session.query(User.username).filter(User.user_type_id == row.type_id).all()) #运行结果 1 普通用户 [(\'以上是关于ORM框架SQLAlchemy的使用的主要内容,如果未能解决你的问题,请参考以下文章